Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage When to Build vs. Buy Your Data Warehouse (5 Key Factors)


Nishith Agarwal
Nishith Agarwal is the Head of Data & ML Systems at Lyra Health. Previously, he served as the Head of Big Data Compute & Storage Platforms at Uber. He is the co-author and PMC of Apache Hudi.
In an evolving data landscape, the explosion of new tooling solutions—from cloud-based transforms to data observability—has made the question of “build versus buy” increasingly important for data leaders.
In Part 2 of our Build vs. Buy series, Nishith Agarwal, Head of Data & ML Platforms at Lyra Health and creator of Apache Hudi, draws on his experiences at Uber and Lyra Health to share how his 5 considerations outlined in Part 1—cost, complexity, expertise, time to value, and competitive advantage—impacts the decision to build vs buy data warehouse, data lake, and data lakehouse layers of your data stack. Hint: it’s not a one-size-fits-all answer, but answering a few critical questions can help.
When it comes to the question of building or buying your data stack, there’s never a one-size-fits-all solution for every data team—or every component of your data stack.
The question of whether to build versus buy can mean very different things based on what level of the data stack you’re considering. “Building” can mean anything from building a system from the ground up to leveraging open source tools to assemble and manage your stack in-house.
In a previous article, I shared the five considerations I use to determine whether to build or buy any given piece of your data platform:
- Cost & resources
- Complexity & interoperability
- Expertise & recruiting
- Time to value
- Competitive advantage
How you structure your data platform will always depend on the needs and constraints of your organization. So, the decision to build vs buy data warehouse solutions—or any other storage and compute architecture—is one that requires a a deep understanding of your organization and what you hope to achieve.
In this article, we’ll take a closer look at the data storage level of the data stack to determine when to invest in storage and compute tooling, what “build versus buy” really means when it comes to storage and compute, and how our five considerations might impact your decision.
Let’s jump in!
When to invest in data storage & compute solutions
Before we get into whether to build versus buy data warehouse solutions or beyond, let’s take a moment to consider data storage and compute in a bit more detail and assess when it makes sense to start investing in them.
Data storage and compute are very much the foundation of your data platform. Before your data can be ingested, transformed, and used to feed downstream users’ tables and insights, it first needs somewhere to be stored. And it’s critically important to invest in the correct tooling right out of the gate because your storage and compute solution can have a dramatic impact on how you develop and utilize the other components of your stack in the future.
So what do we mean when we say “storage and compute?”
The three most popular solutions for data storage and compute include the data warehouse, data lake, and data lakehouse. Like our build versus buy decisions, which of these three you choose will depend almost entirely on how you plan to use it. So, let’s take a look at each in a bit more detail.
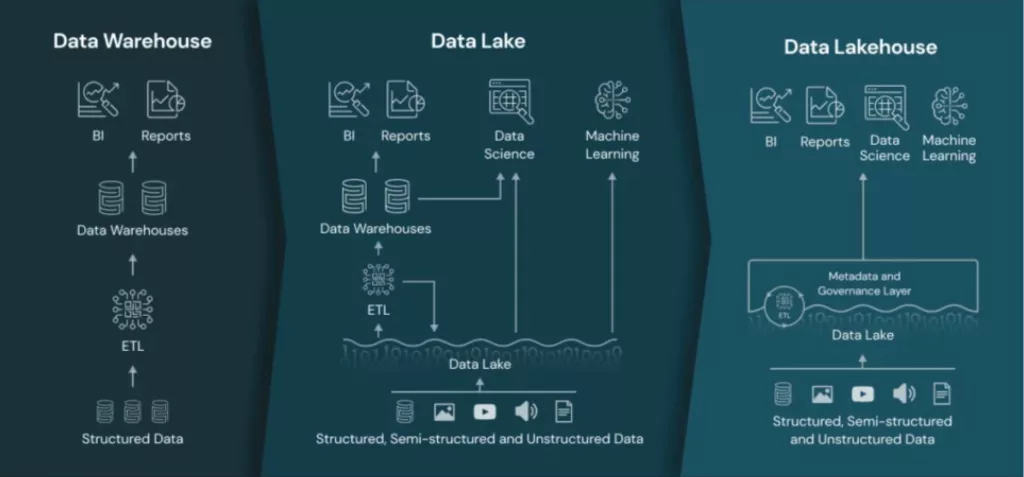
Data warehouse
A data warehouse provides data storage and compute for structured data that’s been processed for a defined purpose. Data warehouses generally leverage SQL for easy data analysis, and integrate metadata, storage, and compute from a single vendor—making them faster to stand up and operate out-of-the-box with a quicker time to value.
In the old days, data warehouses were typically supported as a vertical stack, making them expensive and difficult to scale. However, the modern trend toward disaggregating storage and compute in the cloud has enabled warehouses to be both cheaper and easier to operate, making them an ideal option for hyper-growth startups.
Because warehouses require data to be structured within predefined schemas, they generally encourage better data hygiene, resulting in less complexity for data consumers. However, additional structural constraints limit flexibility and make it difficult to run complex AI/ML workloads, which can increase the cost to augment a warehouse post launch.
Because of their pre-packaged functionality and strong support for SQL, data warehouses are ideal for data analytics teams and business users who want to facilitate fast, actionable querying and insights and don’t plan to make costly and engineering-intensive changes to their warehouse in the near-term.
Data lake
On the other side of the storage and compute coin, a data lake is all about flexibility. Data lakes provide storage and compute for raw unstructured data, and allow engineering teams to pick and choose the various metadata, storage, and compute technologies they want to use. Data lakes tend to be preferable for companies with large volumes of data, data science, and AI and ML training development.
In a data lake, the purpose of the data hasn’t been defined, making the data more accessible for quick updates and changes. One can query this data using various query engines such as Hive, Presto, Spark, their counterpart cloud vendor offerings and more. However, this flexibility also means that the data won’t be as high-quality, audited or easily query-able, limiting quicker access to insights.
Data lakes are ideal for data teams and data scientists looking to build a more customized platform supported by a healthy team of data engineers, companies with outsized data volume, and organizations with evolving data needs who want more flexibility to adapt their platform as they mature without increasing costs like in the case of a data warehouse.
Data lakehouse
As you can probably guess from the name, the datalake house combines features of both the warehouse and the lake into a single solution, to offer both flexibility and cost savings.
Pioneered by Apache Hudi and popularized by Databricks with their solution Delta Lake, a lake house is a disaggregated storage and compute model that allows teams to bring their own cloud store, table format, table services and compute engine. It supports both structured and unstructured data, allowing for cost savings while meeting requirements of different users and workloads. And because it marries the customizability of a data lake with the easy query-ability of a warehouse, it’s an ideal solution for a broad range of data teams. Similar to a data lake, data engineers can choose from various query engine systems that play nicely with the lakehouse.
In fact, most enterprise companies—including giants like Meta, Google, and Airbnb—are moving toward such a hybrid model that includes elements of both the warehouse and the lake.
Build or buy: data storage and compute
Now, given the complexity of modern storage and compute solutions, it’s probably clear to most leaders that this won’t be a build or buy discussion in the traditional sense. Building storage or compute infrastructure from scratch is something that requires both hyper-specialized skills and a tremendous amount of engineering resources to be successful, adnd naturally, there’s a very short list of organizations that meet that criteria.
Because of the implicit barriers to entry for an infrastructure project of this magnitude, building storage and compute solutions is best accomplished by companies that specialize in some form of platform and infrastructure development. All of the top three cloud providers currently developing storage and compute solutions have both the skill and the scale required to build these infrastructure components in-house. For example, Google supports BigQuery and DataProc on Google Cloud Platform, Amazon built Redshift, Glue and Athena on S3, and Microsoft built Synapse and Azure Data Lake on Azure.
Outside of the big three, there are also companies that specialize specifically in data infrastructure products, like Snowflake with its flagship data warehouse solution, Databricks with Spark+Delta Lake, Onehouse with Apache Hudi and Tabular with Apache Iceberg.
Each of the companies mentioned above is uniquely positioned to build storage and compute components for one reason or another. So, it goes without saying that if you’re not already in the business of selling storage or compute as a service, there’s just not a good reason to implement this level of your data stack from scratch.
But just because you’re not building a component from the ground up doesn’t mean there’s not a build versus buy decision to be made.
What about open source solutions? There are still multiple open source solutions that enable a data team to stand-up compute and storage in-house without using a managed service. For example, you could use Kubernetes and YARN for compute, open source file systems such as MinIO or HDFS or lakehouse systems like Apache Hudi or Delta Lake for storage, and even traditional open source data warehouse solutions like Hive and HBase.
Now we have a really interesting question to answer. Should you stand up storage and compute on an open source platform and build out a team to maintain it in-house? Or is it better to buy a managed solution through an open source or cloud-based provider and save your engineering resource for other priority projects?
To attempt to answer that question, let’s return to those initial considerations and see how they might play out in the use case of your storage and compute solution.
Cost & resources
In layman’s terms: how much are you willing to invest in this project?
Because storage is the foundation of your data stack, the cost to build a solution that can scale with your needs and future tooling requirements is naturally quite important.
So, is it less expensive in aggregate to stand up and maintain an open source solution or do the benefits and savings of a managed solution outweigh the costs? As a data leader, it’s your job to find where that tipping point is and how to optimize around it.
In addition to the cost to stand up your MVP solution, you’ll also need to consider the future costs of your storage and compute solution as well. How much maintenance will it require? Will you need to stand up additional in-house tooling—like ingestion, orchestration or monitoring—to work with your internally-managed open source solution? All of those costs will need to be factored into your build or buy decision as well.
For a large company like Uber operating at massive scale, buying cloud solutions can be considerably more expensive than standing up open source solutions in-house. In some cases, even some open source solutions might not be able to address problems at scale.
Apache Hudi was born out of the limitations of other warehouses for large scale data processing at Uber, which processed hundreds of petabytes of data per day with low latency. And in that situation, the benefits of building an in-house solution outweighed the costs of that decision. We’d reached a scale in both our size and data needs that made it advantageous to stand up a new open source solution in-house—and the future costs associated with it.
However, at a startup like Lyra Health, we have to be more thoughtful about what we build.
Hyper-growth startups have constantly evolving scale, requirements and priorities. At Lyra Health, we’re focused on building an industry-leading platform for mental health solutions. Our priority—and specialty—is to support millions of care seekers with a platform that makes it easy to access better healthcare. So, it makes sense for us to use out-of-the-box lakehouse technologies like Hudi, Iceberg or DeltaLake as it meets our needs.
Overall, we’ve found a cost effective place for our team by utilizing a mix of both managed and open source solutions depending on the needs, scale, and constraints of our data stack.
Expertise & recruiting
Maintaining a storage and compute solution requires extensive experience in file systems, databases, et cetera—experience not every team is likely to have. At Uber, it made sense to build our own data lake solution (Apache Hudi) on an in-house, on-prem managed Apache YARN service only because we had very specific business needs and our team had engineers with both the specialized infrastructure expertise and availability to do so.
Very small companies and startups may be able to stand up a K8 or YARN cluster in the cloud as an MVP solution, but as a company begins to mature, there is quite a bit of dedicated engineering effort that’s required and in many cases ends up being managed by a DevOps team. It totally depends on the skills of your data engineers. If you don’t have the experience in-house, you’ll need to invest in something like AWS Managed K8 or AWS Managed YARN until a proper DevOps team can own that piece of the infrastructure.
Where this debate becomes really interesting is when we consider the lakehouse infrastructure. Coined by Databricks, the lakehouse is a paradigm-shift for data platforms. Naturally, the technologies used to build lakehouses are new and state-of-the-art.
Fewer data engineers have the skills to use existing technologies to build out a lakehouse solution—and lakehouse solutions are almost certainly where the industry is headed. Imagine putting together components of a data warehouse and then being responsible for not only maintaining it but also debugging issues that arise within the system. There are so many tricky components to any warehouse. Debugging major errors or issues, while also finding the right interoperability and maintaining consistent support can require deep systems and infrastructure knowledge.
Complexity & interoperability
The question here is how suited your storage and compute solution will be for your future needs. This goes hand-in-hand with the cost of your open source versus managed decision because the interoperability of your storage solution will influence the total cost to maintain your platform.
First, let’s consider some out-of-the-box managed solutions. When it comes to interoperability, solutions from Google, Amazon, and Microsoft tend to be vertically integrated offering their own ecosystem for your data stack. While this approach can limit flexibility, it can also simplify some decisions down the road. Warehouse solutions like Snowflake promote greater interoperability by remaining cloud-vendor agnostic, supporting a broad range of integrations based on your data needs. Likewise, lakes and lakehouse solutions also tend to offer greater interoperability due to the flexibility of their storage solution.
So, how does standing up an open source solution in-house stack up against a managed solution?
An open source solution generally offers better extensibility than a managed solution, but it will also introduce greater complexity. An open source approach requires investigations, trial and error, and dedicated time to understand complex software that’s not necessary with most managed solutions. It also requires engineers to understand security models, how to auto-scale, and how they’ll respond if the system goes down.
From that perspective, it’s generally easier to buy a managed version of one of these open source solutions because most of that groundwork will already be in place. Your data team can enjoy the benefits of interoperability faster without the complexity native to in-house solutions.
However, while piecing together a robust storage and compute solution from open source software is certainly challenging, it might still be worth it for some teams. At great scale, the value of extensibility outweighs the complexity of open-source solutions. Your data needs may become so specialized that you need the flexibility of open-source software just to create a solution that’s capable of supporting them. And in that case, standing up a stack in-house probably makes a lot of sense.
Still, it’s important to remember that your costs aren’t limited to the price to stand-up your solution but also to maintain it over time. And those costs will increase the more of your data stack you choose to stand-up internally. Your decision will also set the standard for what tooling you can choose in the future.
Time to value
Standing up a storage and compute solution in-house is tremendously difficult in today’s modern data ecosystem, requiring a substantial amount of time from very specialized engineers to do it successfully. And even with the best team of engineers working around the clock, it’s going to be a while before you get this one up and running.
There’s typically a steep learning curve to understand the various different configurations of systems, making your solution work for your environment, and adding the right metrics and fail-safes to make it reliable and robust. Hearing from users in some open source communities, there are instances where it takes 6+ months to stand up a lakehouse solution. With that in mind, it’s likely to be many months before you’re able to really deliver value to your business and end-users.
Like much of what we’ve discussed when it comes to your storage and compute tooling, the consideration isn’t just the time to stand up your initial solution but also the time to maintain and augment it later. While it’s impossible to know exactly what that might look like, it’s important to be aware before you make any decisions. This can also help you better plan for future projects by earmarking resources early based on the route you’re likely to take.
Competitive advantage
Maybe you have the time. Maybe you have the resources. Maybe you even have the expertise and dedication to stand up your storage and compute solution in-house. But is it actually to your company’s benefit to do so?
Even if you answered yes to every other question, if standing up a storage and compute solution in-house doesn’t provide some demonstrable advantage to your organization, it still won’t make sense to do it.
Let’s go back to my time at Uber for just a moment. At Uber, we built Apache Hudi because we had material needs that went above and beyond what a plug and play solution could offer and it provided a strategic advantage to Uber for us to do so. Our state-of-the-art data platform delivered minute-level freshness to data scientists, analysts, and engineers, which directly improved fraud detection, experimentation, and the quality of Uber’s user experience.
The investments Uber made in software helped to boost Uber’s competitive advantage. And the same could probably be said for companies like Google and Netflix. But, the reality is, most companies aren’t Google or Netflix. Unless the cost of buying a managed solution is substantially greater than the engineering investment needed to build it, buying will allow you to create competitive advantage from your data platform far more effectively than “building” with an open-source solution.
Open source or managed solution: are you the exception or the norm?
As I wrote before, whether you’ll build or buy any component of your data stack will always depend on your company’s unique needs and constraints. Having said that, there are some components of a data platform that will be a buy far more often than they’re not. And storage and compute solutions are some of those components.
Of course, there will always be exceptions to any rule. And a company with considerable scale and resources could likely benefit from standing-up an open-source warehouse, lake, or lakehouse internally—and that’s a decision only you and your stakeholders can make.
For the vast majority of companies—from scaling startups to mid-markets—buying a storage and compute solution like Snowflake, Databricks, or Redshift will deliver competitive value faster and facilitate scale far more easily than a comparable open-source solution.
What storage layer you choose will depend on your organization’s specific use-cases, policies for sharing data with cloud providers and overall cloud/infrastructure architecture. But whatever your situation, remember to do a thorough cost-benefit analysis to tease out any concerns, and use that exercise as a catalyst to get the conversation started.
Whether it’s your warehouse solution or your data observability tooling, great decisions rarely come without hard conversations. So, in the spirit of innovation and progress, keep those build versus buy conversations going.
Come back for Part 3, which will look at building versus buying your data presentation tooling (ingestion, transformation, and BI solutions), and how you can apply what you’ve learned so far to make the best recommendation for your team.
Stay tuned!
Curious to learn more about how to achieve reliability across – and beyond – your data warehouse or lake? Reach out to the Monte Carlo team today.
Our promise: we will show you the product.
Read more posts.