Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Ultimate Guide To Data Lineage

Glen Willis
Glen is the Founding Solutions Architect at Monte Carlo. Previously, he was a solutions architect at Mixpanel. He graduated from U.S.C. with a B.S. and an M.S. in Product Development Engineering.
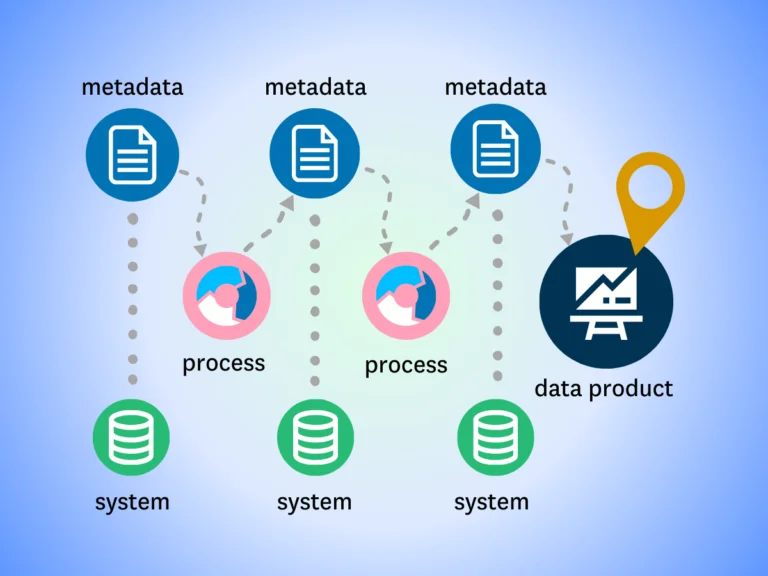
Data lineage is a metadata map that traces the relationship between upstream and downstream dependencies in your data pipelines to illustrate where your data comes from, how it changes, and where it’s surfaced to end users.
Let’s take a look at what enterprise data lineage is in practice and how it supports your data quality.
Table of Contents
What is Data Lineage?
In layman’s terms, data lineage is all about mapping: where your data comes from, how it changes as it moves throughout your pipelines, and where it’s surfaced to your end consumers. When done right, data lineage can be a super power for your data engineering teams.
Sometimes confused with data mapping, which is the process of combing data fields across models, data lineage instead provides a visualization of how the data moves within an environment.
Enterprise data lineage solutions help data teams:
- Understand how changes to specific assets will impact downstream dependencies, so they don’t have to work blindly and risk unwelcome surprises for unknown stakeholders.
- Troubleshoot the root cause of data issues faster when they do occur by making it easy to see at-a-glance what upstream errors may have caused a report to break.
- Communicate the impact of broken data to consumers who rely on downstream reports and tables—proactively keeping them in the loop when data may be inaccurate and notifying them when any issues have been resolved.
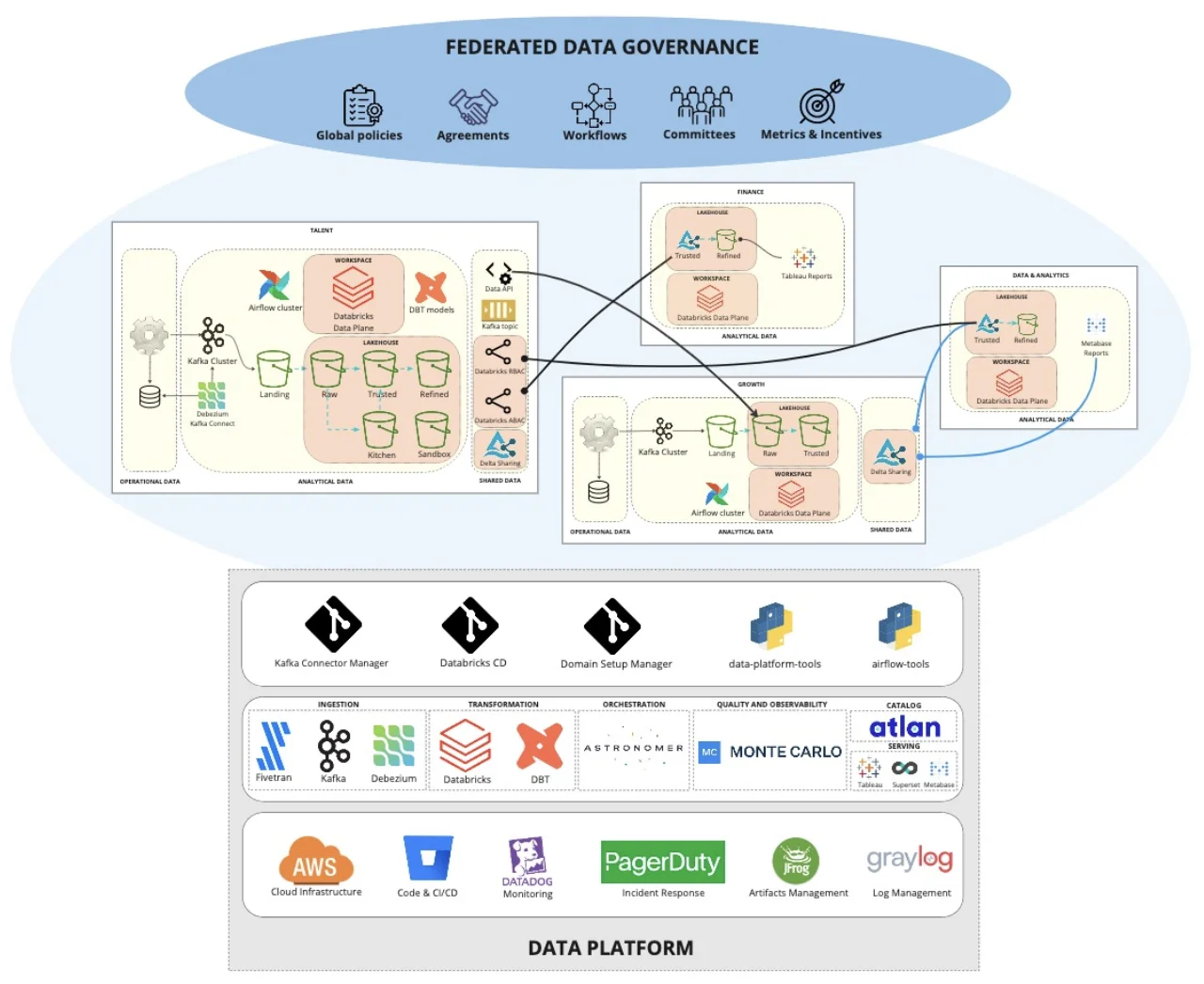
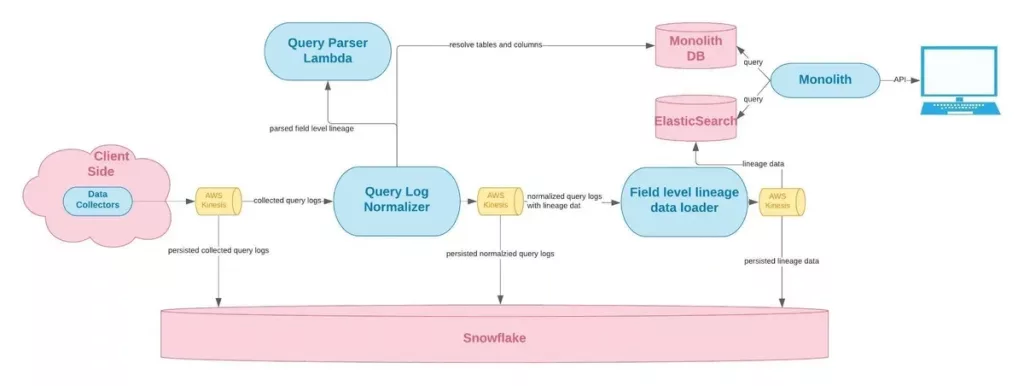
The data lineage life cycle shows at-a-glance how data is collected and activated to help data teams understand and monitor upstream and downstream dependencies. While data lineage isn’t new to the modern data stack, in the old days (say the mid-2010s or so), enterprise lineage was still an aggressively manual process.
Producing data lineage required identifying your data assets, tracking those assets from ingestion sources, documenting all those sources, mapping the path of data as it moved through various pipelines and transforms, and finally pinpointing where the data was being served up in dashboards and reports.
In its manual form, lineage was a burden at the best of times. But as data stacks grew more complex, lineage maps became nearly impossible to maintain. These days, thanks to the introduction of automated column level data lineage tooling, mapping dependencies across pipelines has become accessible for the first time.
What are the two types of data lineage?
Data lineage comes in two primary forms; table-level lineage and column-level lineage (also known as field-level lineage).
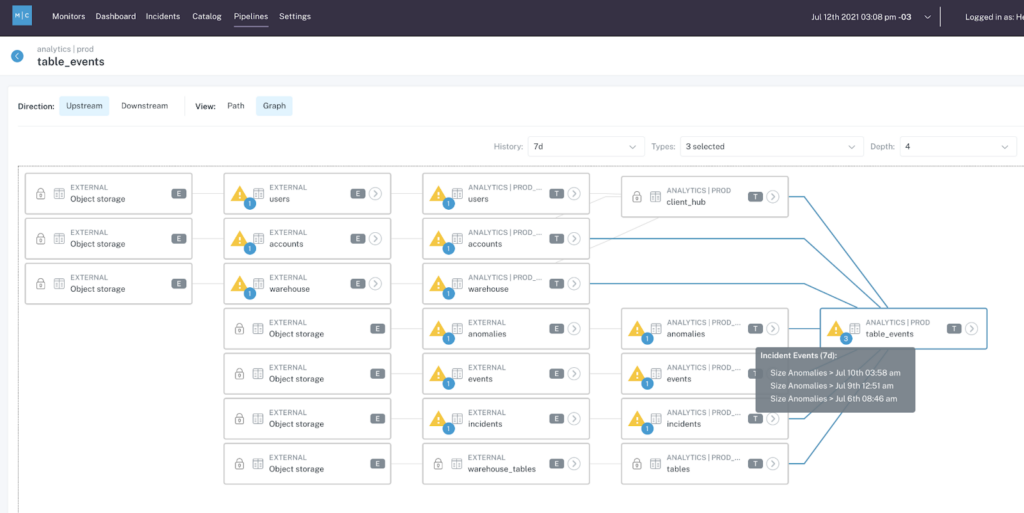
Table-level lineage is the simplest and most common form of data lineage, and it illustrates how various tables within a data environment relate to one another. While this can be helpful to understand how a given table has been formed, it can’t tell you about about the origin of the data within the table.
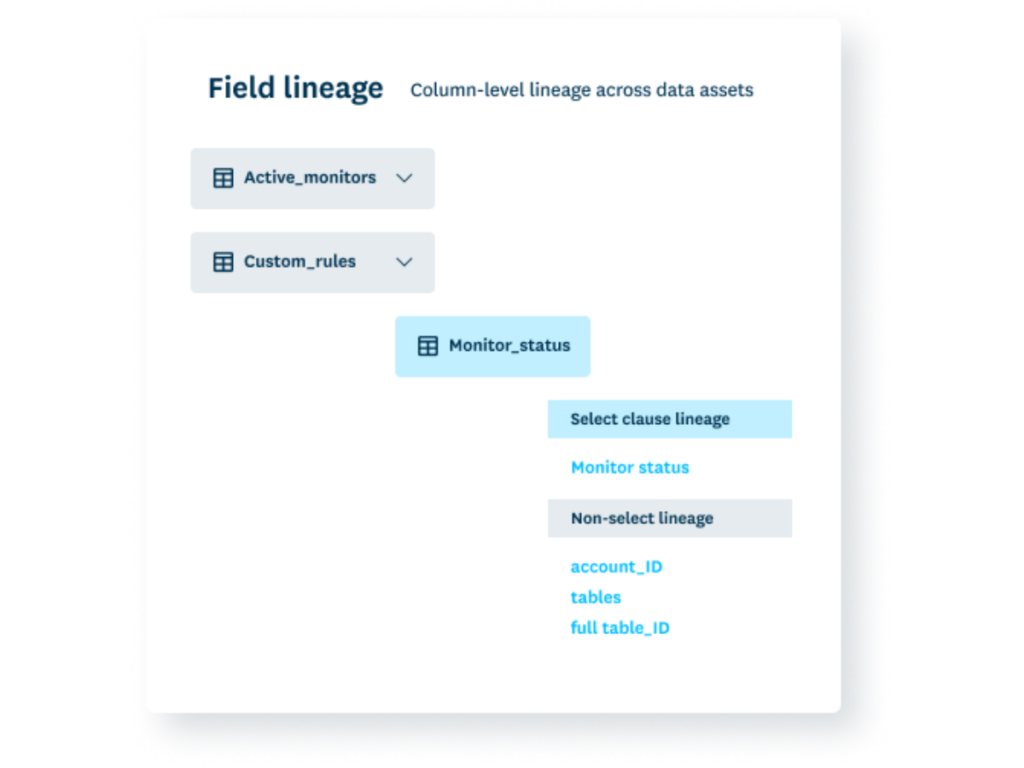
Column-level data lineage on the other hand is a map of a dataset’s path from ingestion to visualization. Column-level lineage is an essential component of Data Observability because it empowers data engineers to quickly trace the root cause of a data quality incident back to its source and conduct impact analysis to discover what downstream dependencies might be affected.
What’s the difference between data lineage and traceability?
While both data lineage and traceability are concerned with tracing the origins of data, these two practices differ in their overall purpose and audience.
Data lineage, which tends to be very technical is concerned primarily with supporting pipeline optimization and root-cause analysis through a detailed map of how data is ingested, transformed, and activated across a data environment. Traceability, on the other hand, tends to serve the specific needs of a given business domain, and it primarily concerned with validating the origins and accuracy of information for compliance and usage insights.
While traceability can be leveraged by any team depending on it’s needs, data lineage is often only useful for technical users like data product managers and platform engineers.
Why is Data Lineage Important?
Data lineage is the key to efficient incident resolution. By understanding the upstream and downstream dependencies of our tables, we can more quickly understand the impact, notify stakeholders, and remediate data data breaks should an incident arise.
Machine learning has enabled vendors to offer data lineage at scale in a way that was previously impossible through manual processes. And that’s a good thing.
But just because something is easier doesn’t mean it’s always better.
Even with a proliferation of new tooling, if data lineage isn’t handled carefully, it’s unlikely to be much more than eye candy. And unfortunately, some new approaches to data lineage focus more on attractive graphs than compiling a rich, useful map.
Unlike the end-to-end lineage achieved through data observability, these surface-level approaches don’t provide the robust functionality and comprehensive, field-level coverage required to deliver on the value promise of data lineage.
Is data lineage necessary for every data team?
The short answer is yes. If you are a data team who plans to take data reliability seriously and scale your data quality practice, data lineage is an essential tool in your data quality tool belt.
While some data teams with relatively small environments can survive by manually parsing data whenever a data anomaly gets flagged, that will only work for as long as that data remains small. Manually tracing the lineage of 5 tables with 7 data sources isn’t the same as manually tracing the lineage of 100 tables across 50 data sources for assets that are being consumed by 5 different domain teams.
Enterprise data lineage enables teams to scale data quality, and provides enterprise data teams with the resources they need to effectively resolve data quality incidents and reduce the impact of data downtime. Data lineage can also communicate the impact radius of a given data quality incident, so you understand what data assets have been effected, who’s using them, and what to keep an eye on as you begin the incident manage process.
Without data lineage, growing data teams are fighting data quality fires with their hands behind their backs.
Let’s explore five things your data team can do today to get more value from your data lineage—and where modern data lineage gets it wrong.
5 Ways to Get More Value From Data Lineage
1. Focus on quality over quantity through lineage
Modern companies are hungry to become data-driven, but collecting more data isn’t always what’s best for the business. Data that isn’t relevant or useful for analytics can just become noise. Amassing the biggest troves of data doesn’t automatically translate to more value—but it does guarantee higher storage and maintenance costs.
That’s why big data is getting smaller. Gartner predicts that 70% of organizations will shift their focus from big data to small and wide data over the next few years, adopting an approach that reduces dependencies while facilitating more powerful analytics and AI.
Lineage should play a key role in these decisions. Rather than simply using automation to capture and produce surface-level graphs of data, lineage solutions should include pertinent information such as which assets are being used and by whom. With this fuller picture of data usage, teams can begin to get a better understanding of what data is most valuable to their organization. Outdated tables or assets that are no longer being used can be deprecated to avoid potential issues and confusion downstream, and help the business focus on data quality over quantity.
2. Surface what matters through field-level data lineage
Petr Janda recently published an article about how data teams need to treat lineage more like maps—specifically, like Google Maps. He argues that lineage solutions should be able to facilitate a query to find what you’re looking for, rather than relying on complex visuals that are difficult to navigate through.
For example, you should be able to look for a grocery store when you need a grocery store, without your view being cluttered by the surrounding coffee shops and gas stations that you don’t actually care about. “In today’s tools, data lineage potential is untapped,” Petr writes. “Except for a few filters, the lineage experiences are not designed to find things; they are designed to show things. That’s a big difference.”
We couldn’t agree more. Data teams don’t need to see everything about their data—they need to be able to find what matters to solve a problem or answer a question.
This is why field-level lineage is essential. While table-level lineage has been the norm for several years, when data engineers want to understand exactly why or how their pipelines break, they need more granularity. Field-level lineage helps teams zero in on the impact of specific code, operational, and data changes on downstream fields and reports.
When data breaks, field-level lineage can surface the most critical and widely used downstream reports that are impacted. And that same lineage reduces time-to-resolution by allowing data teams to quickly trace back to the root cause of data issues.
3. Organize data lineage for clearer interpretation
Data lineage can follow in the footsteps of Google Maps in another way: by making it easy and clear to interpret the structure and symbols used in lineage.
Just as Google Maps uses consistent icons and colors to indicate types of businesses (like gas stations and grocery stores), data lineage solutions should apply clear naming conventions and colors for the data it’s describing, down to the logos used for the different tools that make up our data pipelines.
As data systems grow increasingly complex, organizing lineage for clear interpretation will help teams get the most value out of their lineage as quickly as possible.
4. Include the right context in data lineage
While amassing more data for data’s sake may not help meet your business needs, collecting and organizing more metadata—with the right business context—is probably a good idea. Data lineage that includes rich, contextual metadata is incredibly useful because it helps teams troubleshoot faster and understand how potential schema changes will affect downstream reports and stakeholders.
With the right metadata for a given data asset included in the lineage itself, you can get the answers you need to make informed decisions:
- Who owns this data asset?
- Where does this asset live?
- What data does it contain?
- Is it relevant and important to stakeholders?
- Who is relying on this asset when I’m making a change to it?
When this kind of contextual information about how data assets are used within your business is surfaced and searchable through robust data lineage, incident management becomes easier. You can resolve data downtime faster, and communicate the status of impacted data assets to the relevant stakeholders in your organization.
5. Scale data lineage to meet the needs of the business
Ultimately, enterprise data lineage has to be rich, useful, and scaleable in order to be valuable. Otherwise, it’s just eye candy that looks nice in executive presentations but doesn’t do much to actually help teams prevent data incidents or resolve them faster when they do occur.
We mentioned earlier that lineage has become the hot new layer in the data stack because of automation. And it’s true that automation solves half of this problem: it can help lineage scale to accommodate new data sources, new pipelines, and more complex transformations.
The other half? Making lineage useful by integrating metadata about all your data assets and pipelines in one cohesive view.
Again, consider maps. A map isn’t useful if it only shows a portion of what exists in the real world. Without comprehensive coverage, you can’t rely on a map to find everything you need or to navigate from point A to point B. The same is true for data lineage.
Enterprise data lineage solutions must scale through automation without skimping on coverage. Every ingestor, every pipeline, every layer of the stack, and every report must be accounted for, down to the field level—while being rich and discoverable so teams can find exactly what they’re looking for, with a clear organization that makes information easy to interpret, and the right contextual metadata to help teams make swift decisions.
Like we said: lineage is challenging. But when done right, it’s also incredibly powerful.
Common Data Lineage Tools
If you’re just getting started with data lineage, you might be curious what open-source data lineage tools are available. Unsurprisingly, open source tooling is a go-to for many budget-conscious teams. While this approach certainly has its drawbacks (which we’ll get to in a minute), there are definitely a few open source tools that might be up to the challenge—at least for a little while.
Some of the top open source data data lineage tools include:
- OpenMetadata: OpenMetadata is an accessible lineage solution that’s designed to enable coding-limited users to easily create a lineage map without sacrificing the granularity data professionals need to understand complex data transformations.
- Open Lineage + Marquez: OpenLineage isn’t technically a tool, but it’s an open standard for metadata and data lineage collection that recommends the open-source tool Marquez to collect, aggregate and visualize metadata for lineage. Marquez itself offers a relatively user-friendly UI that’s easy to understand and provides a robust API that can be integrated with a variety of data sources and tools to help automate key tasks like backfills and root cause analysis.
- Egeria: This one also isn’t a tool, but it provides open APIs, event formats, types, and integration logic to enable metadata features that make it useful for managing data lineage.
- Apache Atlas: While it bills itself as an open-source metadata management and governance tool, Apache Atlas can be used to track and manage data lineage. Atlas’ UI allows you to view the lineage of data as it moves through various processes and there is a set of REST APIs that allow you to access and update data lineage information.
- Spline: An Apache Spark project that was expanded to accommodate data lineage for other data sources. Spline offers APIs to both collect and query data lineage data. Spline supports an OpenLineage integration and it also provides a web UI to display stored lineage information and view lineage in different levels of detail.
Just keep in mind that while there are several options available in the realm of open-source data lineage tools, implementation can definitely be a challenge. An open-source solution might be a good compromise to get you started on a budget, but you’re likely to run into some pretty severe bottlenecks as your needs—and your platform—continues to grow.
When that time comes, you’ll probably be better off looking at something like a data observability solution that programmatically marries lineage and monitoring to better support the detection, resolution, and prevention of your data quality issues in a more holistic way.
Bottom line: if enterprise data lineage isn’t useful, it doesn’t matter
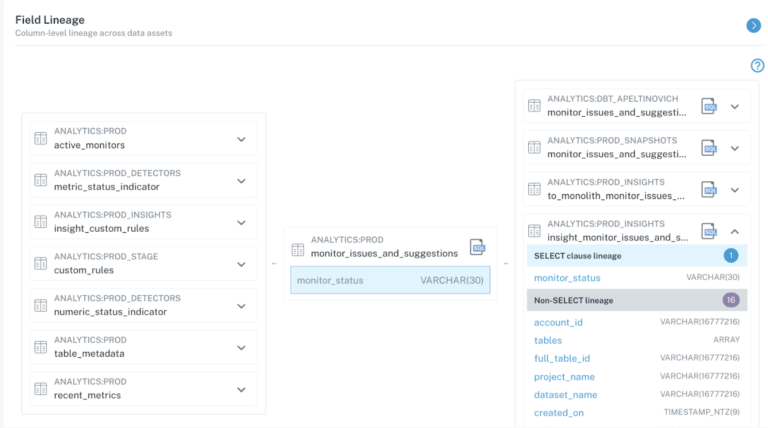
Even though it seems like data lineage is everywhere right now, keep in mind that we’re also in the early days of automated data lineage. Data lineage tools--whether Collibra, Informatica, Amundsen, Octopai, Monte Carlo, or others--will continue to be refined and improved, and as long as you’re armed with the knowledge of what high-quality lineage should look like, it will be exciting to see where the industry is headed.
Our hope? The category will become less about attractive data lineage graphs and more about powerful functionality, like the next Google Maps.
Want to see the power of data lineage in action? Learn how the data engineering team at Resident uses lineage and data observability to reduce data incidents by 90%. And if you’d like to explore end-to-end lineage with Monte Carlo, contact our team. We’d love to share our approach to improving data quality through truly meaningful lineage at scale.
Interested in learning more about automated data lineage? Book a time to speak with us in the form below.
Our promise: we will show you the product.
Frequently Asked Questions
What is the difference between data lineage and data flow?
Data lineage focuses on tracing the origins, movements, and transformations of data across its lifecycle, showing how data flows from source to destination. Data flow, on the other hand, describes the actual movement of data between systems or components within a pipeline.
Why do you need data lineage?
You need data lineage to understand the origins and transformations of your data, ensure data quality, troubleshoot data issues faster, and maintain compliance with data governance policies. It also helps in impact analysis and improving communication with stakeholders.
What happens if you don't establish the lineage of data you are using?
Without establishing data lineage, you risk facing difficulties in troubleshooting data issues, understanding data dependencies, ensuring data quality, and maintaining compliance. This can lead to data errors, inefficient data management, and a lack of trust in data accuracy.
What is the difference between data lineage and data audit?
Data lineage maps the flow and transformation of data across its lifecycle, focusing on data dependencies and transformations. Data audit, however, involves reviewing and verifying data to ensure it meets specified standards and regulations, often focusing on data accuracy and quality.
How do you explain data lineage?
Data lineage is the process of mapping and visualizing the flow of data from its source to its destination, including all transformations and processes it undergoes. It helps in understanding the data's journey, ensuring accuracy, and tracing the impact of changes or issues.
What are the components of data lineage?
The components of data lineage include data sources, data transformations, data destinations, metadata, and dependencies between different data elements. These components collectively illustrate how data flows and changes across various systems and processes.
What are data lineage diagrams?
Data lineage diagrams are visual representations that map the flow of data from its origins to its final destination, showing all the transformations and processes it undergoes along the way. These diagrams help in understanding data dependencies, ensuring data quality, and troubleshooting issues.
Read more posts.