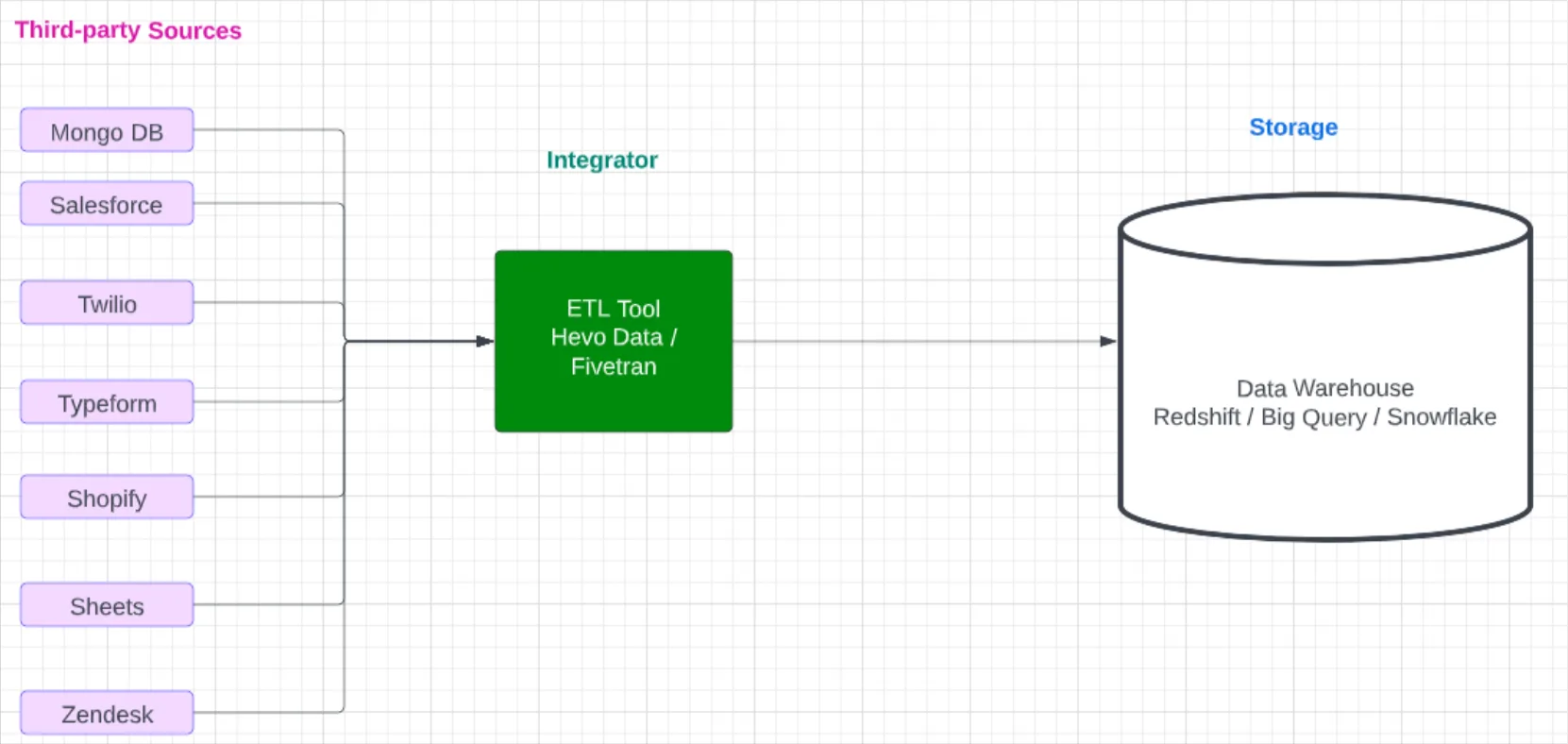
Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Big Data London Guide: 2024 Edition


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Another Big Data London is right around the corner, and we couldn’t be more excited.
Coming in hot on September 18-19, Big Data London is easily the UK’s biggest data event of the year. And with an event as rare and prestigious as Big Data London, it’s normal to want to maximize your time.
That’s why we put together our list of the top things to see and do at Big Data London this year—including the data reliability sessions we’re most excited about and the after-parties you don’t want to miss.
If you’re read to get in the Big Data London spirit, click that bookmark tab and let’s get started.
(PS, be sure to book a meeting with our team at the event to find out what’s happening with Monte Carlo and pick up some new swag!)
Table of Contents
Wednesday, 18 September
PrimaryBid’s Data Evolution: Ensuring Data Reliability when Expanding Globally
15:20 – 15:50
A new addition to the session line-up this year is the Dataops and Data Observability Theatre. For teams looking to tackle the data quality crisis head-on, this theatre will feature thought leadership and best practice sessions from some of the world’s most innovative data teams. One such session is this talk on protecting data quality during global expansion with PrimaryBid.
PrimaryBid, a UK-based technology business which connects retail investors to capital market transactions, is no stranger to working within a highly regulated, complex industry. As the team prepares for a global expansion beyond Europe and into the US and Middle East, they’re planning for even higher stakes as they increase the scale of their operations and external data products.
During the talk, you’ll hear from PrimaryBid’s Director of Data & AI, Andy Turner, as he shares PrimaryBid’s data journey, including how they rebuilt their data stack from the ground up to ensure accurate, reliable data across global markets, the value (and challenges) of delivering external data products, and how data observability has played a crucial role throughout PrimaryBid’s expansion.
How To Get Fired by Ignoring AI Governance
14:00 – 14:30
Perhaps a bit on the nose, but it needed to be said. Data quality and governance is the problem to solve data and AI teams. And, for those that don’t, the consequences often aren’t far behind.
Featuring Jovita Tam—a business-focused data/AI advisor/engineer and dual-qualified attorney (England & Wales, New York)— “How to get fired by ignoring AI Governance” is specifically designed for CDOs and CDAOs to understand the zero-day risks posed by AI if we aren’t careful to manage reliability and security.
Starting with an overview of the current global regulatory landscape—with a focus on the EU AI Act—this talk will delve into potential impact, actionable takeaways, and strategic questions.
Beers with Data Peers Afterparty
No conference is complete without a few after parties, and Big Data London will be no exception. After a busy first day, a few beers will certainly be in order. And that’s exactly what you can expect at the Beers with Data Peers Afterparty event.
Located at the Albion Olympia pub, just a quick 5 minutes walk from the main event, this networking event will give you a chance to wind down with a couple pints and continue the conversation with some of Europe’s best and brightest in the data space.
Thursday, 19 September
How Skyscanner Enables Practical Data and AI Governance at Scale
12:40 – 13:10
From its founding in 2023, Skyscanner has leveraged analytical data to optimise business and traveler experiences. And with more than 110 million monthly users resulting in 30+ billion analytical data events per day, Skyscanner is an expert at managing data at scale.
In this session, Michael Ewins, Director of Engineering at Skyscanner, will share how his team develops and executes data strategies centered on their core principles of data reliability, trust, and rapid data-driven decision making.
Michael will dive into the challenges his team faces navigating complex lineage and his team’s strategies for effectively combating data incidents—as well as how they simplified their analytics infrastructure to improve data governance management and some wins in AI and ML.
People > Tools: How to Stop Wasting Powerful Tech with Bad Processes
15:20 – 15:50
When it comes to finance and banking, there are big risks for bad data. From financial impact to reputational catastrophe, financial institutions are on the hook to get their data quality strategies right.
But new data quality tooling alone does not a strategy make. A true data quality strategy is a mix of both tooling and process—and that’s a mix Capital on Tap has been hard at work to master.
Join Ben Jones and Soren Rehn from Capital on Tap to hear why their Analytics Engineering team decided to invest in a data observability tool, how their processes play a critical role in maximizing the tool’s value (including a few missteps and recalibrations along the way), and the strategies they employed to operationalize their tooling and inspire adoption over time.
Building a Reliable Data Platform with Monte Carlo and Snowflake
15:30-15:50
Sometimes the most helpful sessions are the ones that are really hands-on examples of tools in action – and this session hits that mark.
Thomas Milner, Director of Engineering at Tenable, will dive deep into how his team built a reliable data platform with Monte Carlo and Snowflake. He’ll share how the reasoning behind their decisions, the processes they built, and how data observability works for their team.
Scaling Reliable Data Products and Data Mesh with Data Observability
16:00 – 16:30
No architecture over the last five years has garnered more buzz than the data mesh. But talking about it is easier than finding a team that’s doing it well—unless you’re talking about a team like Roche.
As one of the world’s largest biotech companies and a leading provider of in-vitro diagnostics, Roche has a lot riding on their data. Over the past few years, their data ecosystem has undergone a massive transformation—from their migration to a new cloud infrastructure to the implementation of an industry-leading data mesh that could improve data reliability.
During this session, the team at Roche will be sharing how they’ve leveraged data observability to support their sociotechnical shift to data mesh, including a walk through their multi-year data observability journey and how they’re using their data mesh today.
Our promise: we will show you the product.
Read more posts.