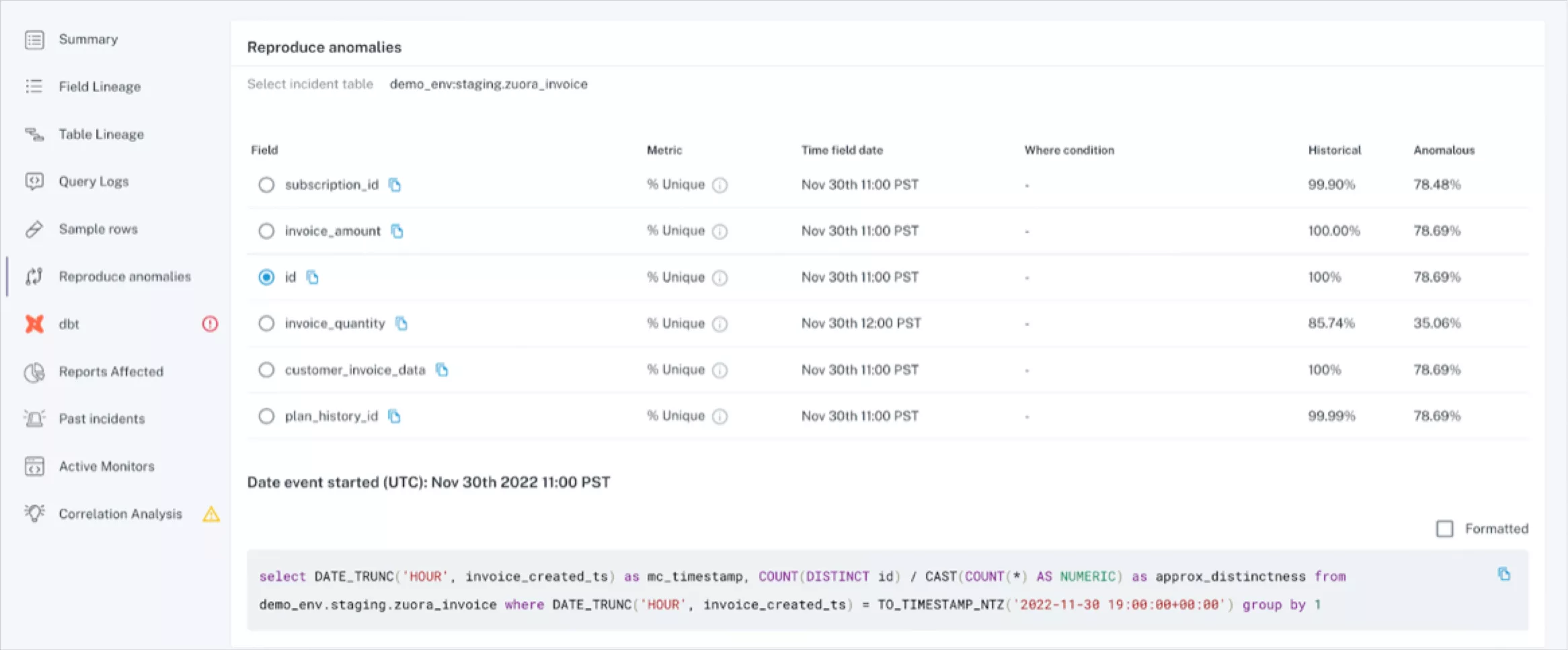
Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Data Enablement Drives Sustainable Value at Upside
According to Upside analytical engineers Adam Shepard and Jack Willis, data empathy, or data enablement, is the process of getting in the dirt with stakeholders and living their life with data. This allows data teams to build the data products that address their users’ needs and meet them where they are.
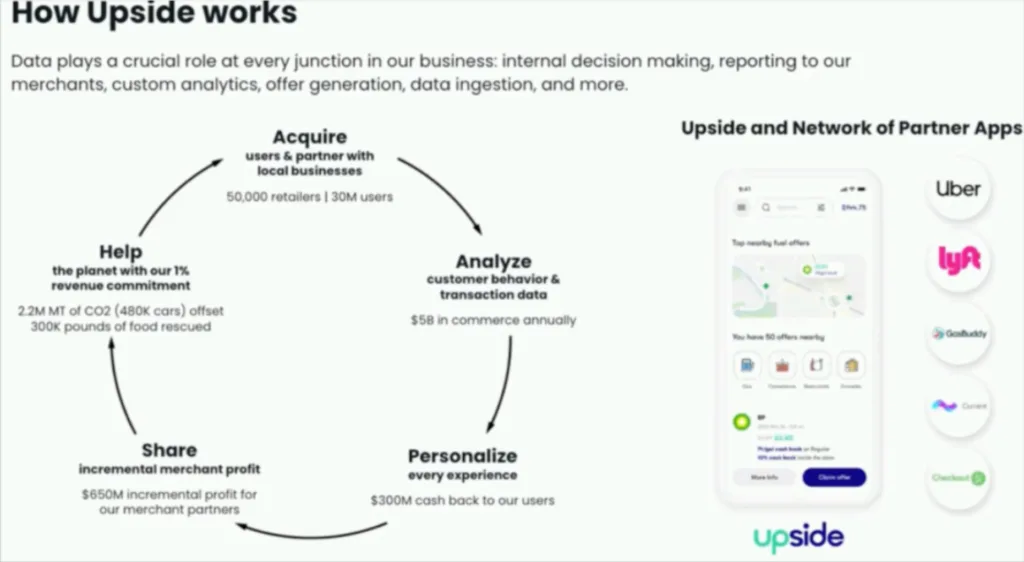
It’s a concept that has enabled Upside–a retail technology company that partners with over 50,000 local businesses to provide personalized offers to millions of users–and it’s data team to scale and keep pace with the rapid growth of the business.
“We build a pathway of trust in the data products…where our stakeholders aren’t afraid of data and engineering and our data practitioners aren’t afraid of the business …This puts us on a data flywheel,” said Jack.
The two analytical engineers slowly developed their data enablement process over more than a year of conversations as they realized the primary obstacle to successfully scaling their operations was the disconnect between data professionals and users.
“…I realized that a lot of the [data] products that I made for this team didn’t hold up to snuff [when] I actually saw what they were doing with it,” said Jack.
But data empathy is a two-way street requiring buy-in from both data practitioners as well as business stakeholders. Data enablement also requires a significant upfront investment in understanding and training.
This post will highlight the challenges facing Upside and how they created a data enablement process to worked collaboratively with business stakeholders and analysts to scale their impact.
Forgotten data products and murky requirements
Upside described a systemic problem many data teams face.
“Too often data teams are asked to build one-off products to meet a business requirement, and then those data products might just be forgotten and left running, or they’re put on a shelf to collect dust,” said Adam.
“And occasionally because we build those products just to solve an immediate need, we might not have the time to step back and unify the data models or the dashboards. Or sometimes even worse, we don’t get a chance to unify the terminology that we’re using as a business to describe the exact same concept just in different contexts.”
The separation between data infrastructure and the people consuming the data results in data teams building to a murky list of requirements. When the resulting data products miss the mark, the consequences compound as the data warehouse and BI infrastructure become less the source of truth and more a source of mess.
Self-service analytics can also be tricky without close collaboration.
“We gave analysts read only access to the production database and said be really careful and mostly left folks to their own devices. Some of our spreadsheets got moved into scripts and programmatic access, but that first production database outage because of an exploding join is a learning experience,” said Adam.
To solve those data enablement issues and better scale, the Upside team built out a modern data warehouse to help isolate analytical queries and from production, while still giving analysts power and flexibility. They also developed sandbox environments where contributors could work with dbt and contribute back to their core data flows.
Their data engineers also dug in with business stakeholders to understand how the business was modeled in order to create reusable data models to answer business questions. All of this came together to create a stable foundation for self-service and a transition toward data product development.
Creating self-sustaining community data gardens
Upside realized they needed to grow participation in the platform as it requires active curation much like a garden.

They also realized analytics engineers, in their cross functional roles, are uniquely positioned to lead this data enablement effort.
“Our analytics engineers are supposed to be accelerants, not necessarily domain experts. So we position them in the middle of all of these different specialized teams. This allows them to become a center of excellence and then be able to embed with those teams to acquire the cross-functional expertise,” said Jack.
“Our analytics engineers will help develop initial solutions, accelerating time to market, and then leave behind the patterns, practices, and teaching for others to solve their problems.”
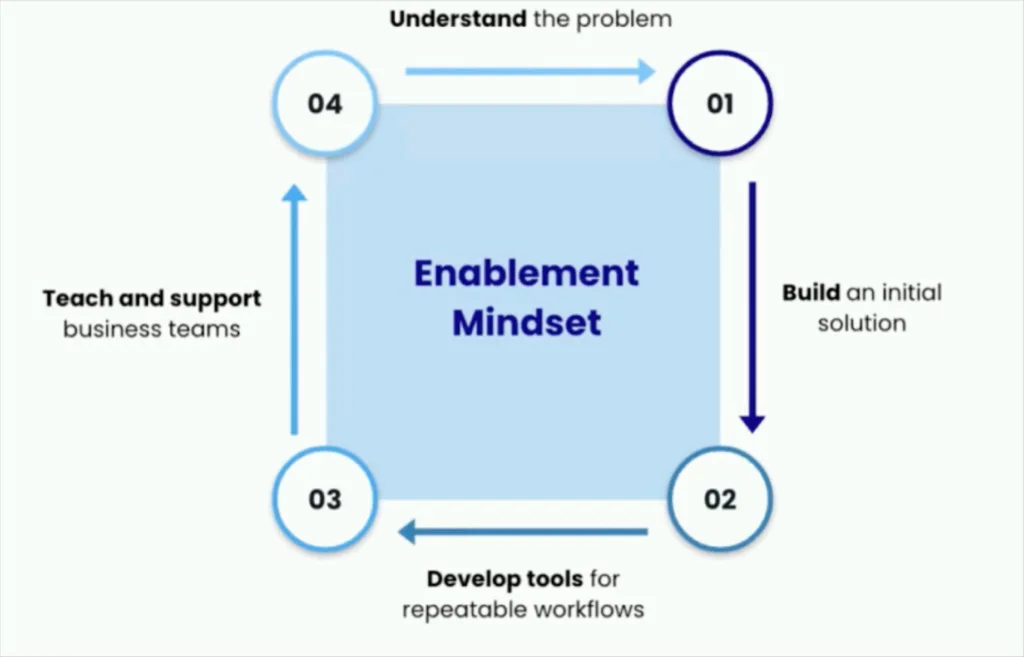
The responsibilities for the embedded analytics engineer are to understand the business problem; create an initial solution to solve the problem; and then develop automated tools and workflows for the domain teams to attack the problem on an ongoing basis. The data enablement embedding framework involves three steps:
- Spike: The analytics engineer is fully embedded with the team and lives the life of the person for whom the tool is built. This way they truly understand the problem at hand.
- Plan: The analytics engineers plan directly with stakeholders to align everyone on the vision and work distribution.
- Train: Training takes time and can slow down the execution of a project in the short term, but enabling domains to own the solution long-term eliminates maintenance and creates invaluable relationships.
The key is to meet analysts and stakeholders where they are on their journey and create tools that are simple enough for them to own and grow. Basically, don’t jump into machine learning if the tool users are only using SELECT *.
“We firmly believe that domain experts are really the ones who are best positioned to address their problems in an ongoing fashion, and we want to build the tools and frameworks to help them do that,” said Adam.
For example, Upside originally implemented Monte Carlo’s data observability platform by recreating the data quality checks they had in Looker. They worked in a silo and threw it over to the system health team upon completion.
However, they found adoption became much quicker and more sustainable when they built custom monitors and trained alongside the systems health team. By incorporating them into the design and creation process, they achieved buy-in and enabled the system health team to set up monitors that would create meaningful insights.
Obtaining buy-in from the gardeners
What about the data analysts and business users who are asked to maintain these solutions long-term, isn’t that a big ask?
Yes, admit the Upside duo, but they’ve developed three pillars to their data enablement efforts to ensure buy-in from both sides. They are:
- Don’t make bad tools– “It may seem dumb, but it’s important to make tools that generate a cost savings greater than the amount of time spent maintaining the tool and it has to make the analysts’ lives better,” said Jack. For example, if it will take weeks to obtain the right data, you may not want to investigate the biggest driver for breakage in cash flows even if it is nice to know.
- Have a forum for questions– “If you’re going to ask someone to learn something new, they are going to have questions…We have twice a week office hours…and channels on Slack that allow this open dialogue back and forth where people can get the help they need,” said Jack.
- Leverage solid processes– “If you can’t convince an engineer to do something correctly, you will never convince an analyst to do it. By creating systems that allow analysts to do the right thing from the get-go, we make it easier for them to ship into prod correctly,” said Jack.
Scaling impact through data enablement
The Upside data team has been able to dramatically scale their impact by creating self-sustaining data environments through their data enablement efforts.
In mid 2020 they had over 150 team members and only two data engineers. Two years later that became 300 team members and four data engineers–and that’s split across both platform and business needs.
Adam and Jack noted they were still in the weeds of this process (pun intended?), and that self-sustaining ecosystems don’t happen overnight.
However, as growing data teams begin to look at leveraging a more decentralized (dare we say data mesh) or data center of excellence model, they would do well to learn from the level of thought and effort Upside has put towards long-term data enablement.
Interested in how data observability can create data trust and accelerate your data enablement efforts? Fill out the form below to schedule a demo of our platform.
Our promise: we will show you the product.
Read more posts.