 Product demo.
Product demo.  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Enabling a Self-Serve Data Culture at Whatnot with Data Observability

Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
Founded in late 2019, the livestream shopping platform Whatnot has grown to become one of the largest online marketplaces for collectibles in the U.S. Whatnot brings together commerce and entertainment in categories like trading cards, sports cards, and fashion, to video games, streetwear, and beyond.
Merchandise sellers cultivate audiences through their dedicated channels, and buyers get to know and interact with the people on the other side of their transactions during their livestream shows. Think Twitch meets eBay.
Now, imagine all the data powering that platform.
We had to know how their data team made it happen, especially in such a short span of time, so we recently sat down with Engineering Director Emmanuel Fuentes to learn more. Emmanuel leads the Machine Learning & Data Platforms teams at Whatnot, while his colleague Evan Hou heads up analytics and data science. They were among Whatnot’s earliest employees and together built the data foundation for the company.
“Both Whatnot’s founders are serial entrepreneurs, and they knew around the Series A that they needed to build up the data function as a core competency,” says Emmanuel. “Data is very much part of the culture.”
For every decision or process, Whatnot leaders consider three “legs of the stool”: user research (every engineer is encouraged to talk directly to users and dogfood the app), product strategy, and data. “If you don’t come to the discussion with all these perspectives, it’s not going to go very far at the company, ” he says.
The overall goal of Emmauel’s team is to empower absolutely everyone at the company to work with and rely on data for faster and more accurate decision-making. The data platform was built to remove bottlenecks to data access and create accountability for prioritizing analytics and machine learning across the organization — no small task.
“It’s pretty rare that you have both the problems of a social network and the problems of a marketplace, so that’s our core differentiator.”
So how did they do it? Let’s dive in.
Building a modern data stack during hypergrowth
With Emmanuel joining the organization as an early hire, he and his team were able to architect and build a modern, scalable data stack from the ground up. They took their time (more on that in a moment), and they did it right.
Buying, not building, for most data platform needs
Deciding whether to build or buy different layers of a tech stack can keep some teams snarled in debates for weeks or even months. That’s not the case at Whatnot.
“Early on, we decided to optimize for speed,” says Emmanuel. “We’re mostly a buy versus build shop. Later in our journey, we’ll decide to bring some things in-house, but at this point, we’re really about augmenting the team—getting the most value with the fewest number of people as quickly as possible.”
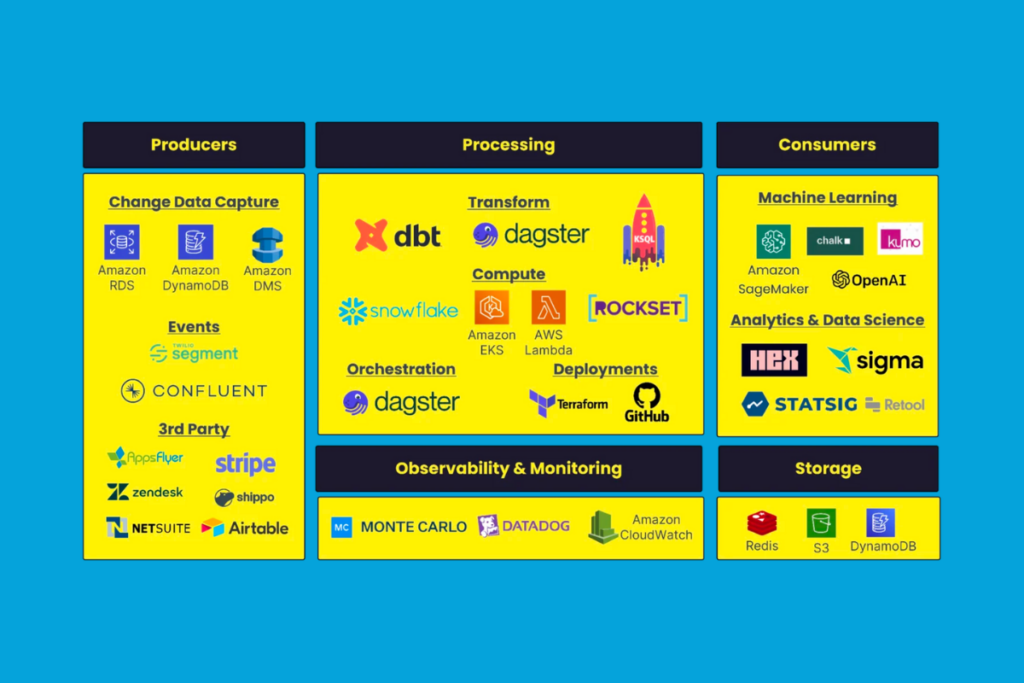
The current data stack
As an AWS shop, the key components of the Whatnot data stack include Snowflake, dbt Cloud for transformation, Dagster for orchestration, Segment as a customer data platform, Confluent for managed Kafka, Rockset for real time aggregations, and Sigma+Hex for presentation. Amazon SageMaker powers their ML operations, with a variety of related solutions under evaluation.
This stack powers complex internal and customer-facing data products. For example, in-app analytics allows sellers to log into a dashboard and see charts representing their viewers, sales, scores, and other data points. Meanwhile, buyers experience a TikTok-style “For You” feed, with ML models determining the most relevant content to surface — both to keep their engagement high and improve performance on the seller side.
“The models, the real-time metrics, all of it comes together to make sure we’re spreading the opportunities on the platform, while also making sure sellers can be successful,” says Emmanuel.
Making data fluency part of everyone’s job description
Since the livestream auction feature launched in the summer of 2020, the company’s user base skyrocketed — and its headcount grew accordingly, to just around 500 employees.
“Rapid growth meant that our data had to be very self-serve,” says Emmanuel. “For the amount of consumption happening, there just wasn’t going to be enough people on our team to support everything.”
At Whatnot, self-serve data truly means self-serve. Each employee is highly encouraged to know SQL so they can query their own data, write their own dbt models, and create their own dashboards/notebooks — even across non-technical departments like marketing, finance, and operations.
“Everyone can answer their own questions, which is part of the reason we can move so fast,” Emmanuel says. “And it up-levels everyone to understand the nuances of the business. If people just use reports, someone’s done all the thinking for them. So it’s really helped democratize that deep intuition.”
But, with this incredible level of data democratization, that data needs to be reliable and trustworthy. And as this self-serve data platform grew to include 1,000+ dbt models, things got thorny.
“You can imagine the dependency graph becomes quite gnarly,” says Emmanual. “So we needed additional tooling to make sure we weren’t stepping on each other’s toes and blowing up the builds.”
Developing more scalable, reliable data products with data observability
The team needed to move quickly to get out in front of a potentially enormous problem. They began looking into data observability, searching for a solution that would scale, require little oversight from the team, integrate well with the existing stack (especially dbt), and have robust monitoring and alerting features.
“We were basically looking for the closest fit that would require the least amount of work on our end,” says Emmanuel. “… we also knew it would be important to enjoy working with the partner and be able to have our feature requests prioritized and get done promptly.”
Ultimately, the Whatnot team narrowed down their choices to Monte Carlo and one other solution.
“Honestly, what stood out was the last criteria,” Emmanuel says. “During the evaluation period, we found features we’d like to have, weren’t put into the back of a backlog. Our problems were resolved during the evaluation period, and to me, that signals a true partnership versus a SaaS vendor as a line item.”
With Monte Carlo’s data observability platform, Emmanuel and his team began to rely on automated monitoring and alerting based on historical data patterns, as well as end-to-end lineage to help everyone understand how pipelines flowed and how upstream changes would impact downstream users.
“I was surprised at how quickly Monte Carlo started helping,” said Emmanuel. “It started giving us a lot of confidence. Not only was the platform helping us find problems and fix them, but it was validating assumptions around issues we knew were happening — for example when a process added a new enum on an existing table field. Monte Carlo alerted us to that spike, and it was positive reinforcement that the platform was working.”
Data observability has meant that even with exponential growth, the Whatnot team has been able to maintain data democratization and keep data incidents flat.
“Flatline is great for us,” says Emmanual, “It’s actually quite difficult to keep incident rates flat as magnitudes increase in platform usage and adoption.”
A few words of advice — and predictions on the utility of generative AI
We asked Emmanuel what advice he would share with other data leaders faced with building a modern data platform that supports this level of self-serve analytics.
Prioritize the foundational work, but deliver value quickly
First and foremost, Emmanuel says, “Don’t be in a rush to do the fancy stuff. It basically took a full nine months before we could even develop our first machine learning model because we were just laying the foundation, and doing it in a way we knew would scale. You’ve got to learn to love and enjoy doing the foundational work because it will come back to you.”
But, while you do that work, “You also have to deliver value to the business quickly,” Emmanuel says. His team put reporting and core business metrics in place rapidly, yet behind abstractions that would enable continual improvements without an impact to users.
“Under the hood, it was sticks and bubble gum, but you can go in and clean it up after the fact,” Emmanuel says. “I think some folks join a team and think they need to get everything pristine and fully dimensional from the beginning. I don’t think it’s worth it in the early days. And that may sound contradictory to laying the foundation, but there is a way to balance both.”
Balancing the hype and helpfulness of generative AI
We also asked Emmanuel about the potential impact of generative AI on data teams because – why not? We’ll take any excuse to ask a pro for some words of wisdom about the latest and greatest – or at least, most talked about – tech.
He isn’t one for buying into a hype cycle, saying, “To me, generative AI is just another machine learning model with some special characteristics, and I treat it no differently than our recommendation and trust & safety systems.”
But Emmanual is interested in how generative AI can help summarize Whatnot’s help desk workflows, both internal and external, which would augment their limited number of support agents. And given that every team member at Whatnot is expected to know and write SQL to manage their own data needs, Emmanuel has already seen generative AI tools like ChatGPT play a role in employee training.
“It’s helping people bootstrap,” says Emmanuel. “If they come in with no background in SQL, it’s helping them ramp up fairly quickly, which is really great to see. If someone doesn’t know how to do a window function, for example, they can describe what they’re trying to do, get a chunk of SQL out, and then swap in our data tables. It’s like having a tutor for someone who just doesn’t know how to do any advanced analytics.”
What’s next for data at Whatnot
According to Emmanuel, real-time analytics is one of the core themes shaping the future of data at Whatnot.
“I would say 95% of businesses actually don’t need to do real-time analytics or real-time machine learning,” says Emmanuel. “But since we’re a live-streaming platform, for us, real-time data is operationally very important.”
For example, incidents of abusive behavior during a livestream, fraudulent credit cards, or sellers having issues with pricing can stall the business. The Whatnot data teams need to have real-time systems in place to catch and address these kinds of issues.
“We’re investing heavily in our real-time stack for analytics, metrics, and machine learning,” says Emmanuel. “We’ve been doing a lot already, but it has to go to the next level.”
Given that the use cases for real-time analytics are rare, Emmanuel also wants to make it easier for new engineers who have never worked with these systems to adopt them. “How do we provide Python packages or abstractions to make this as trivial for them as possible? We’re establishing patterns that anyone in the company can use and just get going.”
Additionally, Emmanuel has some thoughts on how this shift will – or won’t – impact their team structure: “I firmly believe that MLOps and DataOps are no different. Even though the industry has really optimized on creating specialty roles in different companies, a data platform team has more or less all the tools they need to do both kinds of work. So for as long as we can here at Whatnot, MLOps and DataOps will be the same thing.”
Whether you share Emmanuel’s belief or not, one thing is certain: MLOps and DataOps are indeed no different when it comes to the need for reliable, trustworthy data. If you’re building your data stack and want to deliver the highest quality of data possible to your organization, data observability will help you enable your company to self-serve their data. Learn more about data engineering at Whatnot on their blog.
Contact us to see what Monte Carlo can do for you, too.
Our promise: we will show you the product.
Read more posts.



