Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Observability: So Hot Right Now

Monte Carlo launched the data observability category back in 2019, and over the last five years, data observability has been on a steady rise—from data quality nice-to-have to an essential component of your data and AI reliability strategy.
Now, with the rise of AI poised to upset the data quality apple-cart, companies have never been more bullish about data observability.
Boasting 350+ customers and leadership titles in analyst publications from G2, Ventana, GigaOm, and more, Monte Carlo is no doubt the category leader. But with every software provider from data infra companies to devops in a rush to deploy their own native data observability tools, it begs the question:
Why would you need a dedicated data observability solution? And does it matter if you go with the leader?
Let’s take a look at how data observability is a must-have for your next-gen data and AI platform—and why a dedicated solution from the category leader is the right choice for the long haul.

What makes data observability different?
Data quality tools are nothing new. Data testing, data profiling—even ML-based anomaly detection have been around for ages. What makes data observability different is that it’s not a one-to-one data quality tool—it’s an end-to-end data reliability solution.
Unlike manual data quality tooling, data observability isn’t interested in simply detecting a few specific data quality issues—data observability is designed to help data teams improve the health of their entire data and AI pipeline—from ingestion right down to consumption.
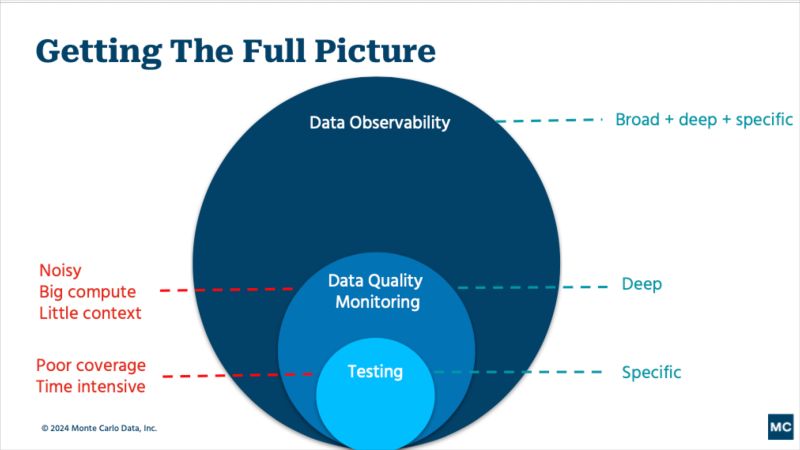
Data observability provides:
- End-to-end, vendor agnostic coverage
- The power to detect, triage, resolve, and measure data reliability in a single platform
- And 100% dedicated data quality expertise so you always have the right coverage available at the right time
Data observability enables overworked data teams to maintain data reliability at every scale—from 10 tables to 10,000—so, you can detect issues sooner, resolve issues faster, and help your stakeholders realize the value of and increase trust in their data.
But can a native solution do all that? Let’s talk about it.
Why you need a dedicated data observability solution
As the data quality problem becomes more and more salient, every platform will be looking for a bigger piece of the pie. Unfortunately, data reliability isn’t a pie everyone can digest.
When it comes to software downtime, developers have a myriad of observability options, including AWS’ own Cloud Watch. But when teams get serious about software downtime, they still turn to dedicated solutions like Datadog. Why?
Any sushi restaurant can add a cheeseburger to their menu—but that doesn’t mean it’ll be any good. The same holds true for in-app data quality tools.
Let’s consider a few of the challenges of these native solutions:
Point solutions don’t provide end-to-end coverage
The primary conceit of data observability is that it provides end-to-end coverage. Anything less and it isn’t data observability.
Unfortunately, in-app tools aren’t designed to play nice with others. A transformation tool might be able to detect a bad transform, but what if the data was wrong before it landed? Even the leading cloud data warehouse and lakehouse platforms are taking a walled garden approach to data quality, creating tools that cover a specialized point in the pipeline but neglect the problems upstream and downstream of their domain.
So, what should you do? Should you buy and manage a separate tool for every step of your pipelines? Observability for transforms? Observability for data lakes? Observability for orchestration? How many point solutions can you realistically maintain? How many would you want to?
More than that, if the only tool observing a given layer of your stack is the vendor who supplied it, how can you know for certain it’s accurate?
A tool designed for a single point in your pipeline will always have more blindspots than solutions.
Point solutions aren’t extensible
Remember that a key component of data observability is extensibility. Far from being vendor-agnostic, point solutions are inextensible by design.
What happens if you need to migrate? Will your data quality checks be compatible in a new environment? What happens if something breaks during the migration?
In-app data quality solutions don’t make teams more flexible. They make data quality more precarious.
Point solutions aren’t future-proof
Any team can develop a feature—but it takes a dedicated team to make it valuable.
When it comes to major platform providers, data quality probably isn’t their third or even their fourth priority. So, as the AI stack begins to take form and new data quality needs come into focus, point-solutions aren’t likely to be the first to the party—if they show up at all.
And, when budgets get cut or teams get right-sized, you can be sure that maintaining a data quality tool won’t be at the top of their priority list.
While there’s a shadow of wisdom in a full-stack approach, it’s always more risk than its worth. When teams get serious about data downtime, they need a mature data observability solution.
Why you should invest in the category leader
When you’re in a race, the best horse to choose is the one that’s winning. By investing in the leading standalone, data teams guarantee they’re getting a focused best-in-class solution that will be viable for the long haul.
At Monte Carlo, data observability isn’t just a component of our product—it is our product.
Since the day Monte Carlo coined the term, our team has been setting the standard for what it means to observe your data. As the single largest data observability provider in the space, Monte Carlo has more customers, more integrations, and more sophistication than any other data observability solution. Which is why we’ve claimed the top spot for data observability with every software analyst from G2 to Ventana and Gigaom.
In fact, we literally wrote the book on it—publishing the two leading books on data observability: O’Reilly’s DQ Fundamentals and The Dummies Guide to Data Observability.
And we haven’t just been building data observability for our customers—we’ve been building it with our customers. Nearly every feature or product update we release is designed specifically for a real customer, so our customers always have the features they need, when and how they need them.
It’s easy to celebrate a new feature in pre-sales that will never get used in post. At Monte Carlo, we never create solutions and then look for problems; we find out what problems our customers have—and then we get to work solving them.
As the definitive data observability category leader, Monte Carlo is in the best position to make you successful. And with as much humility as we can muster, if we can’t do it, no one can.
What’s next for data observability?
Any team can create a data quality tool. It takes a dedicated team to make it valuable. Fortunately, at Monte Carlo, helping data teams solve their data quality challenges isn’t just one of our priorities—it’s our only priority.
As AI becomes more and more critical to the operations and outputs of enterprise data teams, developing the right features to enable data reliability at scale is a level one challenge.
From support for vector databases like Pinecone to observability for streaming data, Monte Carlo is wholly committed to accelerating the future of reliable data and AI.
Over the coming months, Monte Carlo will continue to refine and streamline our data observability solution to help data teams deliver reliable data products faster, easier, and with less resources, so that teams can focus their attention on delivering more value in the data and AI race.
Don’t bring a second-tier solution to a first-tier problem. Invest in the category leader and get the data observability solution of tomorrow today.
Have a feature or integration that you’d like to see? Grab some time with our team and let us know!
Read more posts.