Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage A Data Engineer’s Guide to Building Reliable Systems
Over the years, I’ve helped companies of all sizes build and maintain data systems—from my days as a data engineer at Facebook to my current role as an end-to-end data solutions consultant. As a YouTuber and blogger, I’ve connected with data engineers from all over the world. And these days, everyone seems to share a common concern: how do we make sure the data we rely on to make all of our important business decisions is actually reliable?
My take? It’s never too early to start building reliability into your data system. Here’s what I’ve learned about starting slowly, knowing when to scale, and deciding to build versus buy.
Why data reliability matters now
I believe data reliability is more important than ever because we’re dealing with more: more data, more demand, more sources, more tools, and more hype than ever.
Big data isn’t just available to enterprise orgs or tech giants like Facebook anymore. Companies of all sizes are dealing with a plethora of data coming in from many sources, and they want to get that data in the hands of their teams. As more data tools become available, I’ve seen SMBs (think companies with $5-10 million in gross revenue) jumping in to set up Snowflake or Fivetran—mostly because that’s what all the buzzy articles about driving efficiency with data say they should do.
And since these tools are relatively easy to adopt, it doesn’t take long until these companies are pulling data into a warehouse and consider themselves off to the races.
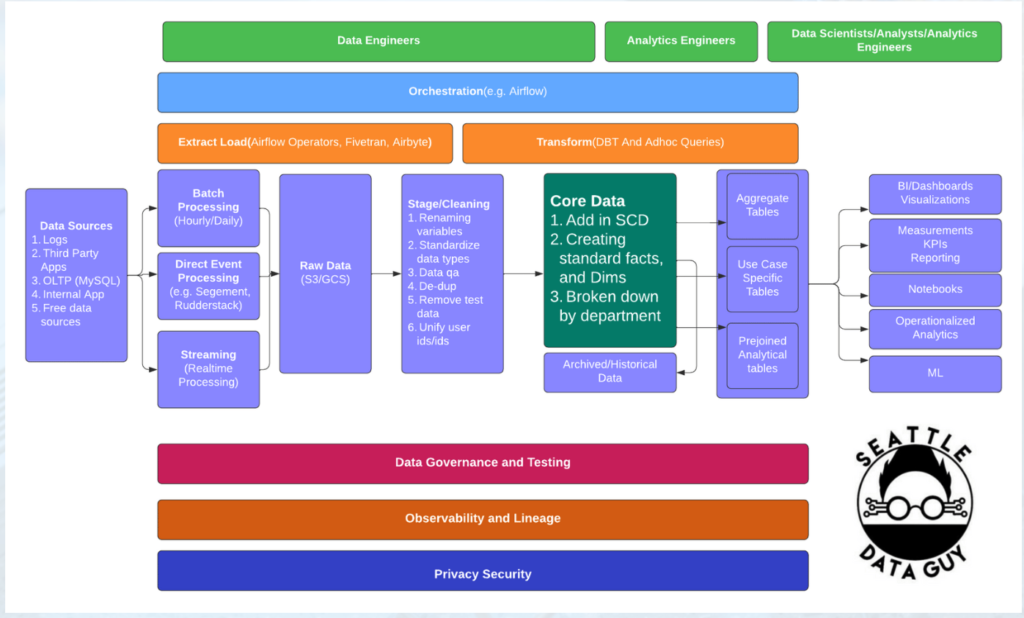
But, it really isn’t that simple—at least, not for long. More complex logic needs to be injected as more people get involved in your data system. And when you have more ways of pulling in data (like streaming and direct event processing), you end up with many more use cases that need to be supported. You may no longer just be supporting classic reporting, but trying to drive operational analytics or machine learning initiatives. You have more options about how to store and manage data in the cloud, and you need a fairly complex system to support all these different initiatives.
The stakes also get higher. When data is being used more widely, you find that your data has to be right. Data isn’t just populating a dashboard where someone will come back and tell you it’s wrong—it’s being actively used to make decisions, and there can be massive consequences if that data isn’t accurate.
How data fails—and what those failures cost
Recently, I was watching a mini-documentary on how nuclear meltdowns have happened. And the more I listened to it, the more it sounded like an interesting parallel to how what can occur when we build these complex data systems. In one example, the army was working on the SL1 mini nuclear reactor. And to maintain the nuclear reaction, their plan was to manually lift or lower the rods which would essentially decrease or increase the amount of activity happening inside the reactor. As you can imagine, from a scaling standpoint over time, this manual process eventually led to human error and things not going well.
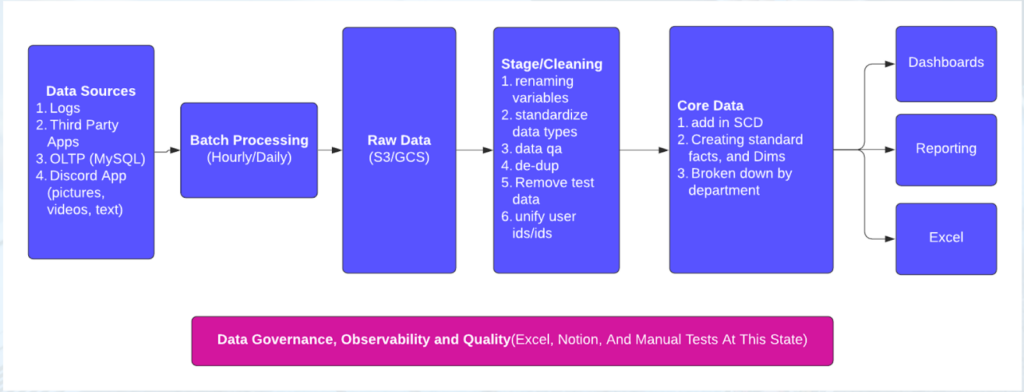
This is so congruent with what we do as data engineers. When I started doing quality checks at my first company, we would literally load data in, manually run data checks, then take the output and save it to Excel. And it was very slow, very ineffective, and obviously error-prone. The only thing that saved us was that we only had to load 20 to 30 data sets a month at that point. We could manage, for a while—because while these manual processes are a normal way to start, over time, they start to fail.
If you’ve worked in data a long time, the causes of these failures are probably very familiar: human error, poor documentation, cutting corners on maintenance, and lack of best practices. For example, I’ve seen two examples of double billing happen because of failed data. People use a combination of ways to calculate billing and inadvertently count transactions or events as occurring twice—then double-billed their clients for those inaccurate amounts. When the company comes back to contest that bill, it costs your company and your data team. It’s one thing to be embarrassed in a meeting because your internal numbers are inaccurate, but it’s a totally different discussion when a client is dealing with double billing.
Something similar happened to me recently with my Substack newsletter. For about three or four weeks, I was putting out newsletters and seeing twice as many views as I’d ever had. It was super exciting because I thought people were really interested in my content. So I adjusted my strategy to double down on covering a few specific topics that seemed to be performing so well. And then I saw a message from Substack that basically said they had just corrected a bug that was double-counting the number of views or email opens for their newsletter. I was disappointed—and about to make some misinformed decisions about my content strategy based on Substack’s internal bad data.
For me, it was just my newsletter. But for companies that are larger, bad data can impact million-dollar decisions, like whether to change a feature or invest in a new initiative. In both cases, it’s very easy to take information for granted and make bad decisions from it.
This is why data quality is so important, even from the earliest stages of building a data system. So let’s dive into how data engineers working at startups can build data reliability into your stack from day one.
Getting started with data reliability
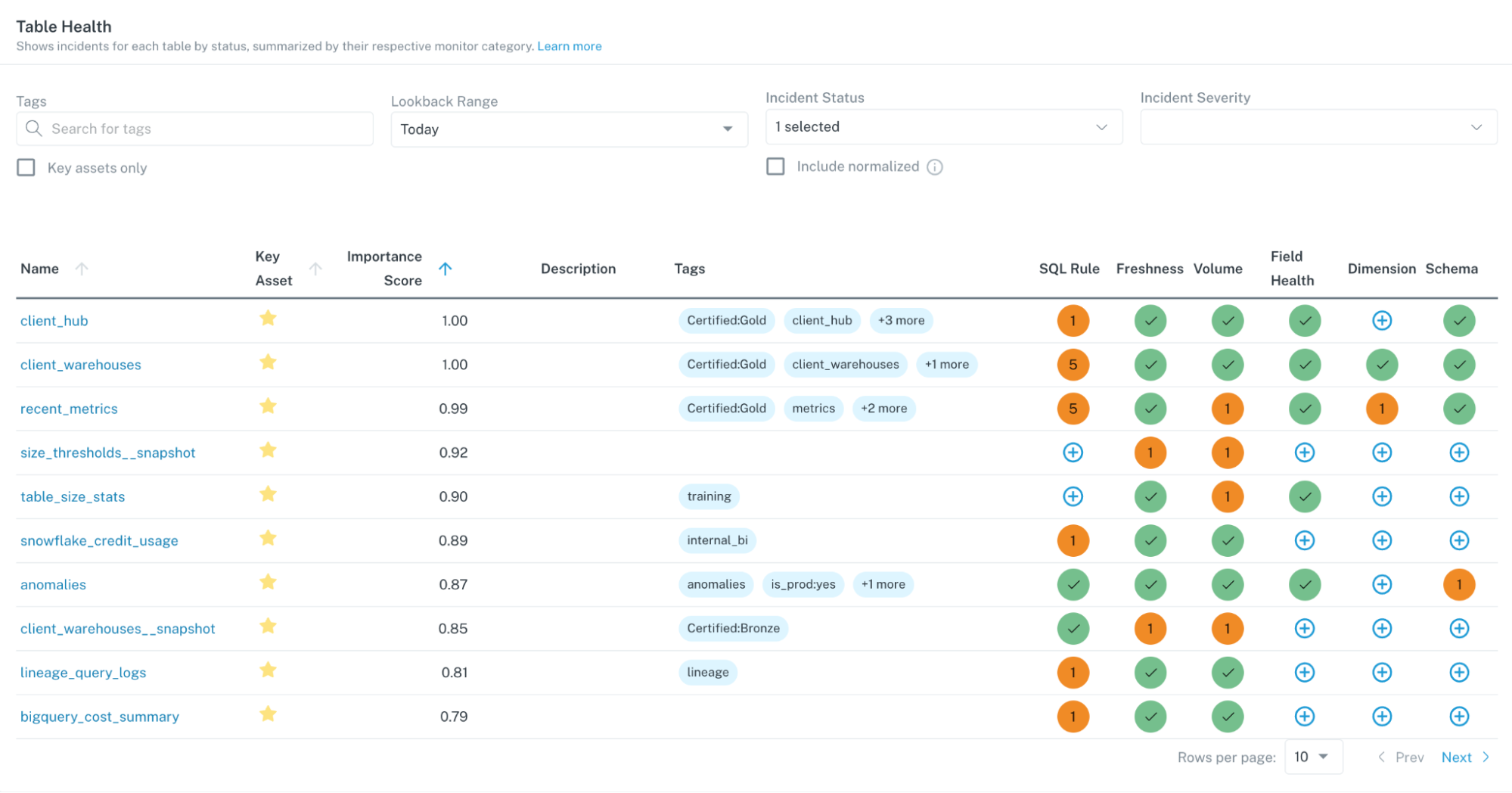
When I work with companies to start building data systems, we get the essentials covered: ingestion, storage, and baseline reporting. But then I also try to set up some form of data governance.
When you’re just starting out, manual processes are perfectly fine. It gives you ground to understand what’s important to your company, what you’ll actually want to check for, and where data quality checks belong within your processes.
I recommend starting with some basic sanity checks:
- Aggregation checks
- Category checks
- Range checks
- Duplicate data checks
- Anomaly checks
You may literally be asking simple questions like, “Is this field a date? Is this field a number?” to ensure your data types meet your expectations. For a range check, you might have a minimum and a maximum value that you set, and you’re looking to make sure you aren’t seeing more or fewer rows than you usually get for certain files.
As you create these early processes, you may start with running SQL checks manually—but eventually, you can build out configuration files that can become more automated and organize your results in a dashboard. Over time, you’ll grow to maintain and track a system that can tell you whether or not your data is accurate based on the rules and logic you’ve put into the data checks.
But, you’ll soon discover that data quality is more than just data checks. Your logic and code could be accurate according to your manually set standards, but data will still break.
This is because forces beyond your control can cause data to break, especially as your team gets bigger and your systems get more complex. When you’re working with multiple data systems that work together, there are many points where outages can happen: your ERP speaks to your CRM, you have multiple data warehouses, you have different ETL processes running at different times—and your baseline SQL checks aren’t going to provide coverage for all the issues that could occur.
When you’re at this point, signals will start to emerge: it’s time to consider a more robust approach to data reliability.
Signs it’s time to invest in observability
Here are a few signs that you’re ready to invest in data quality and data observability.
Testing can’t scale to catch your issues
By the end of my time at Facebook, I had around 1,000 data quality checks open at any given time. It was way too noisy, and I knew the people in charge of the source systems didn’t necessarily care about them. And since they didn’t care, I stopped paying close attention.
For detection and alerting to be useful at scale, you must know what needs to be prioritized and addressed quickly. And you have to track checks over time so that you can identify trends and not miss larger issues that might otherwise go unnoticed or ignored. That adds more complexity—now you have to build a dashboard and tables to track all of your checks—and eventually, you need more engineers to maintain all these different little systems that you’ve developed.
More fire drills and concerns from stakeholders
As your data systems grow more complex and data incidents inevitably happen, you’ll be hearing from your stakeholders. Slack messages, emails, or internal alerts will start to ping you when directors or managers realize that numbers are wrong or reports aren’t updating. Your team will start to spend more time responding to outages and less time building data products, and you’ll feel the need for more engineering resources to handle these concerns.
When these issues start to arise, you need a better solution. You can explore building some automated tools in-house, and developing processes around how to detect and respond when things go wrong. Or, you can hire more engineers to manage your manual data quality processes (although that’s usually too expensive for any but the biggest tech companies to do successfully). Finally, you can buy an out-of-the-box product that will address data observability holistically for you.
Your data team is growing
The good news is your organization values data, which means you are hiring more data folks and adopting modern tooling to your data stack. However, this often leads to changes in data team structures (from centralized to de-centralized), adoption of new processes, and knowledge with data sets living amongst a few early members of the data team.
If your data team is experiencing any of these problems, it’s a good time to invest in a proactive approach to maintain data quality. Otherwise, technical debt will slowly pile up over time, and your data team will invest a large amount of their time into cleaning up data issues.
For example, one of our customers was challenged by what we call the, “You’re Using That Table?!” problem. As data platforms scale, it becomes harder for data analysts to discern which tables are being actively managed vs. those that are obsolete.
It’s important to note that while a growing data team is a sign to invest in data quality, even a one-person data team can benefit greatly from more automated approaches.
You’ve recently migrated to the cloud
Whether your organization is in the process of migrating to a data lakehouse or between cloud warehouses (e.g., Amazon Redshift to Snowflake), maintaining data quality should be high on your data team’s list of things to do.
After all, you are likely migrating for one of three reasons:
- Your current data platform is outdated, and as a result, data reliability is low, and no one trusts the data.
- Your current platform cannot scale alongside your business nor support complex data needs without a ton of manual intervention.
- Your current platform is expensive to operate, and the new platform, when maintained properly, is cheaper.
Regardless of why you migrated, it’s essential to instill trust in your data platform while maintaining speed.
You should be spending more time building your data pipelines and less time writing tests to prevent issues from occurring.
What’s next?
Once you’re ready to start taking a more holistic approach to data quality, there are some key features that you’ll want for any data system to ensure reliability:
Automated checks and rules based on historical information about data patterns: Rather than relying on manually set thresholds and limits, good data observability tooling can look at the historical patterns of your data and set its own automated checks and rules.
Prioritized alerting directly to wherever your team works: Be able to cut through the noise and receive relevant, prioritized alerts about outages to Slack, Teams, or wherever your team is actively working.
Lineage: Having lineage for your data—a map of upstream and downstream dependencies—helps you understand the impact of data issues, proactively communicate to stakeholders, and troubleshoot faster.
The truth is, it’s easy to create a basic data quality system—but building one at scale gets more complex. I’m excited by the landscape for data observability tooling, though. Right now, it mirrors the rise of APMs like Datadog and New Relic for software engineering, and I think more companies will continue to invest in these automated platforms to ensure better data quality.
Ultimately, data observability is just one piece of the data stack puzzle, and one trend on my radar. Check out my YouTube channel—the Seattle Data Guy—to keep up to date with other new developments around data engineering and reliability.
Interested in learning more about the Monte Carlo data observability platform? Schedule a time to talk to us below!
Our promise: we will show you the product.
Read more posts.