Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage They Handle 500B Events Daily. Here’s Their Data Engineering Architecture.

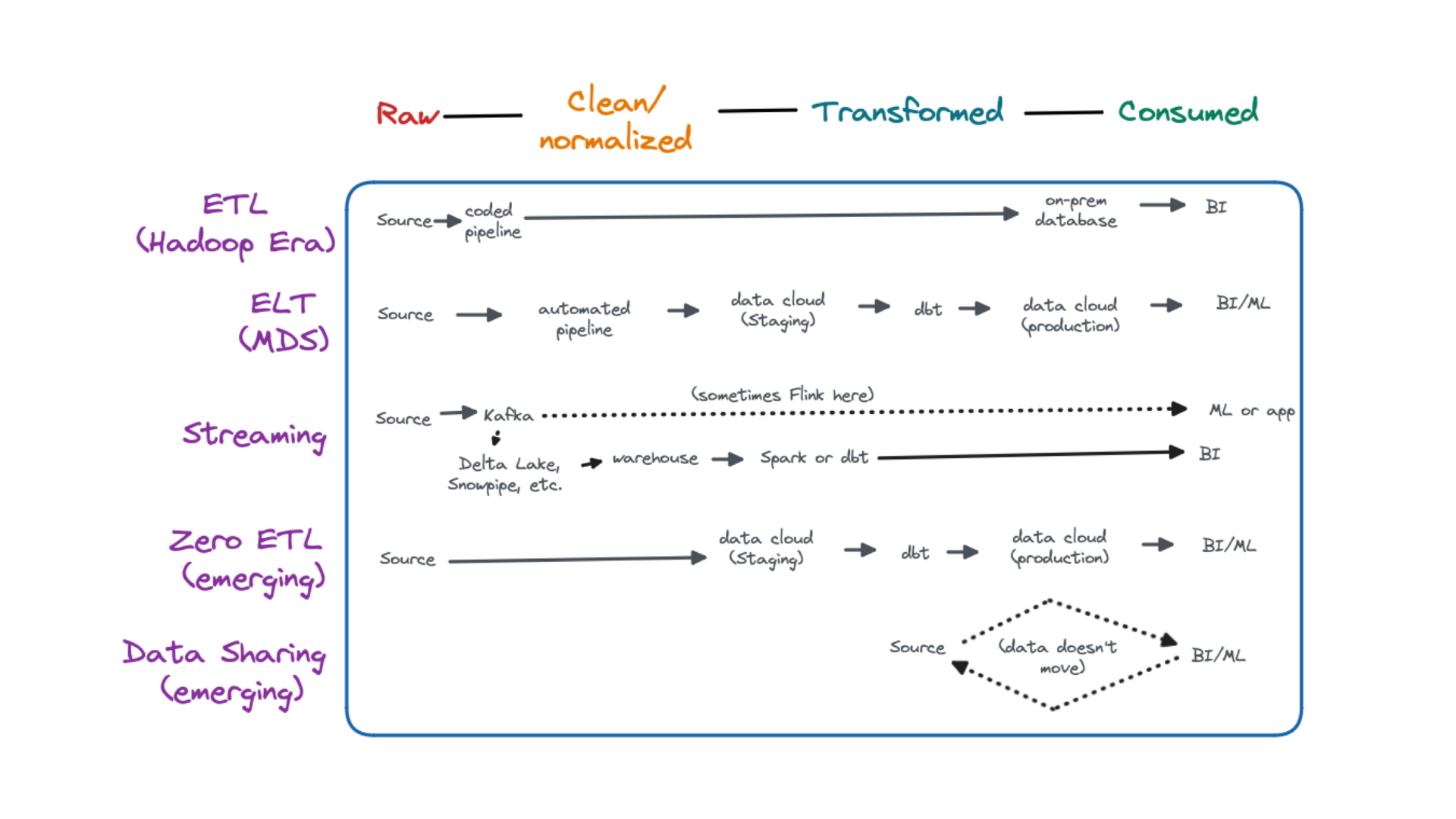
A data engineering architecture is the structural framework that determines how data flows through an organization – from collection and storage to processing and analysis. It’s the big blueprint we data engineers follow in order to transform raw data into valuable insights.
Before building your own data architecture from scratch though, why not steal – er, learn from – what industry leaders have already figured out? And who better to learn from than the tech giants who process more data before breakfast than most companies see in a year?
Netflix, Uber, Spotify, Meta, and Airbnb offer a masterclass in scaling data operations, ensuring real-time processing, and maintaining data quality.
While not every company needs to process millions of events per second, understanding these advanced architectures helps us make better decisions about our own data infrastructure, whether we’re handling user recommendations, ride-sharing logistics, or simply figuring out which meeting rooms are actually being used.
Table of Contents
Some Common Data Engineering Architecture Tools They All Have in Common
Surprisingly, these tech giants have more in common than you might think. While I expected each company to have their own proprietary tech stack, I discovered they all rely on the same powerful open-source tools. Before diving into what makes each company unique, let’s look at the three tools that kept showing up everywhere:
- Apache Kafka: A distributed event streaming platform that is the standard for moving large amounts of data in real-time. It can easily handle millions of events per second and is where data starts in the pipeline before being consumed by another tool for storage or analysis.
- Apache Spark: The most popular distributed analytics engine. If you want to process your data, you are probably moving it here to do that. While originally built for batch processing, it has more recently also developed support for real-time processing.
- Apache Flink: Another analytics engine, but gaining popularity quickly for being built for real-time processing, making it easier and more capable for that use case than Spark.
Ever Wonder How Netflix Knows Exactly What You Want to Watch?

When you click on a show in Netflix, you’re setting off a chain of data-driven processes behind the scenes to create a personalized and smooth viewing experience. This is due to the data engineering architecture they’ve built.
As soon as you click, data about your choice flows into a global Kafka queue, which Flink then uses to help power Netflix’s recommendation engine. For data storage, Netflix relies heavily on Amazon S3 for scalable storage and uses Apache Iceberg to organize and manage the data.
This doesn’t just enhance the user experience; it also shapes how Netflix delivers content. By tracking what people watch and where they’re located, Netflix can then predict what you might want to watch next and proactively cache popular shows and movies closer to users through its own content delivery network, Open Connect. This makes the whole experience seamless, so your next show is ready to play without a hitch.
How Does Uber Know Where to Go?

Just like with Netflix, requesting an Uber starts a bigger journey in the background, within their data engineering architecture.
When you request a ride, Uber grabs your location and streams it through Kafka to Flink. Flink then gets to work finding the nearest available driver and calculating your fare. Uber stores its data in a combination of Hadoop and Cassandra for high availability and low latency access.
Uber goes above and beyond with data quality, building a whole data observability platform called the DataCentral to monitor the health and status of their data in real-time.
Why Flink instead of Spark? Sure, real-time speed is essential—especially when you’re shivering outside in the cold—but what really makes Flink special is how it handles real-time data. The difference is that Flink was built specifically for real-time, with precise timing and “exactly-once” processing guarantees by default. This means that Uber can make sure each event—like matching you with a driver or calculating your fare—happens only once, right when it’s needed. So there is no worry of the same driver being assigned to multiple riders or for the price to be double-counted due to a processing error.
What Data Does Spotify Need to Know Your Next Favorite Song?

When you hit play on Spotify, you’re tapping into a vast ecosystem of data and machine learning within their data engineering architecture that helps tailor your music experience. Every time you play, skip, or save a song, Spotify notes the behavior and passes it to their recommendation system through Kafka.
The processing for the recommendations themselves are handled by Apache Beam, which is a bit like a combined Spark and Flink, but with a more convenient API for handling both batch and stream processing in a unified way. Spotify stores much of its data in a wide variety of Google products, like Bigtable, which helps it handle high-speed access and storage.
From Beam, Spotify uses TensorFlow to analyze your listening patterns, compare it to millions of other users, and predict what songs and artists you’ll enjoy next. This helps create personalized playlists like Discover Weekly and Release Radar, so that your next favorite song is always just a click away.
How Does Meta Know What You’ll Want to See Next?

Every time you interact with Facebook or Instagram—whether by liking a post, commenting, or simply scrolling—Meta is gathering insights to make your experience more personal. As we would expect, Meta’s data stream begins with Kafka before going to Spark for processing, and the data is stored in Hadoop’s HDFS for scalability. Facebook did develop the popular machine learning library PyTorch, so it is no surprise that it makes up a major part of the analysis.
The process goes deeper than simple likes and comments. Meta’s algorithms consider a range of engagement data, like which posts catch your attention, how long you view them, and who you engage with most often. By combining these signals, Meta fine-tunes a feed that’s tailored to your interests, blending updates from friends, trending videos, and ads that are likely to resonate with you. Each time you open the app, this dynamic blend of content keeps things relevant, fresh, and engaging.
Finding Your Next Stay with Airbnb’s Data

When you’re searching for a place to stay on Airbnb, a series of data-driven processes via their data engineering architecture spring into action to bring you the most fitting options. Airbnb’s backend begins with Kafka for streaming user interactions, while Apache Spark processes vast amounts of data about listings, user behavior, and preferences. ElasticSearch then powers the lightning-fast search results you see, while machine learning frameworks like TensorFlow enable Airbnb’s recommendation systems to make smart suggestions.
For data storage, Airbnb uses a mix of Amazon S3 and Snowflake to manage data and support complex queries. Airbnb’s internal data quality platform, Metis, helps the team monitor data quality issues across the pipeline, keeping their recommendations and search results accurate.
Airbnb doesn’t just look at your search filters—it also considers factors like your past bookings, preferred amenities, and budget. These personal preferences are combined with broader data, such as neighborhood popularity, seasonal demand, and pricing trends, to deliver options that align with what you’re after, whether it’s a cozy cabin or an urban loft. This advanced use of data ensures that browsing for your next stay feels intuitive and tailored, connecting you to the ideal listing with ease.
The Common Data Engineering Architecture Need: High Quality Data
After learning more about all of these companies, it’s easy to see the one challenge they all shared: the need for high-quality, reliable data throughout their whole pipeline. A company like Uber can’t afford a data quality issue that results in being dropped off at the wrong location or trying to get a ride from a driver that doesn’t exist.
That’s why all of these companies choose to build a data observability platform that can:
- Prevent costly data downtime by identifying and addressing data anomalies in real-time.
- Improve data quality and reliability by continuously monitoring pipelines.
- Enable scalable data architectures by scaling as the data architecture grows.
If you want something like this for yourself, pick Monte Carlo’s end-to-end data observability platform, which also comes with lineage tracking, automatic alerts, and AI-driven monitoring recommendations. Enter your email below to learn more.
Our promise: we will show you the product.
Read more posts.