Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Managing Big Data Quality And 4 Reasons To Go Smaller

When it comes to big data quality, bigger data isn’t always better data. But at times we are guilty of forgetting this.
At some point in the last two decades, the size of our data became inextricably linked to our ego. The bigger the better.
We watched enviously as FAANG companies talked about optimizing hundreds of petabyes in their data lakes or data warehouses.
We imagined what it would be like to manage big data quality at that scale. We started humblebragging at conferences, like weight lifters talking about their bench press, about the size of our stack as a shorthand to convey the mastery of our craft.
For the vast majority of organizations, the reality is sheer size doesn’t matter. At the end of the day, managing big data quality is all about building the stack (and collecting the data) that’s right for your company – and there’s no one-size-fits all solution.
Here’s what I mean…

For managing big data quality, it’s no longer “go big or go home”
That may be a controversial thing to say when “big” has prefaced “data” in the label describing one of the predominant tech trends of our time. However, big data has always been defined beyond volume. For those that have forgotten, there are four other v’s: variety, velocity, value, veracity.
Volume has reigned supreme at the forefront of the data engineer’s psyche because, in the pre-Snowflake/AWS/Databricks era, the ability to store and process large volumes of data was seen as the primary architectural obstacle to business value.
The old big data quality paradigm held you needed to collect as much data as possible (it’s the new oil!) and build an architecture of corresponding scale. All of this data would rattle around as data scientists would use machine learning magic to glean previously inconceivable correlations and business insights from what were thought to be unrelated data sets.
Volume and value were one and the same. After all, who knew what data would be valuable for the machine learning black box?
I have yet to talk to a data leader with a modern, cloud-based data stack that has cited lack of storage or compute as the primary obstacle to achieving their mission. Nor have they told me about the amazing things their team would do, “if only they could collect more data.”
If anything, inflating tables and terabytes may reveal a lack of organization, a potential for increased data incidents, and a challenge to overall performance. In other words, data teams may find themselves accumulating data volume at the expense of value, veracity, and velocity.
This may be why Gartner predicts that by 2025, 70% of organizations will shift their focus from big to small and wide data.
To be clear, I know there are some organizations that are solving very hard big data quality problems related to streaming large amounts of data.
But those are specialized use cases, and while the demand for streaming data poses new big data challenges on the horizon, today most organizations enjoy a technological moment in time where they can cost effectively access enough storage and compute to meet their organization’s needs without breaking a sweat.
Here are a few reasons why you should encourage your team to shift from a big (volume) data mindset and make your big data small(er).
- For managing big data quality, it’s no longer “go big or go home”
- Data is becoming productized
- Machine learning is less data hungry
- Collection is easy, documentation and discovery are hard
- You’ve got data debt
- Big isn’t bad, but it’s not necessarily a good thing either
Data is becoming productized
With the emerging modern data stack and concepts like the data mesh, what we have discovered is that data is not at its best when it’s rattling around unstructured and unorganized until a central data team prepares an ad-hoc snapshot deliverable or insight to business stakeholders.
More data doesn’t simply translate into more or better decisions, in fact it can have the opposite effect. To be data driven, domains across the business need access to meaningful near-real time data that fits seamlessly within their workflows.
This has resulted in a shift in the data delivery process that looks an awful lot like shipping a product. Requirements need to be gathered; features iterated; self-service enabled, SLAs established, and support provided.
Whether the end result is a weekly report, dashboard, or embedded in a customer facing application, data products require a level of polish and data curation that is antithetical to unorganized sprawl.
Virtually every data team has a layer of data professionals (often analytics engineers) who are tasked with processing raw data into forms that can be interpreted by the business. Your ability to pipe data is virtually limitless, but you are constrained by the capacity of humans to make it sustainably meaningful.
In this way, working upfront to better define consumer needs and building useful self-serve data products can require less (or even just a decelerating amount of) data.
The other constraints of course are quality and trust. You can have the best stocked data warehouse in the world, but the data won’t have any consumers if it can’t be trusted.
Technologies like data observability can bring data monitoring to scale so there doesn’t need to be a trade off between quantity and big data quality, but the point remains data volume alone is insufficient to make a fraction of the impact of a well-maintained, high quality data product.
Machine learning is less data hungry
Machine learning was never going to process the entirety of your data stack to find the needle of insight in the haystack of random tables. It turns out that just like data consumers, machine learning models also need high-quality reliable data (maybe even more so).
Data scientists devise specific models designed to answer difficult questions, predict outcomes of a decision, or automate a process. Not only do they need to find the data, they need to understand how it’s been derived.
As Convoy Head of Product, Data Platform, Chad Sanderson has repeatedly pointed out, data sprawl can hurt the usability of our data stacks and make that job really difficult.
At the same time, machine learning technologies and techniques are improving to where they need less training data (although having more high quality data is always better for accuracy than having less).
By 2024, Gartner predicts the use of synthetic data and transfer learning will halve the volume of real data needed for machine learning.
Collection is easy, documentation and discovery are hard
Many data teams take a similar path in the development of their data operations. After reducing their data downtime with data observability, they start to focus on data adoption and democratization.
However, democratization requires self-service, which requires robust data discovery, which requires metadata and documentation.
Former New York Times VP of Data Shane Murray provides some helpful scorecards for measuring the impact of your data platform, one of which specifically calls out a maturation score on the documentation level of key data assets and data management infrastructure.
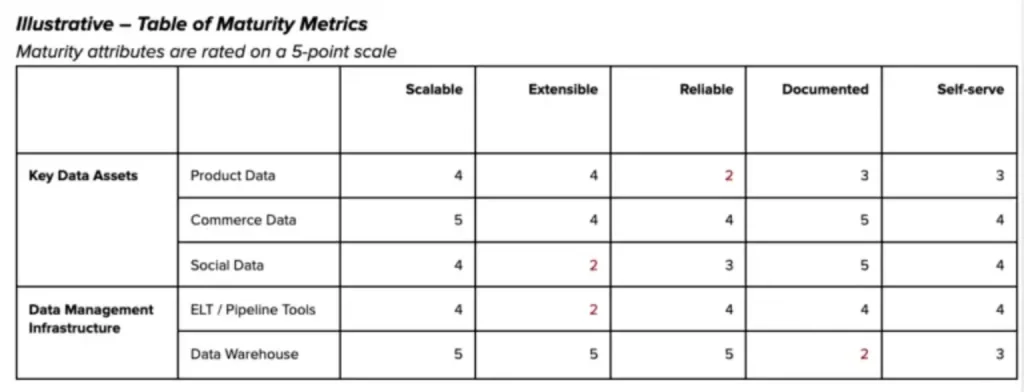
“No data team will be able to document data at the rate at which it’s being created. You can get by when you are a small team, but this will lead to issues as you grow,” said Shane.
“Documentation requires an intimate understanding of how your data assets are being used and adding value to the business. This can be a painstaking process, building consensus on definitions, so you have to be deliberate about where to start and how far to go. That said, the value from providing definition and context to data and making it more easily discoverable usually exceeds the value from building another dataset. Focusing on your most important metrics and dimensions across your most widely used reporting tables is a great place to start.”
If we’re being honest, part of the big data quality challenge is no one outside of the rare data steward enjoys documentation. But that shouldn’t make it less of a priority for data leaders (the more automation here the better).
You’ve got data debt

Technical debt is when an easy solution will create re-work at some later point. It often builds exponentially and can crush innovation unless it’s paid in regular installments. For example, you might have multiple services running on an outdated platform, and reworking the platform means reworking the dependent services.
There have been many different conceptions of data debt put forth, but one that resonates with me combines the concept of a data swamp, where too much poorly organized data makes it difficult to find anything, and over-engineered tables where long SQL queries and series of transformations have made the data brittle and difficult to put in context. This creates usability and quality issues downstream.
To avoid data debt, data teams should deprecate data assets at a higher rate. Our research across hundreds of data warehouses shows organizations will suffer one data incident a year for every 15 tables in their environment.
While every team is time constrained, another exacerbating factor is a lack of visibility into lineage often makes teams unable to muster the audacity to deprecate for fear of unintended breakage somewhere across the stack.
Data observability can help scale big data quality across your stack and provide automated lineage while data discovery tools can help you wade through the swamp. But technology should be used to complement and accelerate, rather than completely replace, these data hygiene best practices.
Big isn’t bad, but it’s not necessarily a good thing either
All of this isn’t to say there is no value in “big” data. That would be an overcorrection.
What I’m saying is that it’s becoming an increasingly poor way to measure the sophistication of a data stack and data team.
At the next data conference, instead of asking, ”how big is your stack?” Try questions focusing on the quality or use rather than the collection of data:
- How many data products do you support? How many active monthly users do they support?
- What is your data downtime?
- What business critical machine learning models or automations does your team support?
- How are you handling the lifecycle of your data assets?

There is always some pain when changing paradigms but take heart, you can always (over)compensate and drive a really big car to the next conference.
Want to better understand the value of your data platform? Interested in big data quality and how data observability and lineage can help you map your key data assets and assist with automated documentation and discovery? Reach out to Barr and/or book a time to speak with us in the form below.
Our promise: we will show you the product.
Read more posts.