Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 6 Things Every CDO Needs to Know About AI-Readiness

For anyone following the game, enterprise-ready AI needs more than a flashy model to deliver business value. According to Gartner, AI-ready data will be the biggest area for investment over the next 2-3 years.
Over the last several months, Gartner has shared several key illustrations to demonstrate how they perceive AI-readiness in 2025. And on the whole, I would say they’re pretty spot on. But I think there are a couple other issues that need to be addressed as well.
In this post, I’ll share the 6 things I believe every CDO needs to know to be truly AI-ready in 2025.
Table of Contents

1. You need to be in the cloud
I’m just going to call this point zero—you need to get to the cloud. I feel like that goes without saying at this point, but I know there are a few stalwarts out there who still believe that their bulky, expensive, and unwieldy on-prem platforms are the future of data management. And in some instances, that might be the case.
However, the majority of publicly available LLMs—not to mention the infrastructure that democratizes their usage/makes them accessible/powers them—are in the cloud. Sure, you can leverage open source, lash a few tools together, and run it all locally. But for the average enterprise team, running it all in the cloud with managed solutions is going to be infinitely more scalable—and far easier to maintain long term.
This gets down to your basic build versus buy questions. If you can get 95% of what you need in the cloud—and your use-cases, data sources, and security needs are relatively standard—leveraging a managed cloud-based solution will be significantly more cost-effective in the long run. And that’s saying nothing about the impact on your blood pressure.
So, yea. Get to the cloud. The water’s fine.
2. Your first-party data is your moat
If I’ve said it once, I’ve said it one hundred thousand times, LLMs are a commodity. That shouldn’t shock anyone who’s paying attention. DeepSeek AI proved it when they launched their first model and exceeded previous best-in-class benchmarks on a $6 million budget.
But the harsh reality is that large proprietary models were never going to be the value creator for enterprise AI in the first place.
Everyone has access to the latest and greatest models (or everyone who’s willing to pay $200/month if we’re talking about OpenAI). And if everyone has the same competitive advantage, no one does.
Like every data product—and make no mistake, genAI is a data product—the value of AI will forever and always be in the data used to augment it. A chatbot that knows how to find Africa isn’t helpful to your finance team. A chatbot that can retrieve, parse, and generate revenue projections based on existing sales is very helpful.
Anyone can create an API call to Gemini. But only you can infuse that model with value-driven gold. If you want to be successful in the AI arms race, prioritize the resources that will make you successful—get your first-party data AI-ready.
3. Semantics matter…a lot
It’s not enough to have an ocean of great first-party data. You need to make that data useful for AI. This isn’t just about making your data available — it’s also about making it understandable, both to your team and to the AI models that will leverage it.
Think of it like this: if you want your customer service chatbot to deliver more value than an FAQ page, it needs to know more than an FAQ page.
Identifying that “UserID 12345 has OrderID 67890,” is helpful. Identifying that “frequent flyer Mark is in the top 10% for individual tickets sales and recently experienced a flight delay” is powerful. And that kind of rich context only comes from properly modeled data with clear semantic meaning.
Without semantics, your cloud-based data is just symbols on a spreadsheet — raw tables and fields without context, meaning, or clear relationships. Building AI applications on top of this kind of data is like trying to have a conversation with your neighbor’s parrot—it might spit out a few words, but I doubt they’ll be appropriate.
Infusing semantic meaning involves defining your team’s data by documenting relationships between creator and context (like customers and their orders), establishing clear business definitions (what exactly counts as an “active user”?), and maintaining metadata about data freshness, quality, and lineage (more on that in a moment).
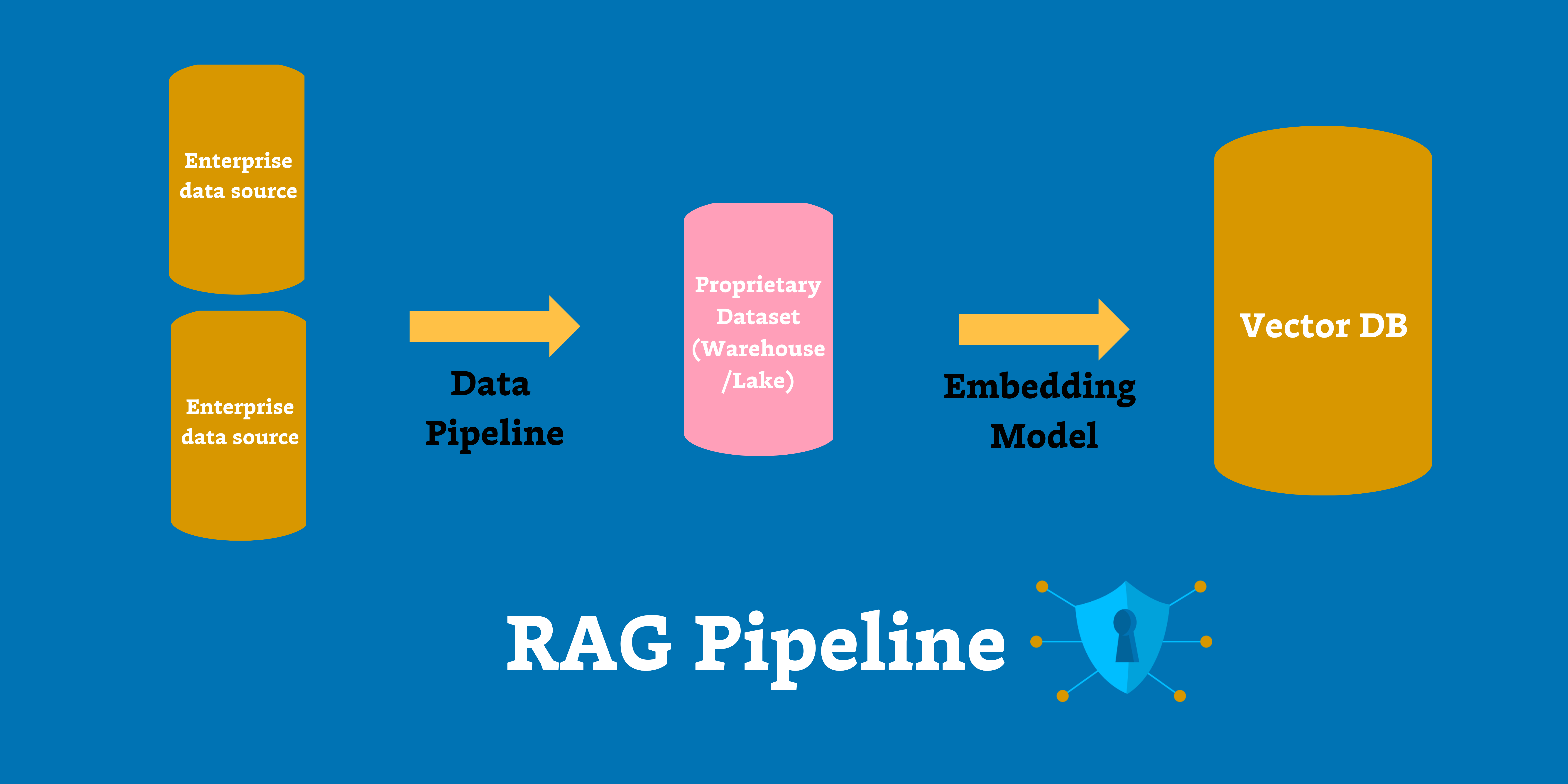
And in the case of AI, semantic meaning enables your AI to make accurate contextual connections during retrieval augmented generation (RAG) and fine-tuning.
Tools like in-platform catalogs or dbt’s aforementioned Copilot can all make it easier to derive value from your data by making it discoverable, understandable, or more functional for a given use-case.
4. AI is a security nightmare—govern it carefully
Even in the most traditional pipelines, you need a strong governance process to maintain output integrity. But AI is a different beast entirely. Generative responses are still largely a black box for most teams. We know how it works, but not necessarily how an independent output is generated.
Security and compliance is difficult enough when there’s a human in the loop. When we start talking about AI agents that can access sensitive records and act autonomously on a customer’s behalf…well now we’re cooking with a flame thrower.
Existential questions aside, the reputational and financial risk of an ungoverned AI application is a recipe for disaster. That means strict rules and standards are non-negotiable in a generative environment. This gets deep into the questions of safety and ethics, including understanding what data we’re using, under what circumstances it can be used safely, and what risks are associated with it.
For example, do we know where the data came from and how it was acquired? Are there any privacy issues with the data feeding a given model? Are we leveraging any personal data that puts individuals at undue risk of harm?
Is it safe to build on a closed-source LLM when you don’t know what data it’s been trained on?
And, as highlighted in the lawsuit filed by the New York Times against OpenAI — do we have the right to use any of this data in the first place?
Amongst the necessities here are properly profiling the data, defining rules and standards, and creating a culture that understands and embraces governance as part of the process.
Pro tip: consider leveraging a governance or quality tool that offers automated profiling to expedite the discovery process and validate SLA requirements.
5. Garbage (data) in, garbage (models) out
There are plenty of factors to consider in the suitability of data for AI—fitness, variety, semantic meaning—but all that work is meaningless if the data isn’t trustworthy to begin with. Garbage in always means garbage out—and it doesn’t really matter how the garbage gets made.
Even outside of complex RAG architectures—which often rely on dynamic, up-to-the-minute data—your data is going to break. And the more complex your pipelines become, the more problematic (and common) that’s going to be.
Poor data quality is a zero day risk and an absolute non-starter for production AI.
There’s a reason that data quality was the number one priority for CIOs according to a recent Info-Tech Research survey.
And the harsh reality is this—traditional data quality solutions lack the scalability or visibility required for AI. Even when your team’s handwritten SQL tests can tell you what broke, they still can’t tell you where, why it happened, or how to fix it (if it even matters in the first place).
That’s why you need a modern AI-ready data quality strategy. And that’s precisely why Gartner lists data observability as an essential component of the AI-ready data stack.
Defining data quality and governance for AI is about more than writing tests or triggering alerts. It’s about creating an effective incident management process to not only detect data quality issues, but also triage and resolve them faster at scale—and validate performance over time.
Modern data quality approaches like data observability combine fully automated monitoring and lineage, AI-powered recommendations, data profiling, and root cause analysis into a single centralized solution to help teams not just test their data but manage and improve data quality end-to-end. So, as your pipelines scale to meet the demands of new AI use-cases, a modern data quality approach will ensure that your data quality coverage scales with it.
Data observability solutions like Monte Carlo have even extended coverage to vector databases like Pinecone as well, a critical component for RAG pipelines in the modern AI stack.
6. You need to get even closer to the business
This one will be short and sweet. You can’t deliver value if you don’t know what your stakeholders need.
Now more than ever, identifying needs, curating data and solving real problems is the only path to broad cultural adoption of data + AI projects.
Even with all the most perfectly curated and validated AI-ready content, you won’t sway a single consumer to use your new GenAI application if it doesn’t solve a real problem for them.
The key to building useful data products (AI or otherwise) is understanding the needs and challenges of your business stakeholders.
What’s more, developing stakeholder relationships, anticipating the needs of your consumers, and proactively defining solutions to deliver new value is the one thing AI can never automate away. IF you want to make yourself indispensable—and deliver a ton of ROI for your data + AI projects in the process—you need to get serious about understanding your business.
AI-readiness is the new table stakes
If production-ready AI is your ambition in 2025, AI-readiness has to be your first, second, and third priorities.
Fortunately, the path to AI-readiness is the path to reliable data products writ large. A rising tide raises all ships—and AI is a tidal wave that’s coming for every enterprise organization in the next 12 months.
AI will be the catalyst for a socio-technical revolution the likes of which we’ve never seen in the data space—and I, for one, am here for it.
Our promise: we will show you the product.
Read more posts.