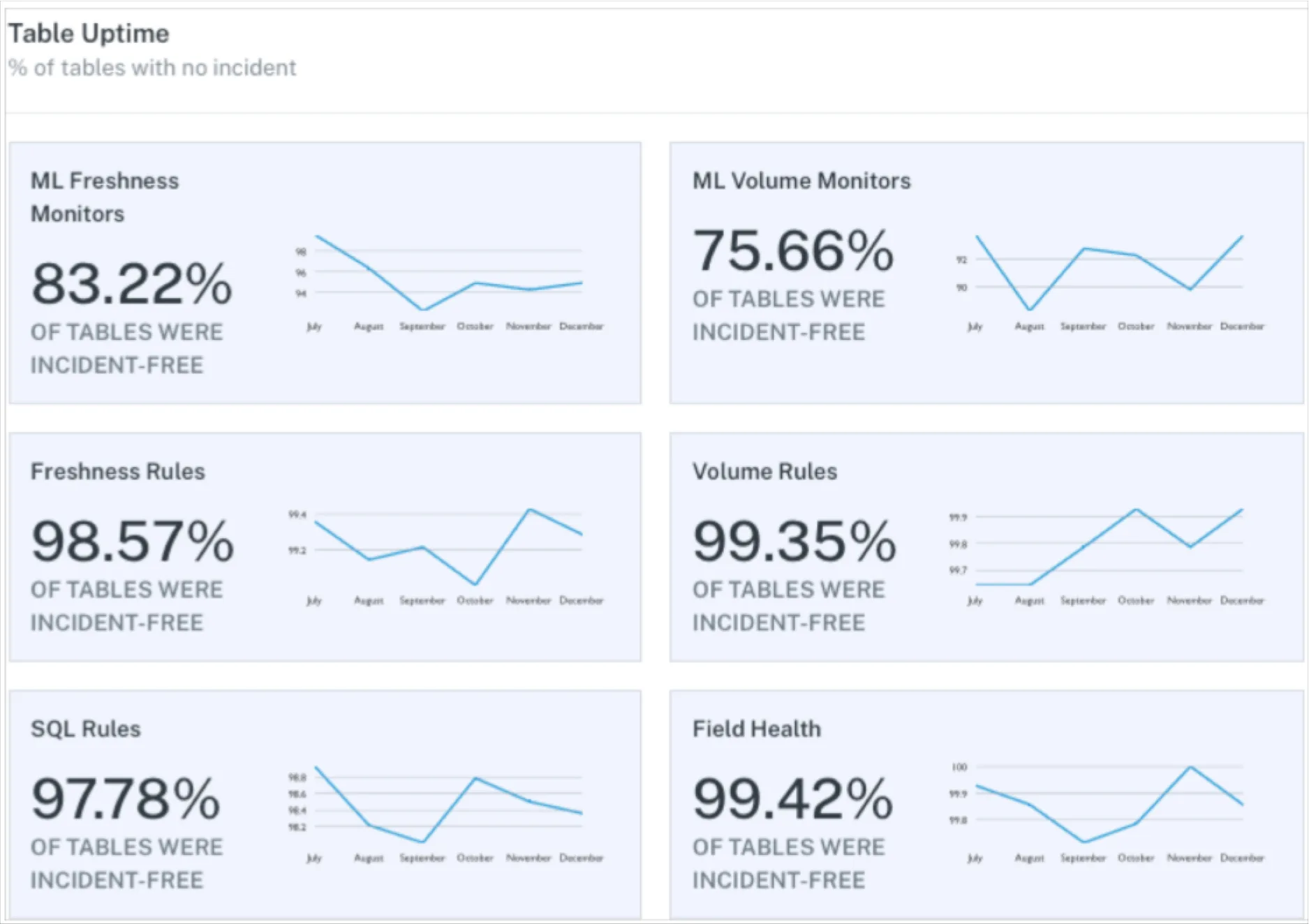
Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Quality Testing: 7 Essential Tests


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Getting started with data quality testing? Here are the 7 must-have checks to improve data quality and ensure reliability for your most critical assets.
When it comes to data engineering, data quality issues are a fact of life.
According to Gartner, bad data costs organizations on average an estimated $12.9 million per year. In fact, Monte Carlo’s own research found that data engineers spend as much as 40% of their workday firefighting bad data.
Those are some big numbers. Data quality issues are some of the most pernicious challenges facing modern data teams, and testing is one of the very first steps a data team will take on their journey to reliable data.
Whether by mistake or entropy, anomalies are bound to occur as your data moves through your production pipelines. In this post, we’ll look at 7 essential data quality tests you need right now to validate your data, plus some of the ways you can apply data quality testing today to start building out your data quality motion.
Table of Contents
So, what is data quality testing?
Like all software and data applications, ETL/ELT systems are prone to failure from time-to-time. So, data quality testing is the process of validating that key characteristics of a dataset match what’s expected prior to consumption by downstream users.
Among other factors, data pipelines are reliable if:
- The data is current, accurate, and complete.
- The data is unique and free from duplicates.
- The model is sound and represents reality.
- And the transformed data is free from anomalies.
While there’s no silver bullet for data quality issues, data quality testing—also known as ETL testing—empowers engineers to anticipate specific, known problems and write logic to proactively detect quality issues before they can impact downstream users.
So, now that we have a common understanding of what data quality testing is, let’s look at some of the most common data quality tests you can run right now and how they might be used to quality detect issues in your data.
NULL values test
One of the most common data quality issues will arise from missing data, also known as NULL values. (Oh, those pesky NULL values).
NULL values occur when a field is left blank, either intentionally or through a pipeline error, such as those caused by an API outage. Let’s say you were querying the impact of a marketing program on sales lift by region, but the ‘region’ field was left blank on multiple records. Any rows where ‘region’ was missing would necessarily be excluded from your report, leading to inefficient future spend on regional marketing programs. Not cool.
As the name implies, a NULL values test will validate whether values within a specified column for a particular model are missing after the model runs. One excellent out-of-the-box test for uncovering NULL values is dbt’s generic not_null test.
tests/test_not_null.sql
Freshness checks
All data definitely has a shelf life. When data is being refreshed at a regular cadence, the data paints an accurate picture of the data source. But when data becomes stale or outdated, it ceases to be reliable, and therefore, useful for downstream consumers.
And you can always count on your downstream consumers to notice when their dashboards aren’t being refreshed.
Data freshness checks validate the quality of data within a table by monitoring how frequently that data is updated against predefined latency rules, such as when you expect an ingestion job to load on any given day.
Data freshness tests can be created manually using SQL rules. For example, let’s assume you are using Snowflake as your data warehouse and have integrated with Notification Services. You could schedule the following query as a Snowflake task which would alert you Monday through Friday at 8:00am EST when no rows had been added to “your_table” once you have specified the “date_column” with a column that contains the timestamp when the row was added.
CREATE TASK your_task_name
WAREHOUSE = your_warehouse_name
SCHEDULE = 'USING CRON 0 8 * * 1-5 America/New_York'
TIMESTAMP_INPUT_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
AS
SELECT
CASE WHEN COUNT(*) = 0 THEN
SYSTEM$SEND_SNS_MESSAGE(
'your_integration_name',
'your_sns_topic_arn',
'No rows added in more than one day in your_table!'
)
ELSE
'Rows added within the last day.'
END AS alert_message
FROM your_table
WHERE date_column < DATEADD(DAY, -1, CURRENT_DATE());The query above looks at rows added but you could instead use a similar statement to make sure there is at least something matching the current date. Of course, both of these simple checks can be prone to error.
CREATE TASK your_task_name
WAREHOUSE = your_warehouse_name
SCHEDULE = 'USING CRON 0 8 * * 1-5 America/New_York'
TIMESTAMP_INPUT_FORMAT = 'YYYY-MM-DD HH24:MI:SS'
AS
SELECT
CASE WHEN DATEDIFF (DAY, max(last_modified), current_timestamp()) > 0 THEN
SYSTEM$SEND_SNS_MESSAGE(
'your_integration_name',
'your_sns_topic_arn',
'No rows added in more than one day in your_table!'
)
ELSE
'Max modified date within the last day.'
END AS alert_message
FROM your_table;You could also use a dbt source freshness command or a dbt source freshness block:
sources:
- name: your_source_name
database: your_database
schema: your_schema
tables:
- name: your_table
freshness:
warn_after:
count: 1
period: day
loaded_at_field: date_columnFreshness SLIs
In the same way you would write a SQL rule to verify volume SLIs, you can create a SQL rule to verify the freshness of your data. In this case, the SLI would be something like “hours since dataset refreshed.”
Like your SLI for volume, what threshold you choose for your SQL rule will depend on the normal cadence of your batched (or streamed) data and what agreements you’ve made in your freshness SLA.
{% test not_null(model, column_name) %}
select *
from {{ model }}
where {{ column_name }} is null
{% endtest %}Volume tests
Is data coming in? Is it too little? Too much? These are all data quality issues related to the volume of data entering your database.
Volume tests are a must-have quality check that can be used to validate the number of rows contained in critical tables.
Missing data
Let’s say your data platform processes data from temperature sensors, and one of those sensors fails. What happens? You may get a bunch of crazy temperature values—or you may get nothing at all.
Missing data can quickly skew a data model or dashboard, so it’s important for your data quality testing program to identify quickly when data volume has changed due to missing data. Volume tests will enable you to identify when data volumes have changed to uncover failure points and validate the accuracy of your data.
Too much data
Too much data might not sound like a problem (it is called big data afterall), but when rows populate out of proportion, it can slow model performance and increase compute costs. Monitoring data volume increases can help reduce costs and maintain the integrity of models by leveraging only clean high quality data that will drive impact for downstream users.
Volume SLIs
SLAs (service level agreements) are critical to a modern data reliability motion, and volume SLIs are the metrics that measure performance against a given SLA.
Volume tests can be used to measure SLIs by either monitoring table size or table growth relative to previous measurements. For example, if you were measuring absolute table size, you would could trigger an event when:
- The current total size (bytes or rows) decreases to a specific volume
- The current total size remains the same for a specific amount of time
Numeric distribution tests
Is my data within an accepted range? Are my values in-range within a given column?
These are questions that can be answered using distribution tests. In academic terms, a distribution test validates whether the data within a given table is representative of a normally distributed population. Essentially, does this data reflect reality?
These rules can easily be created in SQL by defining minimums and maximums for a given column.
One great example of an out-of-the-box distribution test is dbt’s accepted_values test, which allows the creator to define a range of acceptable distribution values for a given column.
Great Expectations also provides a library of common “unit tests”, which can be adapted for your distribution data quality testing. For example, here’s how you might ensure the zip_code column represents a valid zip code using Great Expectations unit tests:
expect_column_values_to_be_between(
column="zip_code",
min_value=1,
max_value=99999
)Inaccurate data
In the same way that missing data can paint a false picture of reality, inaccurate data can be equally detrimental to data models. Inaccurate data refers to the distribution issues that arise from incorrectly represented datasets. Inaccurate data could be as simple as a doctor mistyping a patient’s weight or an SDR adding an extra zero to a revenue number.
Creating distribution monitors to identify inaccurate data is particularly important for industries with robust regulatory needs, like healthcare and financial institutions.
Data variety
Sometimes new values enter a table that fall outside a typical distribution. These values aren’t necessarily anomalous, but they could be. And when it comes to data quality, “could be” is usually something we want to keep an eye on.
Including distribution tests as part of your data quality testing effort can help proactively monitor for new and unique values to spot potentially anomalous data that could indicate bigger issues down the road.
Uniqueness tests
Another common quality issue that beleaguers data engineers and downstream users alike is duplicate data. Duplicate data is any data record that’s been copied and shared into another data record in your database.
Without proper data quality testing, duplicate data can wreak all kinds of havoc—from spamming leads and degrading personalization programs to needlessly driving up database costs and causing reputational damage (for instance, duplicate social security numbers or other user IDs).
Duplicate data can occur for a variety of reasons, from loose data aggregation processes to human typing errors—but it occurs most often when transferring data between systems.
Uniqueness tests enable data teams to programmatically identify duplicate records to clean and normalize raw data before entering the production warehouse.
If you’re using dbt, you can use the unique test to validate your data for duplicate records, but uniqueness tests are available easily out-of-the-box for a variety of tools depending on what you’ve integrated with your data stack.
Referential integrity tests
Referential integrity refers to the parent-child relationship between tables in a database. Also known as the primary key and the foreign key, the primary key is the root data that gets joined across tables to create models and derive insights.
But what happens if the data used for that primary key gets changed or deleted? That’s where referential integrity tests come in. Known as the relationships test in dbt, referential integrity tests ensure that any data reflected in a child table has a corresponding parent table.
Let’s say your marketing team is pulling a list of customer ids to create a personalization campaign for the holidays. How does your marketing team know those customer IDs map back to real people with names and addresses? Referential integrity data quality testing ensures that no changes can be made to a parent or primary key without sharing those same changes across dependent tables.
String patterns
In today’s distributed world, it’s not uncommon to find discrepancies in your data from all kinds of human error. Maybe a prospect forgot a character in their email address or an analyst accidentally changed a row without realizing it. Who knows!
Because data inconsistencies are fairly common, it’s important that those records are reconciled regularly via data quality testing to ensure that your data stays clean and accurate.
Utilizing a string-searching algorithm like RegEx is an excellent way to validate that strings in a column match a particular pattern. String patterns can be used to validate a variety of common patterns like UUIDs, phone numbers, emails, numbers, escape characters, dates, etc.
Popular data quality testing tools
Data quality testing comes in a variety of shapes and sizes—from the tests you use to the tools that power them. Let’s take a look at some of the most popular data quality testing tools.
Point solutions
Many data platforms offer point solutions that provide the ability to create data tests to cover a specific point in the data pipeline, for example a data warehouse vendor might provide the ability to create data tests to monitor the accuracy of data within the warehouse.
Unfortunately, point solutions are insufficient to cover the full breadth of known and unknown issues that might arise within a given pipeline. They also lack broad scalability and suffer from a lack of interoperability with other critical platform tooling.
dbt tests
Dbt, a SQL-based command-line tool with robust testing features. As your datasets start to grow beyond what can be manually inspected, there’s a transition to using dbt for more structured data testing. Column-level tests are manually added to validate data integrity and ensure specific data quality standards.
With dbt you will also have table level lineage and you can start to capture documentation—which is a good habit to get into regardless of where you’re at on your data quality maturity journey. Unfortunately, dbt tests also suffer from a lack of scalability. As your data grows in size and complexity, you’ll quickly find yourself facing new data quality issues—and needing new capabilities to solve them.
Great Expectations
Similar to dbt tests in functionality, Great Expectations is an open-source data quality testing framework that includes a library of common unit tests that data teams can leverage to check for common data quality issues.
When issues are limited and known, Great Expectations can be a great jumping off point for new data quality programs. But as data scales and data tests need to be applied broadly across pipelines, Great Expectations will become a bottleneck to effective data quality testing, leaving limited resource to cover an increasing number of data quality leaks.
Data observability
Data observability uses automation to deliver comprehensive testing, monitoring and alerting — in a single package.

In addition to providing completely automated out-of-the-box monitors for common unknown unknown issues like freshness and volume anomalies, data observability also provides a platform to quickly create and scale more specific data quality testing for known issues as well. Plus, data observability provides automated column-level lineage and table-level lineage to help teams understand the impact of their data quality issues—and triage and resolve them faster.
How data observability powers ETL testing at scale
Now that you have a few essential data quality tests in your data quality testing quiver, it’s time to get at it! But remember, data reliability is a journey. And data quality testing is just the first step on your path.
As your company’s data needs grow, your manual data quality testing program will likely struggle to keep up. And even the most comprehensive data quality testing program won’t be able to account for every possible issue. If data quality testing can cover what you know might happen to our data, we need a way to monitor and alert for what we don’t know might happen to your data (our unknown unknowns).
- Data quality issues that can be easily predicted. For these known unknowns, automated data quality testing and manual threshold setting should cover your bases.
- Data quality issues that cannot be easily predicted. These are your unknown unknowns. And as data pipelines become increasingly complex, this number will only grow.
Still, even with automated data quality testing, there’s extensive lift required to continue updating existing tests and thresholds, writing new ones, and deprecating old ones as your data ecosystem grows and data evolves. Over time, this process becomes tedious, time-consuming, and results in more technical debt that you’ll need to pay down later.
Here’s where data observability comes in.
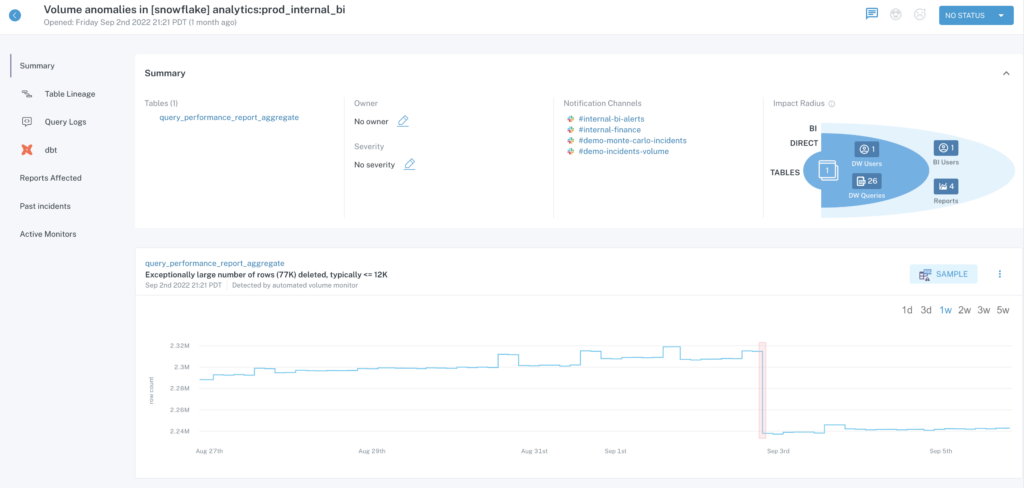
In the same way that application engineering teams don’t exclusively use unit and integration testing to catch buggy code, data engineering teams need to take a similar approach by making data observability a key component of their stack.
Data observability is an organization’s ability to fully understand the health of the data in their systems. Data observability eliminates data downtime by applying best practices learned from DevOps to data pipeline observability. Data observability tools use automated monitoring, automated root cause analysis, data lineage and data health insights to detect, resolve, and prevent data anomalies. Data observability both scales data quality through automated freshness, volume, and schema monitoring and alerting, and gives data teams the ability to set custom rules for specific, unknown unknown data quality issues like field health and distribution anomalies.
After all, delivering high quality data is about more than making sure your tables are being updated or your distributions are falling in an acceptable range. It’s about empowering your data engineers to deliver the best and most accurate data for your business needs at each stage of the data life cycle.
If data reliability is on your roadmap next year, consider going beyond data quality testing and embracing an end-to-end approach to data quality.
Until then, here’s wishing you no data downtime!
Interested in scaling data quality testing with data observability? Reach out to Brandon and the rest of the Monte Carlo team to learn more about data observability.
Our promise: we will show you the product.
Read more posts.