Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Data Warehouse Testing: 7 Steps to Validate Your Warehouse


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Your data warehouse isn’t simply the storage and compute layer of your data stack—it’s one of the most foundational production tools in your data platform. In many ways, the quality of your data warehouse—whether it’s Snowflake, on prem, or something else entirely—will determine the quality of the data products it supports. And testing your warehouse is the first step in verifying that your warehouse is up to the task.
Put simply, data warehouse testing is the process of verifying that those things both inherent and incidental to the data warehouse meet predefined quality and performance standards. Popular data warehouse tests include ETL tests, regression testing, user acceptance testing, and stress testing, among a variety of others.
Without the right data warehouse testing program, it’s impossible to validate the quality of your data or the value your warehouse provides to your broader data platform. In this guide, we’ll walk you through the testing process step-by-step from aligning with stakeholders right down to validating your results.
Let’s dive in!
Step 1: gather and analyze requirements
Before you can build a data warehouse testing program, you need to understand what you’re testing. Defining requirements is the foundation of the testing process.
In the first step of the testing process, you’ll define both the business and functional needs of your data warehouse.
How to gather and analyze requirements:
- Stakeholder Interviews: Engage with key stakeholders, including data architects, business analysts, and end-users, to gather insights about the data warehouse’s purpose, expected outcomes, and potential challenges.
- Document Business Requirements: Create a comprehensive document detailing the business requirements. This should include the types of data to be stored, the source systems, expected data transformations, and any business rules or logic that the data should adhere to.
- Understand Data Sources: Analyze the source systems from which data will be extracted. Understand the nature of the data, its format, update frequency, and any potential inconsistencies or quality issues. For example, “active users” might be defined differently across departments.
- Define Data Quality Criteria: Establish clear criteria for data quality. This should include requirements for accuracy, volume, freshness, and consistency. Knowing the quality benchmarks in advance will guide the data warehouse testing process and ensure that the data in your warehouse meets or exceeds these standards.
Key considerations:
- To improve the value of your data warehouse testing program, make your requirements clear and specific and get approval from stakeholders.
- Minimize delays by anticipating challenges—like discrepancies in source systems or complex transformation rules.
- And remember, as your data warehouse evolves, requirements might change. To avoid losing track of critical information, remember to keep your documentation updated regularly.
Now that you have a comprehensive understanding of the requirements, you’re ready for the next step of the data warehouse testing process: scoping.
Step 2: define the testing scope
Here you’ll determine which parts of the data warehouse will be tested, which data sources are involved, and how extensive your testing will be. Let’s look at an example to understand this step in the data warehouse testing process.
Imagine you work at ShopTrendy, a bustling e-commerce platform. The data in your warehouse flows from three sources—the online sales platform, an inventory management system, and a customer feedback portal—and you want to validate the successful extraction, transformation, and loading (ETL) of the data from your three source systems into your data warehouse. Here’s what the scope of testing your ETL pipeline could look like:
Extraction
- Online Sales Platform: Ensure all sales transactions, including product details, quantities, prices, and payment methods, are correctly extracted without data loss.
- Inventory Management System: Validate that stock levels, restocks, and product identifiers are accurately extracted each day.
- Customer Feedback Portal: Confirm that customer reviews, ratings, and feedback are aggregated correctly on a weekly basis.
Transformation
- Online Sales Platform: Transformations include aggregating sales data to compute monthly revenue, calculating taxes, and converting foreign currency transactions to the local currency.
- Inventory Management System: Daily transformations involve calculating the day’s sales, updating stock levels, flagging low-stock items, and categorizing products based on sales velocity.
- Customer Feedback Portal: Feedback is categorized based on product, sentiment analysis is performed on reviews, and overall customer satisfaction scores are computed.
Loading
- Online Sales Platform: Post-transformation, sales data is loaded into the financial reporting module, ensuring accurate monthly financial figures.
- Inventory Management System: Transformed inventory data is loaded into the inventory management module, reflecting updated stock levels and product categorizations.
- Customer Feedback Portal: Processed feedback data is loaded into the customer insights module of the data warehouse, providing a holistic view of customer sentiment and areas for improvement.
By validating the ETL processes across these three data sources, you ensure the accuracy and reliability of your data warehouse based on critical business needs.
Step 3: design test cases
Now that you’ve defined the requirements and scope of your data warehouse testing program, the next step in the data warehouse testing process is to design specific test cases.
Going back to our ShopTrendy example, a few test cases could be:
- whether the prices of products in Ireland were correctly converted from USD to Euros using the current day’s exchange rate
- whether aggregated sales data was loaded correctly
- whether the sentiment analysis logic resulted in applying the correct tags to customer reviews
Step 4: set up the testing environment
When you’re running tests on your data warehouse, it’s important to make sure your tests don’t interfere with your production pipelines. That means that instead of testing in a live data environment, you’ll need to create a separate instance of your data warehouse that mirrors your production setup.
To accomplish this, you can either populate the test environment with a subset of actual data from your production environment or use synthetic data that simulates real-world scenarios (this works particularly well for testing edge cases you haven’t encountered in production just yet).
Once you’ve set up your testing environment, remember to periodically synchronize the test environment with your production setup, especially after major updates or changes to the production environment. This ensures that your test environment continues to accurately represent your production environment during testing.
Step 5: execute test cases
You’ve got your test environment all set up—now it’s time to run your designed test cases.
Start with high-priority test cases first, like those related to financial transactions or customer-sensitive data. For ShopTrendy, this might mean validating sales transactions from the online sales platform or testing the security of credit card numbers.
For repetitive or bulk tests, you can automate much of this process by utilizing tools like dbt or DataGaps to code and execute key tasks.
Step 6: verify test results
A test is only useful if you can trust the results. So, in addition to maintaining an accurate testing environment, you’ll also want to validate the results of your tests.
To verify your data warehouse tests, examine the logs generated during test execution to look for any anomalies, errors, or unexpected behaviors.
In the event of a test failure, isolate the issue and analyze the root cause. This might involve reviewing the ETL process, data source discrepancies, or transformation logic. Then re-run the failed test cases after addressing any issues you’ve identified and ensure they pass successfully.
Step 7: report and document findings
You’ve established requirements. You’ve built your test environment. You’ve executed and verified your test results. Now, the final step of the data warehouse testing process is to report and document your findings.
It’s important to maintain detailed logs of each test case execution by capturing information like test case ID, execution date, result (pass/fail), and any relevant comments or observations you made during the process. Not only will proper documentation help in planning future tests or data warehouse enhancements, but in the case of compliance or audit requirements, this documentation can also serve as evidence of rigorous testing.
The limits of data warehouse testing
So, you’ve given your data a good once-over and think you’re done? Well…not quite. Even with the best laid data warehouse testing program, data has a knack for going rogue. Data can easily become corrupted, missing, or embarrassingly outdated at any time and any point as it meanders its way through your data pipelines.
Data validation testing is absolutely a helpful tool to have in your arsenal, but it’s a long way from a comprehensive solution to data quality. A few areas where data warehouse test will fall short include:
1. Data testing only works for known issues. If you can’t anticipate a problem, you can’t test for it.
2. Data testing only works if every data engineer knows the rules to apply to them. Does every data engineer know that a currency conversion column can’t be negative?
3. Data testing only works as far as you have the resources to scale it. Coding one test for five tables is pretty easy. Coding 100 tests for 500 tables…not so much.
No matter how good your data warehouse testing process is, you’ll always be limited by your available resources and your available knowledge—and that can leave a lot of gaps to be filled.
Why your data warehouse needs data observability
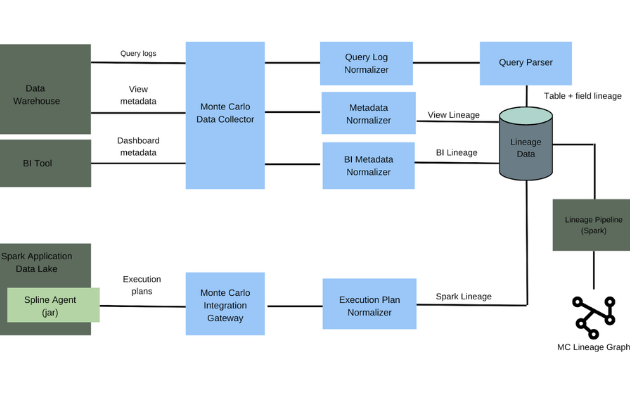
A data observability platform like Monte Carlo doesn’t just offer a peek into one layer of your data platform. Data observability provides end-to-end visibility into the quality of both your data and the pipelines it flows through, including hyper-scalable automated monitoring across every production table—right down to your most critical fields.
Unlike traditional hand-coded data warehouse testing practices, Monte Carlo leverages machine learning to automatically create monitors and programmatically sets thresholds based on the normal behavior of your data. And as soon as a data incident is detected, Monte Carlo notifies data owners to quickly triage and resolve incidents before they impact downstream consumers.
So, when your data quality pain scales beyond what your hand-written tests can cover, it’s time to consider data observability.
Ready to expand your data warehouse testing with data observability? Let us know in the form below.
Our promise: we will show you the product.
Read more posts.