Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 17 Super Valuable Automated Data Lineage Use Cases With Examples
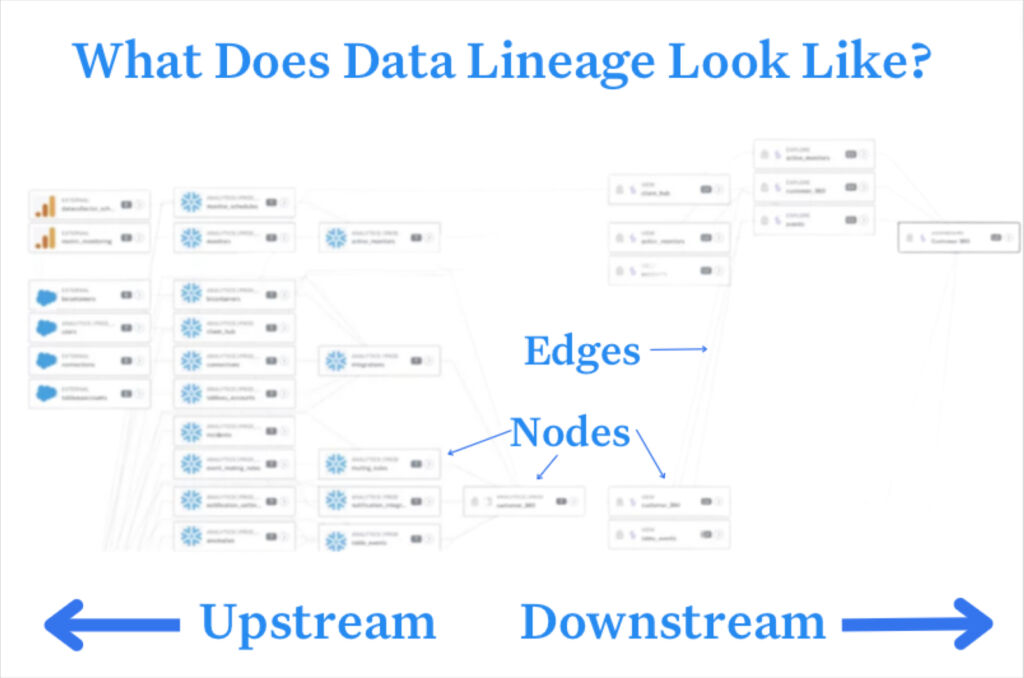
Data lineage is a visual diagram showing how data flows through your ETL pipeline from ingestion to consumption. Solutions with automated data lineage capabilities constantly update these graphs and illustrate them as nodes and edges, or in other words, the objects through which the data travels and the relationship between them.
While not every automated data lineage solution is the same, important nodes include:
- The connectors or syncs that ingest the data
- Tables within a data warehouse or lakehouse that store the data
- The BI and analytical dashboards that visualize the data
And each of these nodes can contain metadata about:
- The orchestration jobs that schedule key tasks
- The transformation models and SQL queries that move data from one table to another
- The profile of each field (NULL%, min, max, type, etc)
- Recent users who have queried or manipulated the data
- The users who access and consume the data in each dashboard
- Added documentation
- Past data quality incidents
- And more
It’s great to have such granular and powerful information at your fingertips in an easily consumed format, but the question is how do you make best use of it? What are the data lineage use cases and best practices that will drive value for the business?
We’re glad you asked. Here is a list of 17 valuable data lineage use cases that can help improve data quality, incident management, democratization, system modernization, and compliance.
Table of Contents
- Data Quality
- Data Incident Management and Response
- Data access and enablement
- Data System Modernization And Team Reorganization
- Data Governance and Compliance
- Knowledge Is Power (as is automated data lineage)
Data Quality
Data lineage is essential to improving and maintaining data quality across a modern data stack. Why? Data is bigger and faster, but it’s also messier and less governed. You can’t ensure the quality of something you don’t understand. Here are three examples of data quality related data lineage use cases.
Preventing (or recovering from) unexpected schema changes
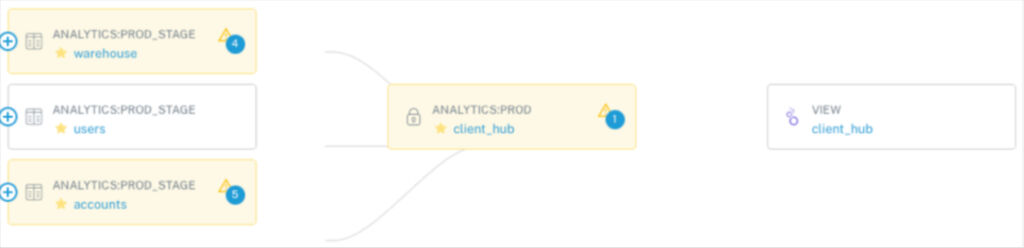
In the data lineage graph above, the Looker dashboard client_hub on the far right is downstream of the table client_hub, which is downstream of the tables warehouse, users, and accounts.
If, for example, I’m planning to change the invoice_amount field in the accounts table from a number to varchar, I have visibility into how that could break transformations or logic that may impact the client_hub table and Looker dashboard. I can surface ownership metadata and alert the relevant owners to make sure the appropriate changes are made so these breakages never happen.
In a recent blog post on how to handle a schema change, we detailed how Marion Rybnikar, the Senior Director of Data Strategy & Governance for Slice, a data-driven company that empowers over 18,000 independent pizzerias with modern tooling, uses data lineage for communicating and properly managing schema changes.
“Schema changes are flagged to us through a channel and we perform an impact analysis on behalf of the business, where we look at upstream and downstream consequences. Then at that point we provide approvals to different parts of the organization or manage subsequent change,” she said.
“For example, if someone is going to make a change that is going to break something, we would project manage to make sure that those changes are all implemented before the next stage occurs.”
Validate data
It works in the other direction as well. Let’s say I’m a data analyst reviewing data within the client_hub dashboard. I’m not going to blindly pass on any reports to key executives and business stakeholders until I’ve validated the data provenance and have confidence in its accuracy.
With data lineage, I can look upstream and ensure no one made the “You’re Using THAT table?!” mistake and that the data is flowing from the correct tables and sources. If I’m really detail oriented, I can double click and look into the queries being run to ensure they reflect relevant business logic. If the data lineage is part of a data observability platform, I can look to verify that none of the tables upstream are currently experiencing any issues. And in this case, I can see that client_hub, warehouse, and accounts are experiencing 1, 4, and 5 rule branches respectively.
Prioritize data reliability efforts
Data teams that take a “boil the ocean” approach to data quality will be stretched too thin, ultimately failing in their task. For example, your ability to ingest data is virtually limitless, but your capacity to document it is not.
Data lineage can help teams determine and focus their maintenance efforts on their key assets–calculated based on the number of queries and dashboard consumers downstream. For data teams that already know their key assets or data products, data lineage can help highlight the dependencies upstream that should be maintained at just as high a level.
Automated data lineage has helped SeatGeek prioritize their data quality efforts to greatly reduce their number of incidents.
“One of the things that [data lineage] has done is enable us to stabilize our platform. So, in addition to identifying when there is a problem, it has also helped us to understand where problems are likely to occur, where things are brittle. And over time, we’ve invested effort into cleaning up our lineages, simplifying our logic,” said SeatGeek Director of Data Engineering, Brian London.
Simplify SQL queries
When data power users like data analysts or data scientists can’t find what they need in the data warehouse, they recreate the wheel…usually with a long, brittle SQL query or series of dbt models. Data lineage can help people find the direct line to what they need to simplify these components and increase reliability as was the case with ecommerce company Resident.
“We had complicated queries, many duplications, inconsistent logic—it was quite a mess…We would base our strategy on memory, a few basic tools, and a lot of hope and help from our analysts or colleagues,” said Daniel Rimon, Head of Data Engineering at Resident. “[Now] It takes me nothing to maintain this lineage. If I want some advanced monitoring, I can define that, but nothing is required for me to get this level of lineage. It’s the dream.”
Data Incident Management and Response
These use cases could have been filed under data quality as data incident management and response is a core component of any data quality management program. The goal is to reduce data downtime, which means reducing the average time to detection and the average time to response. Here are four data lineage use cases that can help.
Impact analysis and triage
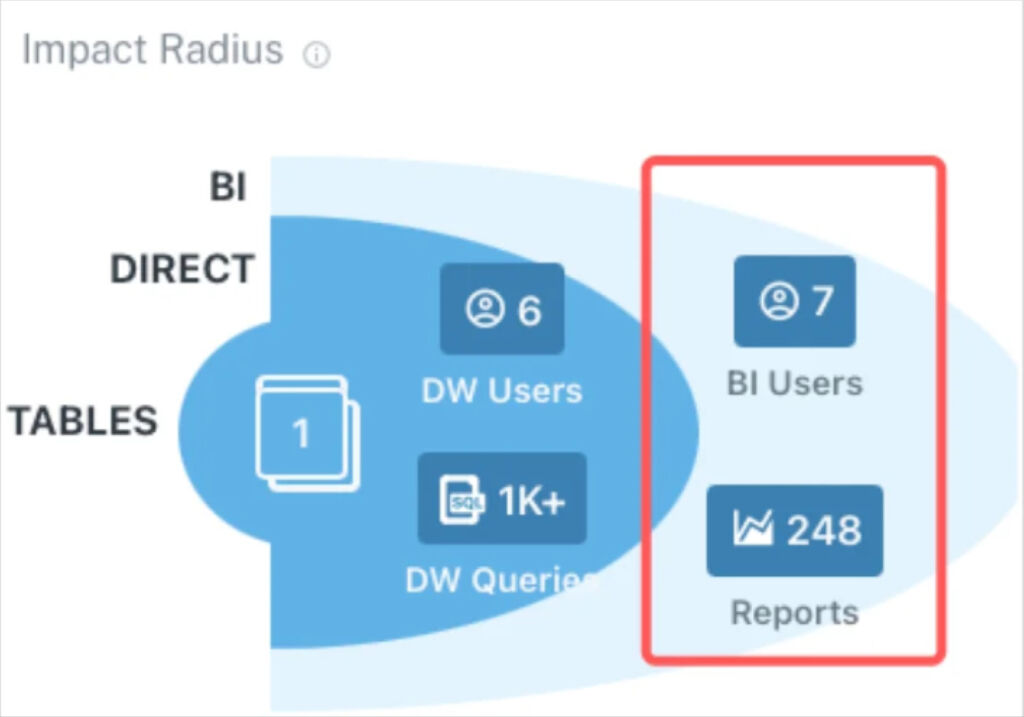
Let’s face it, not every data incident is of equal importance. Overwhelmed data engineers need to have the proper context of the blast radius to understand which incidents need to be addressed right away, and which incidents are a secondary priority.
Automated data lineage illustrates how a data freshness incident, for example, can cascade downstream to tables accessed by data warehouse and business intelligence (BI) users. This is one of the most frequent data lineage use cases leveraged by Vox.
“Lineage is by far my most favorite feature of Monte Carlo,” said Senior Product Manager Vanna Triue. “If something does break for whatever reason, you can see how it impacts things across the life cycle review. So, whether it’s closer to the warehouse or all the way through to your dbt models or your analytics systems, you can see how breakages impact all the parts of your data stack.”
Root cause analysis
When data engineers are alerted to an incident, it’s just the beginning of what can be a long, drawn out root cause analysis process. Our survey of 300 data professionals showed an average of 9 hours to resolve an incident once it was detected.
That’s because the table where the incident is detected rarely contains the context of its own downtime. Data lineage greatly accelerates root cause analysis by providing data traceability and allowing data engineers to track the incident to the table furthest upstream that is impacted.
This is perhaps one of the most common data quality related data lineage use cases and one leveraged by Farmer’s Dog.
“Monte Carlo has been exceptional at catching upstream errors,” said Rick Saporta, then Head of Data Strategy and Insights at Farmer’s Dog. “And being able to tell you that something is amiss and guide your focus with such precision! Pointing not only to the specific table but the lineage that quickly gets you to the root of the error. It’s just absolutely incredible.”
Combat alert fatigue with the bigger picture
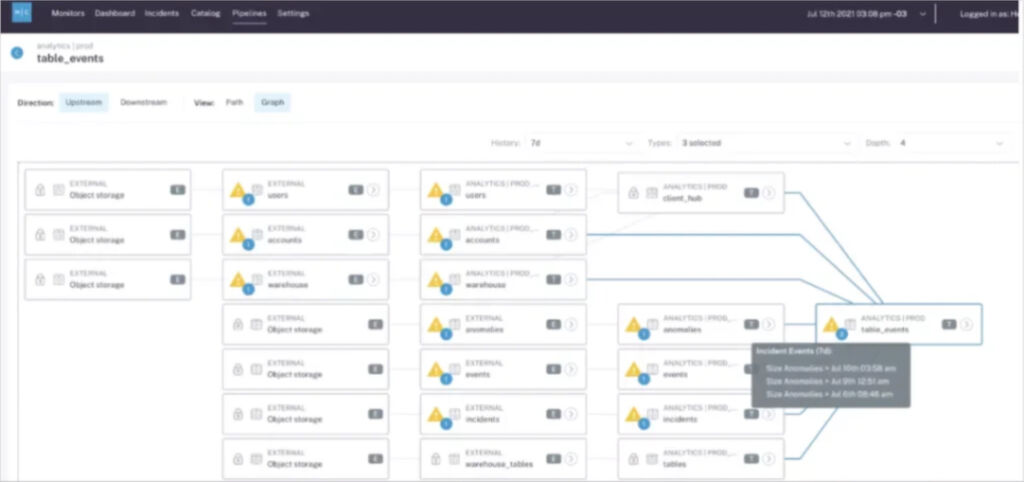
This is another use case that will only be relevant for situations where your data lineage provider and data quality solution are one in the same.
Imagine you have an issue with a table upstream that cascades into multiple other tables across several downstream layers as is the case in the image above. Do you want your team to get one alert or do you want to get 15 – all for the same incident?
The first option accurately depicts the full context along with a natural point to start your root cause analysis. The second option is akin to receiving 15 pages of a book out of order and hoping your on-call data engineer is able to piece together they are all part of a single story.
Not to mention, too many superfluous alerts is the quickest route to alert fatigue–scientifically defined as the point where the data engineer rolls their eyes, shakes their head, and moves on to another task.
Another way to help combat alert fatigue and improve incident detection is to set alert parameters to only notify you about anomalies with your most important tables. However, without native data lineage, it’s difficult and time consuming to understand what assets truly are important.
Smart incident alerting and routing
One of the keys to operationalizing automated data lineage along with incident management and response is to ensure alerts are routed to the right responders–those who best understand the domain and particular systems in question. Data lineage can help surface and route alerts to the appropriate owners on both data team and business stakeholder sides of the house.
This is similar to how Freshly leveraged data lineage to understand the downstream impact and proactively alert relevant data consumers.
“With data lineage we can understand when a table busted, who it’s going to impact and proactively alert them that a report is not up to date and that we’re working on a solution. This way no decisions get made on bad data and our team becomes a proactive part of the solution,” said then Senior Director of Data at Freshly, Vitaly Lilich.
Data access and enablement
Data lineage is essential to data quality, but that is far from its only use case. It is also a powerful data management tool for building data driven cultures within organizations. After all, it won’t matter how much you open access to your data environment if your users are trying to navigate a murky data swamp! Here are four data lineage use cases for data access and enablement.
Data discovery and exploration
When it comes to empowering your business users, data discovery and exploration tooling is key. But what happens when a reliable data exploration tool isn’t available? No data catalogs. No data dictionaries.
You could tell your business users to write a SELECT TOP 5 query to explore the tables and find a few fields they can use. Or you could leverage column level data lineage.
With a robust data lineage tool, analysts can easily review the upstream tables and sources for critical dashboards to develop an understanding of which fields and tables are most relevant for their analyses—information like what fields are being updated and which transformations generated the table.
“Our data analyst uses Monte Carlo’s lineage almost every day,” said Dylan Hughes, Senior Software Engineer at Prefect.
Data sharing and collaboration within the organization
One of the biggest bottlenecks for business users is knowing who to talk to when they encounter an issue. With column level data lineage, business users and analysts can easily identify upstream sources for fields they intend to use and who to contact if they need support.
While table lineage might reveal a few upstream tales and field dependencies, column level lineage will pinpoint the singular field in the singular table that impacts the one data point in your report. This significantly narrows the scope of your analysis.
Reducing data debt
If you are opening up SQL access as part of a data democratization or self-service analytics effort, it’s helpful to have a clean, well organized data repository. That means removing unused dashboards, tables, and columns. Not only are they unnecessary clutter, you never know when a well meaning analyst or business user will somehow pull data from accounts_deprecated.
This is one of the data lineage use cases deployed by Dr. Squatch.
“The whole team is trying to build new things and I’m trying to prune them. I like being able to go into lineage and in a singular, unified view see if a table is useful. Previously I would have had to look at the DAG, go into dbt, and then go into Looker and see what tables are referencing this model table. I love lineage” said Dr. Squatch VP of Data, IT & Security, Nick Johnson. “The clean up suggestions are great too. It’s just easy validation. You can clean things faster that way and it’s a good guardrail for knowing what not to delete.”
Data integration and modeling
In previous eras, data models like Data Vault were used to manually create full visibility into data lineage. However, it can work the other way as well.
Data lineage can help in the development of enterprise data modeling for data teams that want or need to go the extra mile to ensure their warehouse is an accurate digital reflection of how key events and entities interact in the real world.
Not only does data lineage provide a clear understanding of how data flows across different sources, it can help ensure the model’s accuracy and consistency by ensuring any changes are tracked and documented.
Data System Modernization And Team Reorganization
The only constant in data engineering is change. That means, even though you just migrated databases or changed the org chart, chances are you will be doing both again in the near future. It’s likely your data architecture will evolve significantly over the course of your career.
The good news is data lineage can help with change management and make this a more seamless process next time around. Here are three data lineage use cases for modernization and reorganization.
Data warehouse (or lakehouse) migration
Interested in how to launch a successful data warehouse migration? Data lineage can help!
If you have a decent amount of data with a high change rate, you will likely need to set up multiple waves with subsequent incremental migrations or a CDC to catch any changes and regressions introduced by the migration early.
So how should you group your migration waves? Some of the most common approaches are to migrate by domain or to migrate the highest value data first. However, it makes no sense to migrate a table and not the table upstream on which it depends. This is where data lineage can help you scope and plan your migration waves.
Data lineage can also help if you are specifically looking to migrate to Snowflake like a boss.
Unlike other data warehouses or data storage repositories, Snowflake does not support partitions or indexes. Instead, Snowflake automatically divides large tables into micro-partitions, which are used to calculate statistics about the value ranges each column contains. These insights then determine which parts of your data set you actually need to run your query.
For most practitioners, this paradigm shift from indexes to micro-partitions really shouldn’t be an issue (in fact, many people choose to migrate to Snowflake because this approach reduces query latency). Still, if you have partitions and indexes in your current ecosystem and are migrating to “clustering” models, you need a sound approach. A few tips for a safe migration using data lineage:
- Document current data schema and lineage. This will be important for when you have to cross-reference your old data ecosystem with your new one.
- Analyze your current schema and lineage. Next, determine if this structure and its corresponding upstream sources and downstream consumers make sense for how you’ll be using the data once it’s migrated to Snowflake.
- Select appropriate cluster keys. This will ensure the best query performance for your team’s access patterns.
Bidding adieu to partitions and indexes is nothing to lose sleep over as long as you have visibility into your data.
Transitioning to a data mesh (or other organizational structure)
Sometimes it isn’t the data that moves, but the people. One of the hottest trends in data right now is the implementation of data mesh, a socio-technical concept that involves decentralizing the data team and embedding members within each business department or domain.
Moving toward a domain-first, data-as-a-product mindset can be difficult, and even more so without clear lineage from dataset to domain owner. Good thing then that online carpool network Blablacar had access to data lineage as part of their data mesh transition.
“When we decided we’re moving to a data mesh, the first thing we did was define our business domains and to do that we used Monte Carlo’s data lineage feature which helped us understand the dependencies,” said BlaBlaCar Data Engineering and BI Manager, Kineret Kimhi. “It helped untangle the spaghetti and understand what’s going on across over 10,000 tables, which would have been impossible to do manually.”
Establishing clear lines of ownership
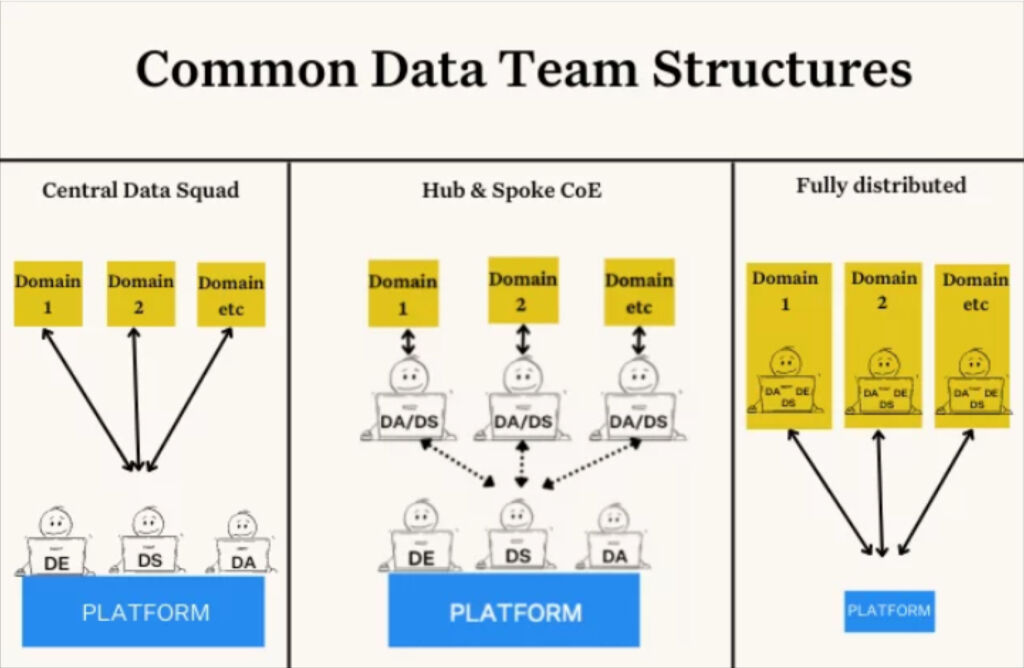
Data product ownership and accountability is something that every member of the data team agrees to in principle, but is more difficult to enact in practice. As the first two subsections highlight, data and people are constantly shifting. Data lineage helps ensure you have clear lines of accountability that data team structure–centralized, center of excellence, data mesh– you use or however your data pipelines evolve.
Data Governance and Compliance
The only things propagating faster than data are data regulations. It’s hard to keep up with regulatory requirements at the region (GDPR), country (Privacy Act), and even state (CCPA) level. The good news is these regulations largely focus on protecting sensitive information with strong governance best practices– which are use cases data lineage can support well.
Personally identifiable information (PII)
Let’s say your company has received a data subject access request “right to access” as part of GDPR Article 15 and a “right to be forgotten” request as detailed in GDPR Article 17. By law, you must provide all the information you have collected on that individual and erase it “without undue delay,” which is lawyer speak for about a month.
Is there someone on your team that intuitively knows every source and every table that contains the column lead_name? Are you willing to risk a fine of up to 4% of the company’s annual income on that? The better bet, of course, is data lineage.
Data audits
“Audits are fun!” said no data professional ever. To prove you were a responsible steward of regulated data, you will need to do an audit trail provide a list of everyone who had access to the data and the justification for that access. Data lineage is a helpful complementary piece to the other data privacy and data security tools and processes involved in this process.
This is similar to the data lineage use case leveraged by Prefect.
“We’re going to be leaning heavily on Monte Carlo for a lot of that lineage information to make sure that we’re focusing on the datasets that are used most, and understanding where that data is going. We want to make sure that once everything is classified, the folks who are actually seeing things on the downstream dashboards are the folks that we want based on our classifications,” said Dylan Hughes, Senior Software Engineer at Prefect.
Knowledge Is Power (as is automated data lineage)
In medieval times, maps were a source of great power and only accessible to the kings of the day who had the resources to fund the explorers and expeditions required to chart them. Today, data lineage maps are no less powerful, but you no longer need to marshal the resources of a kingdom to access them.
Let us show you what data observability and data lineage can do by signing up for a demo using the form below.
Our promise: we will show you the product.
Read more posts.