 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How to Find and Fix Data Consistency Issues


Michael Segner
Michael writes about data engineering, data quality, and data teams.
Imagine an orchestra, where each instrument represents a different data source in your system. The violins could be your customer database, the cellos your transaction records, the trumpets your web analytics, and so on.
When all the instruments play in tune and in time, following the same musical score, the result is a harmonious symphony – a rich, coherent piece of music that conveys a clear theme and emotion. This is like having consistent data: all parts of the system agree, and you can confidently analyze the data and make decisions based on it.
However, if even one instrument is out of tune or playing a different score, it creates discord. The overall harmony is disrupted, and it becomes difficult, if not impossible, to discern the intended theme. This is what happens when data is inconsistent: analyses can be skewed, decisions can be misguided, and the overall understanding of the data can be compromised.
In this guide, we will explore data consistency as a crucial indicator of data quality. We’ll delve into its importance, the problems caused by inconsistency, and ways to maintain consistency in your data. By the end, you’ll be well-prepared to conduct your own data symphony, ensuring every ‘instrument’ plays in tune and in harmony.
What is Data Consistency?
Data consistency refers to the accuracy and uniformity of data stored across multiple data sources. In a consistent database, once a transaction has been committed, all subsequent accesses to that data will reflect the updated value. It ensures that all users see the same data and that any given data instance or item is the same across all copies or replicas.
In other words, every time a piece of data is recorded, no matter where in the system that happens, it should always look the same. This consistency must hold across different databases, different tables within a database, and even different entries within a table.
Consider an example. Let’s say you have a customer’s address stored in two different places in your system – once in a table for billing information, and once in a table for shipping information. If the customer updates their address, and this change is reflected in the billing information but not the shipping information, you have a consistency problem. The same piece of data – the customer’s address – is different depending on where you look.
Consistency can also relate to the format or type of data. For example, dates should always be stored in the same format (like ‘YYYY-MM-DD’), and numerical values should always be stored as the same type of number (like integers or floating point numbers).
Perhaps one of the largest data consistency challenges revolves around defining the metrics leveraged by the company. Metrics consistency can be tricky to navigate because they seem simple, but are actually relatively complex formulas under the hood.
For example, one data analyst could calculate a monthly revenue metric by aggregating total purchases and removing returns made while another analyst may do the same thing but exclude purchase made from a previously purchased gift card. Defining the semantics of data allows the organization to speak the same language and it is absolutely critical to data consistency.
In essence, when we talk about data consistency, we’re talking about ensuring that our data is reliable and predictable, no matter where or how it’s stored. It’s about making sure all our ‘instruments’ are not just playing the same piece, but also playing in the same key, following the same tempo, and using the same musical notations.
In the following sections, we’ll delve deeper into why data consistency is so important, how inconsistencies can creep into our data, and how you can guard against them. But for now, just remember: consistency is the key to harmony, both in music and in data.
In Praise of Consistency: The Benefits of Consistent Data
Consistent data is the backbone of effective data analysis and decision-making. Without it, you wouldn’t have key benefits like:
- Reliability: Like a dependable instrument in our orchestra, consistent data plays the right notes at the right time. It allows us to trust our data and the insights derived from it.
- Efficiency: Consistent data reduces the time spent checking, cleaning, and reconciling data. This frees up resources for more valuable tasks, like analysis and strategy.
- Accuracy: With consistent data, our analyses and reports reflect reality more accurately. This supports better, more informed decision-making.
- Interoperability: Consistent data can be easily combined and compared with other data sets, enabling more comprehensive insights.
The Chaos of Inconsistency: The Consequences of Inconsistent Data
On the other hand, inconsistent data can create a cacophony. We’re talking:
- Bad Decisions on a Grand Scale: Inconsistent data is like a musician playing off-key in a grand performance – it can throw the entire orchestra into chaos. Bad data can lead to bad decisions, affecting everything from business strategy to customer relations.
- A Tangle of Inefficiency: Imagine trying to harmonize an orchestra when each section is playing from a different sheet of music. You’d spend more time fixing mistakes than making music. Similarly, inconsistent data can lead to wasted time and resources in cleaning and reconciliation efforts.
- Distrust in Data: When a violinist hits a wrong note, it’s noticeable. When data is inconsistent, it raises questions about its reliability. Over time, this can lead to a lack of trust in the data, making it difficult to use data effectively in decision-making.
- Limited Interoperability: Inconsistent data is like trying to play a duet with someone who’s not in tune. It’s hard to make beautiful music together. Similarly, inconsistent data can limit the ability to combine and compare data sets, potentially reducing the depth and breadth of analysis.
By understanding these potential consequences, you can better appreciate the importance of striving for consistency in your data.
How to Identify Inconsistencies and Ensure They Never Happen
Inconsistencies can happen due to a variety of reasons such as human errors during data entry, system glitches, mistakes during data migrations, disparate data sources having different formats, or changes in data over time that are not properly updated across all systems.
To track down and handle inconsistencies lurking in our data we need to deploy several strategies.
- Remove Data Silos: Data silos are the enemy of data consistency as they prevent a unified view. A common example of this is in the marketing domain. If digital marketers are accessing Marketo and Salesforce for information on a campaign, they may not match. This could be the result of a sync issue, the type of information each collects, or how each platform treats different data types. Having the data warehouse as a central source of truth can help present a more consistent view of the campaign.

Screenshot of Monte Carlo’s data profiling feature, which can help with data consistency. - Data Profiling: Profiling a dataset can reveal its typical behavior, which is helpful for identifying when those become anomalous in a way that might create issues with data consistency. Is a column never NULL? What is its cardinality? Is the data type a float or a varchar? What are the maximum and minimum values? This type of data audit involves examining individual attributes, looking for patterns, outliers, and anomalies that might indicate inconsistencies.
- Understand and Document the Context: Data engineers may not always have the full business context behind a dataset. Not understanding the semantic truth can impede data consistency efforts. Chad Sanderson, the former head of data at Convoy, shared an example where the “concept of shipment_distance could be very different depending on the dataset. ‘Distance’ could be the delta between the starting facility and end facility in miles or hours, it could refer to the actual driving time of a carrier (accounting for traffic, pit stops, etc), it could include the number of miles a trucker spends driving TO and FROM the pick-off and drop-off point, it could refer to the length of the ROUTE (a separate entity with its own ID) and so on and so forth.”

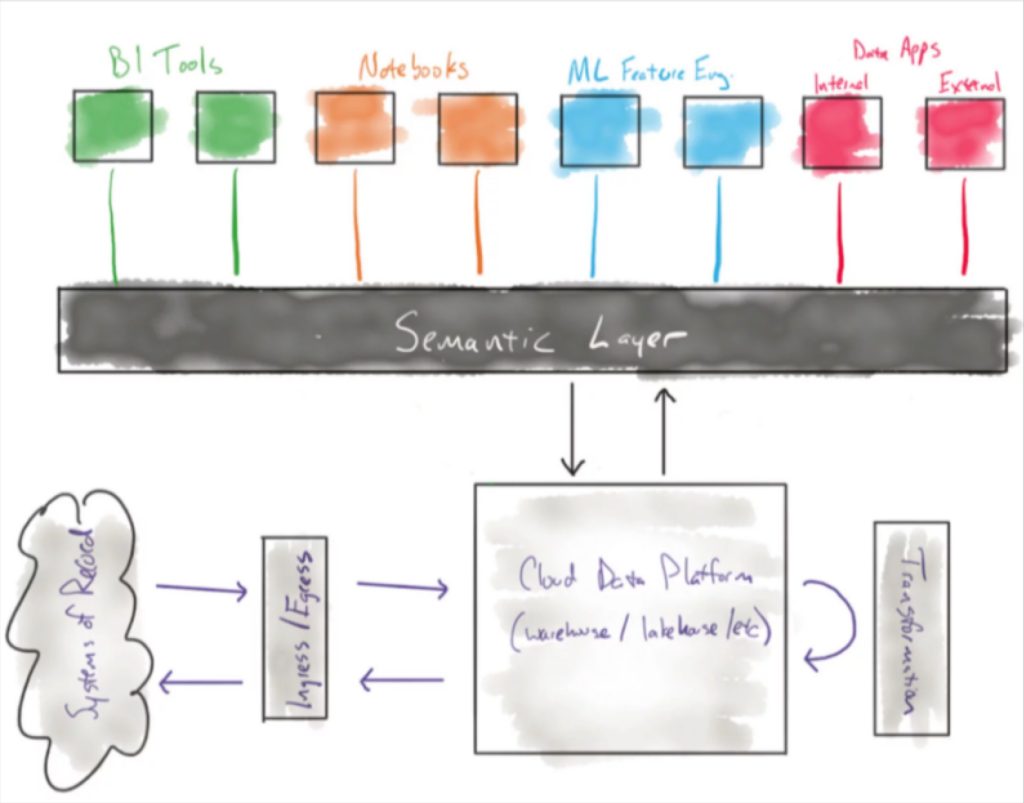
A semantic layer can help with data consistency. - Create a Semantic Layer: Once you have defined your key metrics it’s time to lock them down so they can be leveraged by the entire organization. dbt, the central tool within the transformation layer where most metrics are built, is a natural place to start building a semantic layer. Looker also has a semantic layer called LookML.
- Data Validation: Like a tuning fork ensuring our instruments are at the right pitch, data validation checks that incoming data meets certain criteria, catching data consistency issues before they enter our system. Implementing data contract architectures can also help prevent bad data from ever entering the data warehouse.
- Automated Data Monitoring: Think of data quality monitoring as our orchestra’s conductor, keeping an eye (or ear) on the overall performance and stepping in when something’s not right. Data monitors can catch inconsistencies, like unexpected schema changes or anomalous values, and alert us to their presence, allowing us to address them swiftly.
- End-to-End Pipeline Monitoring Business logic and metric definitions are executed in dbt models and SQL queries. Having a data observability platform that is able to monitor your data pipeline from ingestion to visualization, and can pinpoint how changes in dbt models or query changes may have impacted data consistency, can be a big help.

Monte Carlo is a powerful tool in the fight for data consistency
Let’s face it: managing all the different data systems, along with obtaining any sort of consistency, is virtually impossible to do manually…unless you have a very large team that’s fond of thankless tasks.
Fortunately, that’s where the data observability platform Monte Carlo steps in. Monte Carlo monitors and alerts you of data consistency and broader data quality issues before you even knew you had them. Using machine learning, the platform doesn’t just passively monitor; it actively learns about your data environments using historical patterns, detecting anomalies, and triggering alerts when pipelines break or anomalies emerge.
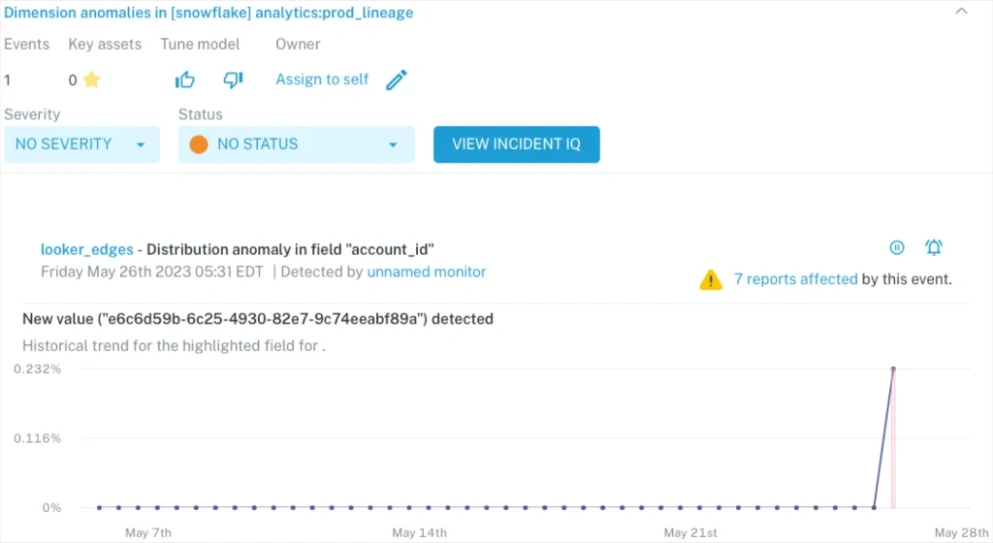
If you’re looking for a maestro to guide you through the intricacies of data consistency, consider Monte Carlo. It’s like a crystal ball and a conductor’s baton rolled into one, giving you the visibility and control you need to maintain your data symphony’s harmony. To see it in action, don’t hesitate to request a demo and experience it firsthand.
Read more posts.





