 Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Freshness Explained: Making Data Consumers Wildly Happy
Table of Contents
What is data freshness and why is it important?
Data freshness, sometimes referred to as data timeliness, is the frequency in which data is updated for consumption. It is an important data quality dimension and a pillar of data observability because recently refreshed data is more accurate, and thus more valuable.
Since it is impractical and expensive to have all data refreshed on a near real-time basis, data engineers ingest and process most analytical data in batches with pipelines designed to update specific data sets at a similar frequency in which they are consumed.
Red Ventures director of data engineering, Brandon Beidel, talked to us about this process saying:
“We [would] start diving deep into discussions around data quality and how it impacted their day to day. I would always frame the conversation in simple business terms and focus on the who, what, when, where, and why. I’d especially ask questions probing the constraints on data freshness, which I’ve found to be particularly important to business stakeholders.”
For example, a customer churn Looker studio dashboard for a B2B SaaS company may only need to be updated once every 7 days for a weekly meeting whereas a marketing dashboard ingesting data from Google Analytics (Ga4), Google ads, LinkedIn, and other data sources may require daily updates in order for the team to optimize their digital campaigns.
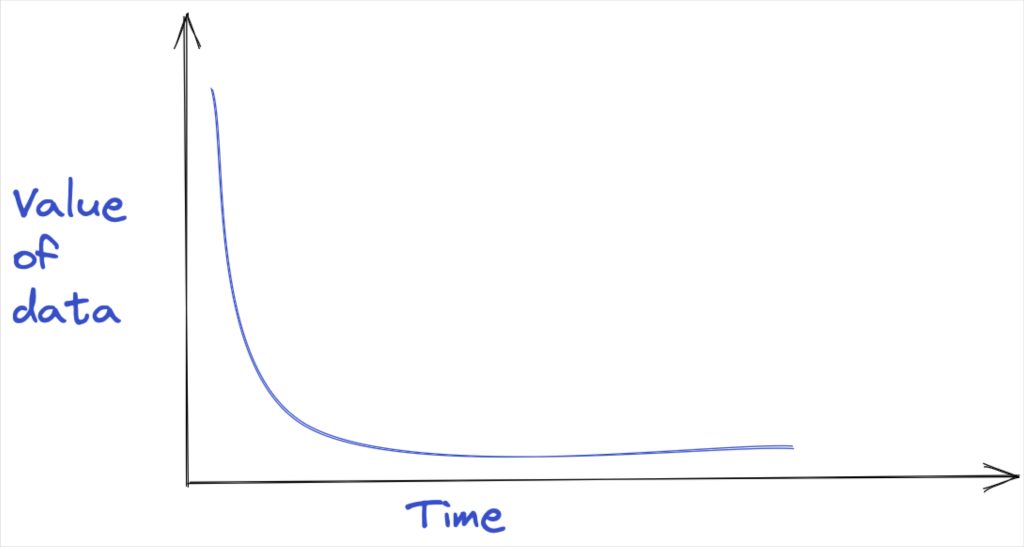
The consequences of ignoring data freshness can be severe. One ecommerce platform lost around $5 million in revenue because their machine learning model that identified out of stock items and recommended substitutions was operating on thousands of temporary tables and stale data for six months.
Pro-tip: Don’t confuse data freshness with data latency. Data latency is the time between when the event occurs and when the data is available in the core data system (like a data warehouse) whereas data freshness is how recently the data within the final asset (table, BI report) has been updated.
In this post, we will cover how to measure data freshness as well as best practices and challenges experienced by real data teams. The best practices section contains example data freshness checks you can integrate immediately to alert you if your key reports go stale. Let’s dive in.
Table of Contents
How to measure data freshness for data quality
As previously mentioned, the required level of data freshness is completely contextual to the use case.
One way data teams measure data freshness is by the number of complaints they receive from their data consumers over a period of time. While this is a customer focused approach, it is reactive and has serious disadvantages such as:
- Corroding data trust;
- Delaying decision making and the pace of business operations;
- Requiring a human in the loop that is familiar with the data (not always the case when powering machine learning models); and
- If data is external and customer facing it creates a risk of churn.
A better measurement is the data downtime formula (above), which more comprehensively measures the amount of time the data was inaccurate, missing, or otherwise erroneous.
A proactive approach for measuring data freshness is to create service level agreements or SLAs for specific data pipelines. We’ve written a step by step guide for creating data SLAs, but in summary:
- Identify your most important data tables based on the number of read/writes or their monetary impact on the business.
- Identify the business owners of those data assets. In other words, who will be most impacted by a data freshness or other data quality issue?
- Ask them how they use their data and how frequently they access it. Create a SLA that specifies how frequently and when the data asset will be refreshed.
- Implement a means of monitoring when the SLA has been breached and measure how frequently the SLA has been met over a period of time. This can be done through data testing or by using a data observability platform.
The end result should look something like, “The customer_360 dashboard met its daily data freshness SLA 99.5% of the time over the last 30 days, a 1% increase over the previous 30 days.”
Data freshness challenges
Data teams face numerous challenges in their data freshness quest as a result of the scale, speed, and complexity of data and data pipelines. Here are a few examples:
- Data sources are constantly changing: Whether internal or external, data engineers are rarely in control of the source emitting the desired data. Changes in schedule or schema during the data integration process can break data pipelines and create data freshness issues. Data cache details can create query nuances.
- Data consumption patterns change a lot too: Strategies are adapted, metrics evolve, and departments are reorganized. Without capabilities such as data lineage it can be difficult to understand what is a key asset (or upstream of an important data product in the context of a data mesh) and what is obsolete clutter. Outside of the smallest companies, identifying relevant data consumers and business stakeholders for each asset is also extremely challenging. This creates a communication chasm between the data and business teams.
- Data pipelines have a lot of failure points: The more complex moving parts a machine has, the more opportunities for it to break. Data platforms are no exception. The ingestion connector could break, the orchestration job could fail, or the transformation model could be updated incorrectly.
- Fixing data freshness issues takes a long time: Because there are so many moving parts, troubleshooting data freshness incidents can take data engineers hours–even days. The root cause could be hidden in endless blocks of SQL code, a result of system permission issues, or just a simple data entry error.
Data freshness best practices
Once you have talked with your key data consumers and determined your data freshness goals or SLAs, there are a few best practices you can leverage to provide the best service or data product possible.
The first step is to architect your data pipeline so that the goal is technically feasible (low latency). This is typically a data ingestion decision between batch, microbatch, or stream processing. However, this could impact any decisions regarding complex transformation models or other data dependencies as well.
Pro-tip: When you are asking about data freshness be sure to also ask about overall data quality as well. While not always the case, near-real time data generally comes with a data quality tradeoff.
At this point, you will want to consider layering approaches for detecting, resolving, and preventing data freshness issues. Let’s look at each in turn.
Detecting data freshness issues
One of the simplest ways to start detecting data freshness issues is to write a data freshness check (test) using SQL rules.
For example, let’s assume you are using Snowflake as your data warehouse and have integrated with Notification Services. You could schedule the following query as a Snowflake task which would alert you Monday through Friday at 8:00am EST when no rows had been added to “your_table” once you have specified the “date_column” with a column that contains the timestamp when the row was added.
CREATE TASK your_task_name
WAREHOUSE = your_warehouse_name
SCHEDULE = 'USING CRON 0 8 * * 1-5 America/New_York'
TIMESTAMP_INPUT_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
AS
SELECT
CASE WHEN COUNT(*) = 0 THEN
SYSTEM$SEND_SNS_MESSAGE(
'your_integration_name',
'your_sns_topic_arn',
'No rows added in more than one day in your_table!'
)
ELSE
'Rows added within the last day.'
END AS alert_message
FROM your_table
WHERE date_column < DATEADD(DAY, -1, CURRENT_DATE());The query above looks at rows added but you could instead use a similar statement to make sure there is at least something matching the current date. Of course, both of these simple checks can be prone to error.
CREATE TASK your_task_name
WAREHOUSE = your_warehouse_name
SCHEDULE = 'USING CRON 0 8 * * 1-5 America/New_York'
TIMESTAMP_INPUT_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
AS
SELECT
CASE WHEN DATEDIFF (DAY, max(last_modified), current_timestamp()) > 0 THEN
SYSTEM$SEND_SNS_MESSAGE(
'your_integration_name',
'your_sns_topic_arn',
'No rows added in more than one day in your_table!'
)
ELSE
'Max modified date within the last day.'
END AS alert_message
FROM your_table;The transformation tool dbt is also a popular mechanism for testing data freshness. You could also use a dbt source freshness block:
sources:
- name: your_source_name
database: your_database
schema: your_schema
tables:
- name: your_table
freshness:
warn_after:
count: 1
period: day
loaded_at_field: date_column
These are great data anomaly detection tools and tactics to use on your most important tables, but what about the tables upstream from your most important tables? Or what if you don’t know the exact threshold? What about important tables you are unaware of or failed to anticipate a freshness check was needed?
The truth is data freshness checks don’t work well at scale (more than 50 tables or so). A better option is to build your own data freshness machine learning monitor, and the best option is to evaluate a data observability platform.
One of the benefits of a data observability platform with data lineage is that if there is a data freshness problem in an upstream table that then creates data freshness issues in dozens of tables downstream, you get one cohesive alert for comprehensive analysis rather than disjointed pings telling you your modern data stack is on fire.
Resolving data freshness issues
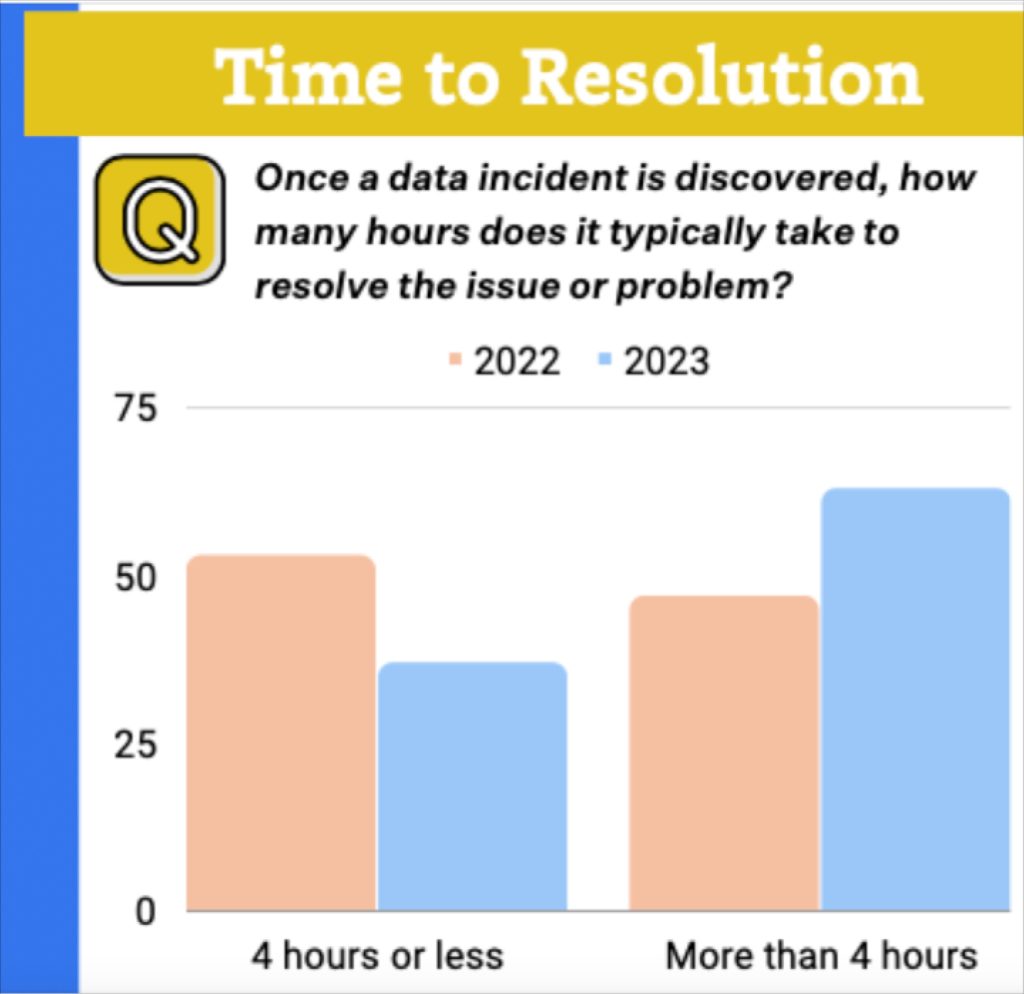
The faster you resolve data freshness incidents the less data downtime and cost you incur. Solve the data freshness issue quick enough and it may not even count against your SLA.
Unfortunately, this is the most challenging part of dealing with data freshness issues. As previously mentioned, data can break in a near infinite amount of ways. This leaves two options.
- You can manually hop from tab to tab checking out the most common system, code, and data issues. However, this takes a lot of time and doesn’t guarantee you find the root cause. Our recent survey found it took respondents an average of 15 hours to resolve data incidents once detected!
- A data observability platform can help teams resolve data freshness issues much quicker with capabilities such as data lineage, query change detection, correlation insights for things like empty queries, and more.
Preventing data freshness issues
Unfortunately, bad data and data freshness issues are a fact of life for data teams. You can’t out-architect bad data. However, you can reduce the number of incidents by identifying and refactoring your problematic data pipelines.
Another option, which is a bit of a double-edged data freshness sword, is data contracts. Unexpected schema changes are one of the most frequent causes (along with failed Airflow jobs) of stale data.
A data contract architecture can encourage software engineers to be more aware of how service updates can break downstream data systems and facilitate how they collaborate with data engineers. However, data contracts also prevent this bad data from landing in the data warehouse in the first place so they can cut both ways.
The bottom line: make your data consumers wildly happy with fresh data
When you flip a light switch you expect there to be light. When your data consumers visit a dashboard they expect the data to be fresh–it’s a baseline expectation.
Prevent those nasty emails and make your data consumers wildly happy by ensuring when they need the data, it is available and fresh. Good luck!
Want to see how data observability can help detect, resolve, and prevent data freshness issues? Fill out the form below to schedule a demo!
Our promise: we will show you the product.
Read more posts.





