Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 3 Tips for Achieving AI-Ready Data at Scale from a Fortune 500 Data Leader


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Disclaimer: This conversation was held during Databricks Summit in June 2024. The data and AI landscape evolves quickly and does not necessarily include all the current innovations and advancements in the space. Despite this, the concepts, the perspectives, and best practices shared here still hold true.
Despite what the LinkedIn influencers will tell you, building useful AI applications takes more than a bunch of third-party data and an API call to ChatGPT.
The real value of AI lies in the data that feeds it. Behind every successful AI product is a series of purpose-built pipelines powered by rich datasets – and the tools, processes, and people that support them.
Monte Carlo CEO & co-founder Barr Moses recently sat down with Surekha Durvasula, AI leader and former CDO at Pilot Company, Kohl’s, and Walgreens Boots Alliance, to discuss what she’s seen as the biggest challenges when it comes to delivering reliable data for AI—and what it takes to achieve trusted, AI-ready data at scale.
Table of Contents
The GenAI conundrum: Thinking vs. doing vs. doing it right
Lots of data teams are thinking about building for AI—some are even experimenting with it. But, very few data teams have AI products in production.
Here in the early days of the AI hype, appetite for AI far outweighs the experience required to develop and productize it. And while the challenges may be similar to any other data product (governance, quality, design), the scale and complexity of the challenge is multiplied for AI.
From the volume of its inputs to the unpredictability of its outputs, AI isn’t a project to be taken lightly. So, when it comes to your MVP AI product, how can you deliver AI value out of the gate—and keep your company out of the headlines in the process?
For Surekha—a data leader with experience in production-ready AI—the answer is three-fold:
- Bring your business along
- Practice risk modeling on your use-cases
- And take your time getting data quality right
Let’s dive in.
1. Bring your business along for the ride
For Surekha, whose data journey has taken her from service-oriented platform developer to Fortune 500 CDO, understanding the business need is the first step to success—and that means bringing business leaders into the conversation early.
“A lot of people focus on the talent pool [of the data team], but getting SMEs to get involved with your efforts is critical,” Surkeha says.
Developing in a business vacuum can spell disaster for even the simplest data products—and production-ready AI is far from simple. Going beyond the data team to executives—like the Chief Information Security Officers (CISO), Chief Privacy Officer (CPO), or in the case of external products, even the customer success team—is critical to AI product success.
“It’s not that different from introducing a product into the market,” Surekha says. “What’s different is the speed in which you can make mistakes and how viral the story can go.”
She also recommends getting the right partners involved to execute the LLM product. Domain teams may be responsible for the inputs, outputs, and everything in between. Bringing them along will help your team make more informed decisions—and help domain teams feel a greater sense of ownership for the product’s operational success.
At the end of the day, GenAI is a team effort. And getting your business ducks in a row early might just save you a few bad headlines later.
2. Practice risk modeling your AI
Security and governance are two of the biggest factors in AI success.
For Surekha, risk modeling is a critical step for GenAI development to assess the risks involved in not only how the model is trained but how it’s used as well.
“Each company has a different amount of risk tolerance, and risk modeling is not necessarily always done on use cases. If you do [risk modeling on use cases], teams can spend more time designing the product, testing the product, getting SMEs involved, taking them through multiple quality assurance cycles, prompt variations, and more.”
Assessing your organization’s risk tolerance, especially that of the leadership team, can also help determine where to focus your early efforts. If risk tolerance is low, internal use cases are likely a better place to start than external products with a wider blast radius and more opportunity for reputational hazard.
3. Focus on data quality first
Speed and inexperience rarely result in a successful end product—and that goes double for AI. Throw in some data of dubious quality and you’ve got the recipe for a bonafide disaster.
“Don’t just hurry up to finish the product,” Surekha says. “There’s a lot of fun stuff that can be done on the GenAI side, but before that, even more has to be done on the data side.”
Surekha continues, “Your LLM product is only as good as the data that goes into training [your product]…Oftentimes, I don’t think data teams are taking data reliability, context, and semantics seriously enough.”
No matter how perfect your model, when it comes to AI—or any data product for that matter—garbage in will always deliver garbage out.
While monitoring and scoring the quality of outputs will certainly be a component of any successful AI strategy, it’s impossible to monitor every output at scale. That’s why it’s critical to get the inputs right.
“[GenAI is] not about the tool or the technology. It’s about the discipline of treating the data with respect, and treating your data as an enterprise asset and true differentiator.”
To ensure the data feeding your AI is getting attention from the right stakeholders, Surekha recommends including SMEs in prompt engineering and training. By bringing data owners and domain leaders into the training strategy, you’ll be able to define the right context data faster and hopefully avoid triggering hallucinations in production down the road.
“Make sure the prompts, fine-tuning, and training data are all reliable and trustworthy,” she says. “There’s a lot of bias in how we collect data. Make sure you’re aware of it and can account for it if something goes wrong.”
Anyone can use a public LLM. It’s how data teams leverage their first-party data within their GenAI development that will really set their AI products apart.
Taking the time to get your data quality right will go a long way toward protecting the integrity and safety of those AI products—and delivering demonstrable value for stakeholders along the way.
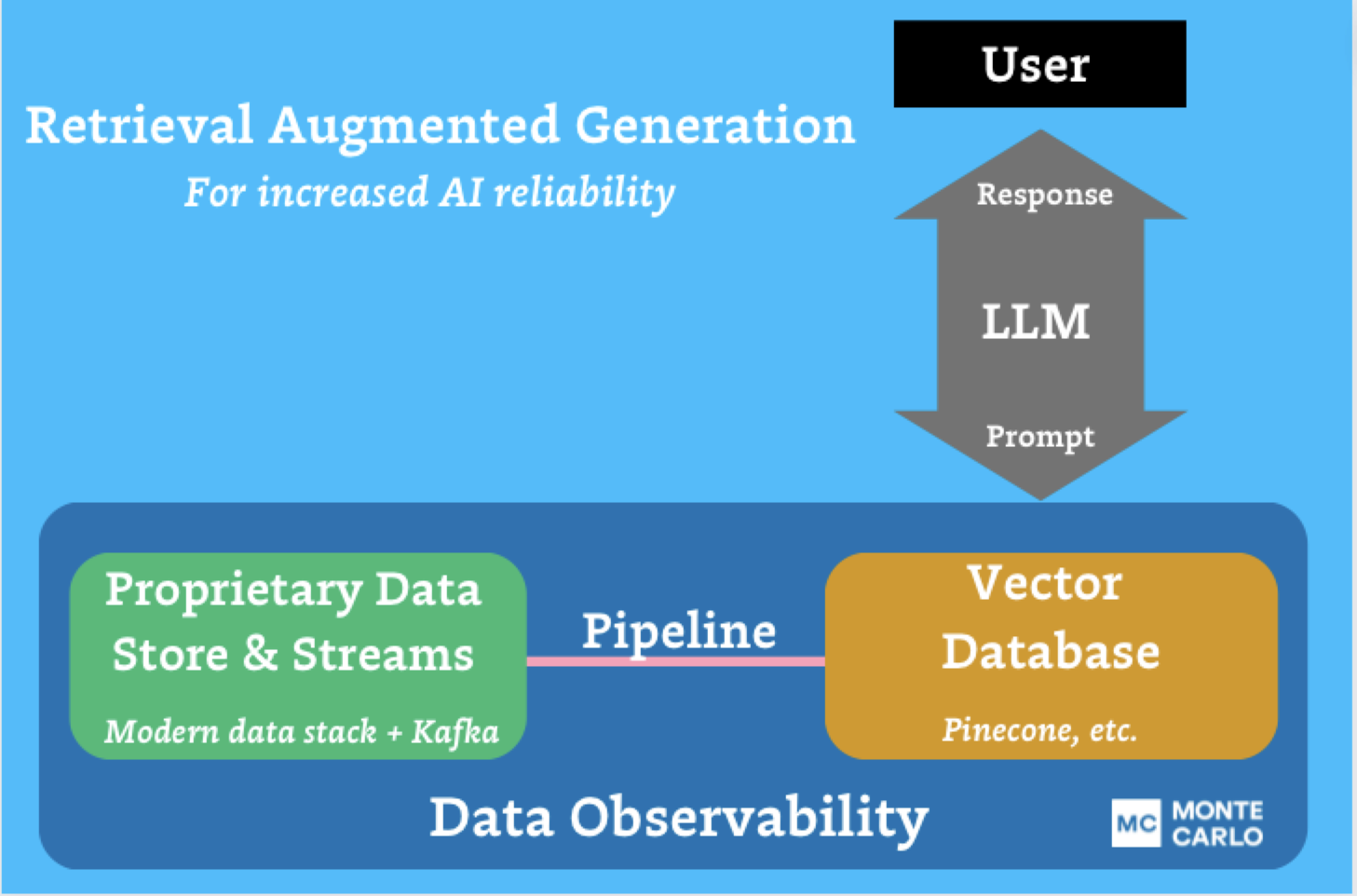
Data observability enables trusted GenAI
With these three best practices in mind, how can organizations best implement generative AI? Data observability enables each of these best practices to come to fruition; it’s the tool that enables organizations to move from simply “doing” generative AI to “doing it right.”
Data quality management is essential to creating valuable and trusted GenAI applications. But at the scale of AI development – and with the detrimental impacts that come from inaccurate data in AI models – traditional data quality monitoring and data testing simply aren’t enough. From a lack of scalability and coverage to limited support for incident management, traditional data quality solutions will never be able to detect all the ways data for AI can break—much less inform how you should respond to it.
Leveraging modern approaches like data observability that take an automated and end-to-end approach to ensuring data quality at scale—monitoring the data from ingestion to consumption and alerting, triaging, and resolving issues—is critical for managing AI performance at scale.
Data observability enables data teams to build trusted GenAI systems by automatically detecting and alerting teams to issues and causes. Data observability extends the benefits of traditional data quality solutions beyond the data into the system and code levels as well to understand immediately when an issue occurs, what was impacted, why it happened, and how to fix it—or if any of that matters in the first place.
As Surekha says, “data observability allows data teams to have a single pane of glass that puts data stakeholders at the very center… Once the data has landed, you can ask: How good is it at the attribute level? Does it statistically meet the needs or attributes the consumer was expecting? Does it meet the value the stewards needed it to?”
With data observability supporting the reliability of training and context data, data teams can deliver trustworthy AI that minimizes risk, maximizes value, and differentiates their products with AI. And, by informing the right stakeholders of a potential data issue at the moment it occurs—and providing the right context to respond appropriately—data observability can help data and AI teams reduce time-to-detection, minimize costs, and eliminate the chaos that typically comes with triaging and resolving data incidents in one fell swoop.
To learn more about how data observability can enable your organization to deliver reliable data for GenAI, schedule some time with our team in the link below.
Our promise: we will show you the product.
Read more posts.