Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Anomaly Detection: Why Your Data Team Is Just Not That Into It


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Delivering reliable data products doesn’t have to be so painful.
Here’s why and how some of the best data teams are turning to DevOps and Site Reliability Engineering for inspiration when it comes to achieving a proactive, iterative model for data trust. Introducing: the Data Reliability lifecycle.
Imagine for a moment that you’re a car mechanic.
A sedan drives into your garage, engine sputtering.
“What’s wrong?” You ask, lifting your eyes from your desk.
The driver rolls down their window. “Something’s wrong with my car,” they respond.
Very descriptive, you think, wiping the sweat from your brow. Your sarcasm makes you chuckle.
“Something is wrong with my car.” They repeat, this time without the contraction.
After a few hours of poking around, you figure out that the car has a loose spark plug. Sure, their lack of information isn’t the end of the world, but imagine how much quicker this process could have been if they had been proactive and said:
“I have trouble getting my engine to start, my car won’t accelerate, and my battery keeps dying.” Remember, you’re a mechanic. 🙂
What does this have to do with data, you ask? Well, on the surface, not much. But we can learn a thing or two from our friendly mechanic when it comes to building more reliable data systems.
Data quality: the reactive approach
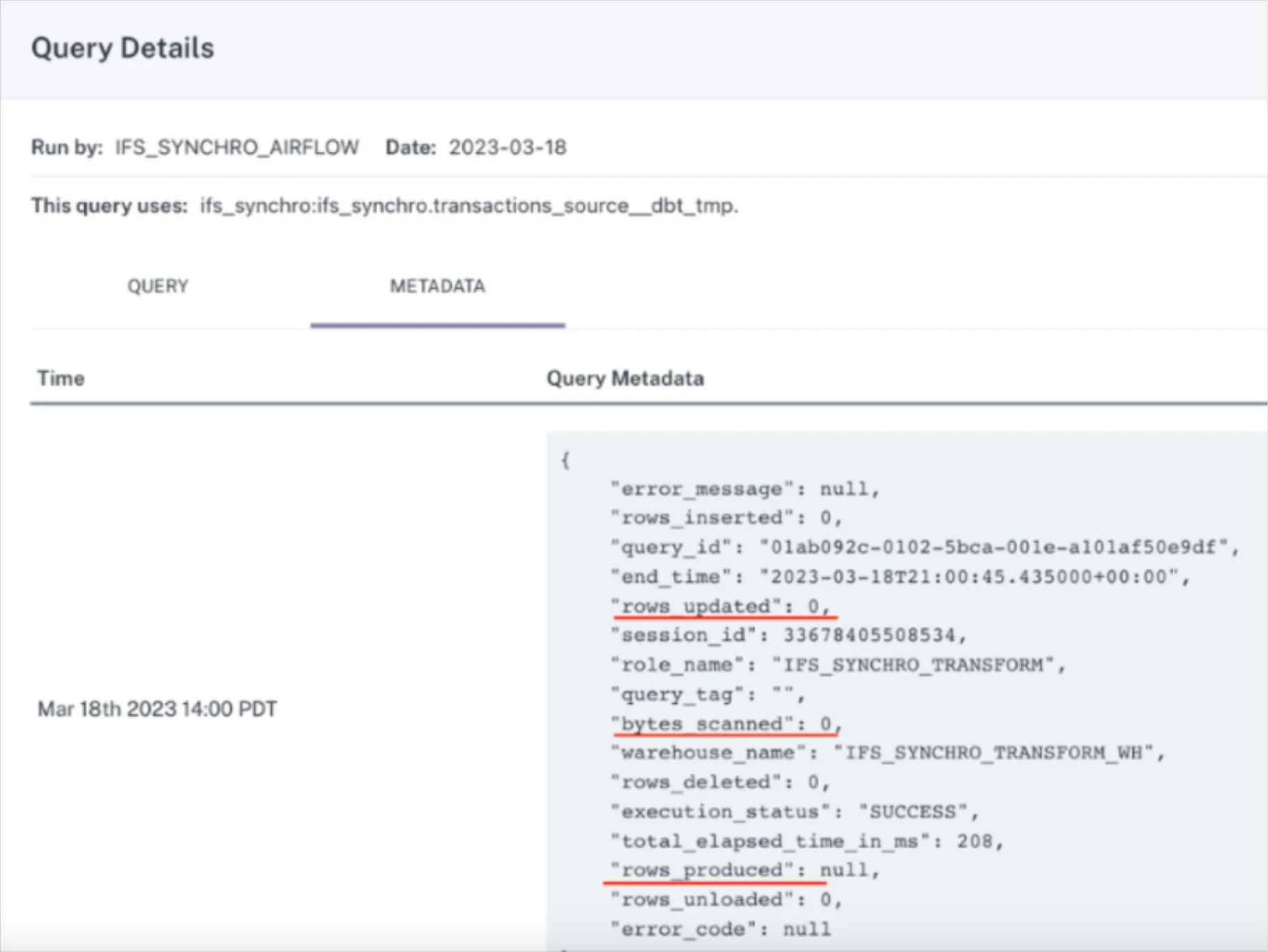
Nowadays, most data teams employ some measure of data anomaly detection to solve for data quality. Data Anomaly detection is great for organizations that are looking to identify when the key pillars of data health (i.e., volume, freshness, schema, and distribution) are not meeting an organization’s expectations in production. Moreover, data anomaly detection is extremely valuable to businesses when implemented end-to-end (such as across your data warehouse, lake, ETL, and BI tools), opposed to only living within one or two layers of your data platform.
Great, you know that your data broke. Now what?
As most data teams are learning, data anomaly detection alone is not cutting it when it comes to building the trust, accountability, and transparency demanded by insight-driven organizations.
Recently, I was having (virtual) coffee with the VP of Analytics at a Fortune 500 software company who summarized this problem almost too perfectly.
“I want things that are tied to impact so I can take action on them,” he said. “Data anomaly detection is necessary as a starting point, but we need to do a lot more work to understand the root cause and assess the impact. Knowing there’s a problem is great, but it’s really hard to understand what to do with it. Instead, we need to understand exactly what broke, who’s impacted by it, why and where it broke, and what the root cause might be. Data anomaly detection alone just isn’t that interesting to me.”
Clearly, we need a better way to understand and proactively improve the health of our data. Fortunately, modern data teams need to look no further than our DevOps and Site Reliability Engineering counterparts for inspiration in the DevOps lifecycle.
What is data anomaly detection?
A critical component of data observability is data anomaly detection, or the ability to identify when pillars of data health (i.e., volume, freshness, schema, and distribution) veer from the norm. Data anomaly detection is valuable for organizations when implemented end-to-end (across your warehouse, lakes, ETL, and BI tools) instead of only in a specific layer of your data ecosystem. When data anomaly detection is implemented end-to-end, data teams gain a complete picture of their organization’s data health, so your team is the first to know and resolve when data breaks.
What is the DevOps lifecycle?
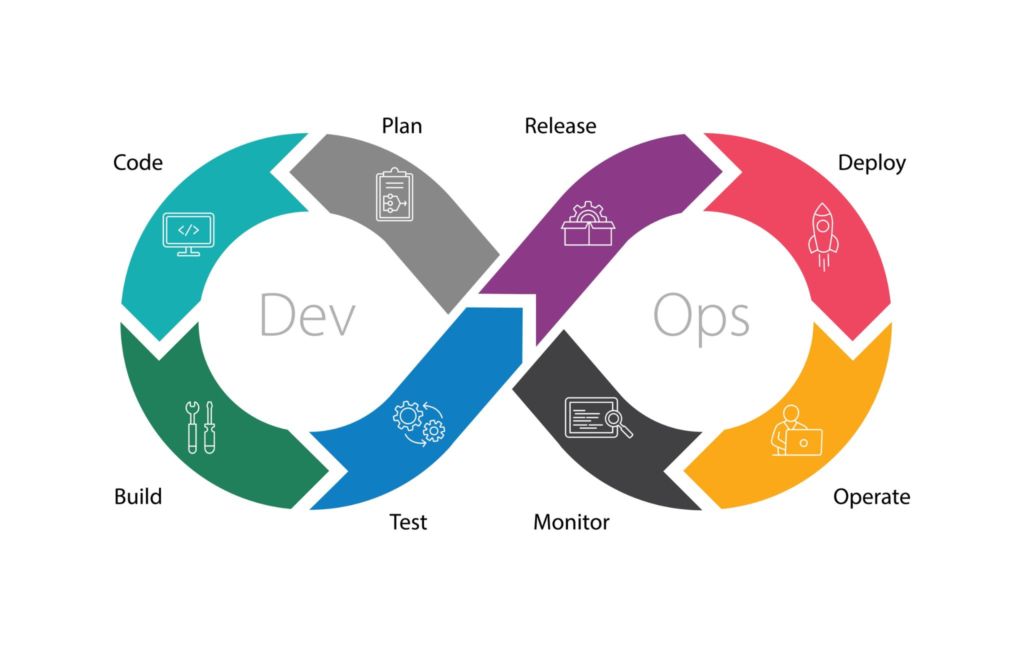
Developer Operations (DevOps) teams have become an integral component of most engineering organizations, breaking down silos between software and infrastructure teams. To facilitate quicker development of code and its underlying architecture, DevOps teams apply a feedback loop, called the DevOps lifecycle, that helps teams reliably deliver features aligned with business objectives at scale.
The DevOps lifecycle incorporates 8 distinctions, continuous stages, including:
- Planning: Partner with product and business teams to understand the goals and SLAs for your software.
- Development: Write the software.
- Integration: Integrate the software with your existing applications.
- Testing: Test your software.
- Release: Release your software into a test environment.
- Deployment: Deploy your software into production.
- Operate: Run the software, adjust as necessary.
- Monitor: Monitor and alert for issues in the software.
And the cycle repeats itself. While many of our data technologies and frameworks (i.e., data testing, data SLAs, distributed architectures, etc.) have adapted to meet the standards and best practices set by our software engineering counterparts, our tendency to handle data quality reactively has prevented us from driving change for the business in a meaningful and scalable way.
Introducing the Data Reliability lifecycle
Much in the same way that DevOps applies a continuous feedback loop to improving software, I think it’s time we leveraged the same blanket of diligence for data.
The Data Reliability lifecycle, an organization-wide approach to continuously and proactively improving data health, eliminates data downtime by applying best practices of DevOps to data pipelines.
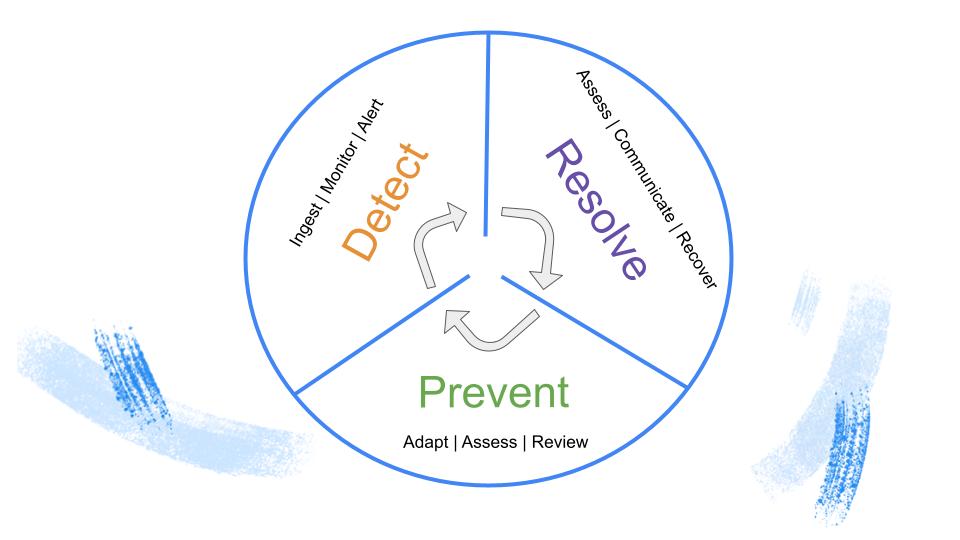
This framework allows data teams to:
- Be the first to know about data quality issues in production.
- Fully understand the impact of the issue.
- Fully understand where the data broke.
- Take action to fix the issue.
- Collect learnings so over time you can prevent issues from occurring again.
Here’s how:
Detect
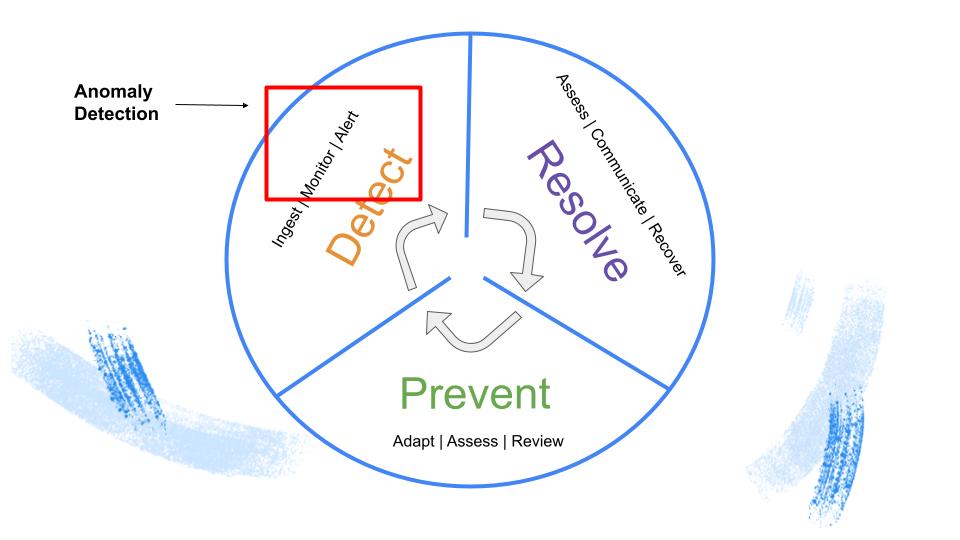
After you’ve tested your data and ingested it into production, it’s paramount that you monitor and alert for anomalies in your pipeline, in other words, detect if and when data issues occur. Data anomaly detection is a significant, albeit primarily reactive, part of this strategy.
Automated monitoring and alerting for freshness, volume, and distribution-based issues will help keep tabs on your data reliability SLAs and SLIs, and when you don’t meet them, ensure you’re the first to know. As data pipelines become increasingly complex, data is bound to break at one point or another, and being able to reduce the time to detection (TTD) is crucial for data-driven businesses.
Resolve
The second phase of the Data Reliability lifecycle, Resolve, entails that you assess the impact of your broken data on your larger data ecosystem and corresponding data products, as well as communicate the issue downstream to those who need to know. Ideally, the entire impact analysis process would be centralized, with corresponding alerts grouped and tagged appropriately.
In this part of the cycle, end-to-end lineage and statistical analysis can be used to understand the root cause of the problem at hand. As teams become adept at understanding, triaging, and responding to incidents, they can reduce the time to resolution (TTR) for common or expected data incidents.
Prevent
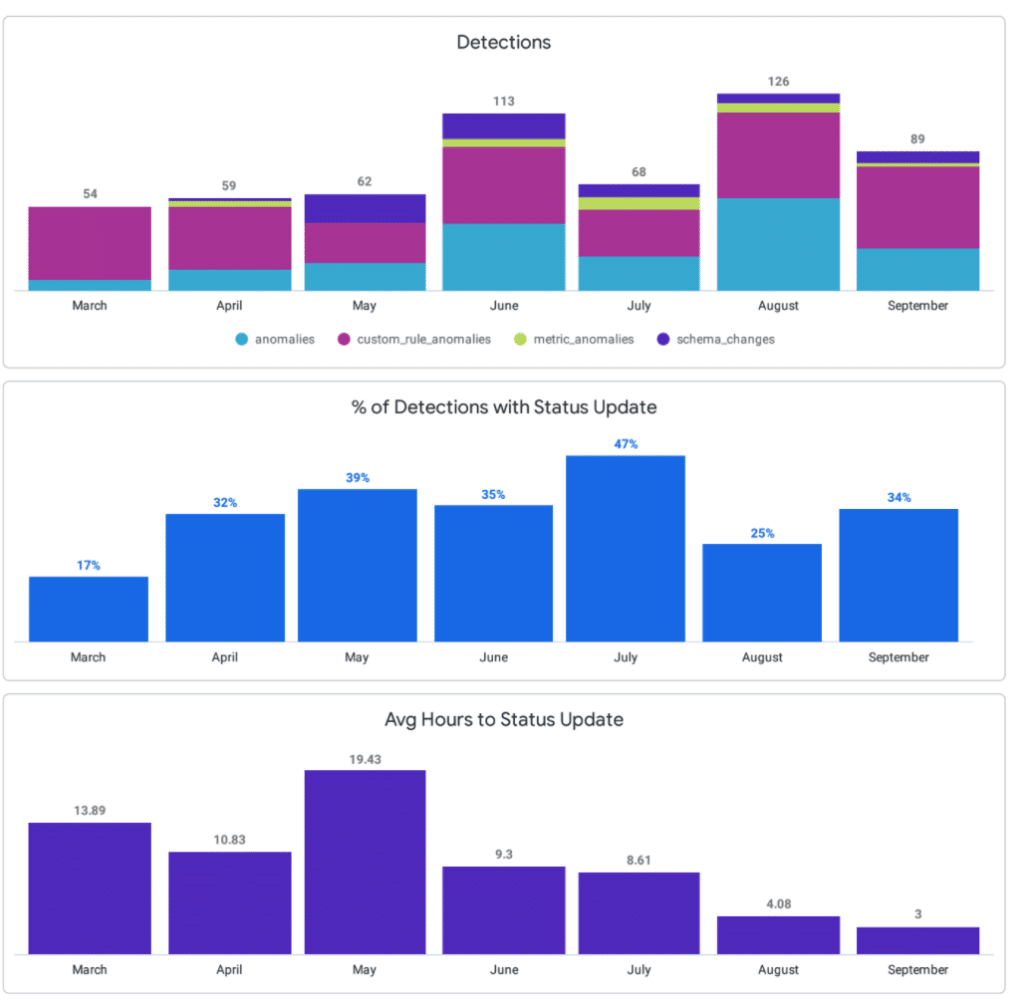
The Prevent phase of the Data Reliability lifecycle processes your prior learnings and historical information about your data pipelines and translates them into actionable, preventative steps. For instance, not every schema change your engineers’ company makes to existing data sets means that your pipelines are on fire; in fact, schema updates often signify development and progress. Still, without proper context, the Detect phase of your Data Reliability lifecycle (in other words, data anomaly detection), will not be able to pick up these queues.
By applying the Data Reliability lifecycle, teams should be able to surface logs, metadata, and queries about your data to gauge and even predict data health. More advanced lifecycles should also be able to automatically adjust and update tests and monitors to match evolving business logic, and in turn, reduce data downtime.
The future of data quality is proactive
Mechanics and software engineers aren’t the only ones who benefit from taking a proactive, iterative approach to their craft.
By applying similar principles of DevOps, data teams can better collaborate to identify, resolve, and even prevent data quality issues from occurring in the first place. In the coming months, I’m excited to see how this approach evolves, and in turn, how data systems mature to become more resilient and reliable.
And next time you see your mechanic: thank her. You have no idea what she’s been through!
Interested in learning more about the Data Reliability lifecycle? Reach out to Barr Moses and book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.