Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage ETL vs. Data Pipelines: A Quick Guide for the Hopelessly Confused

Michael Segner
Michael writes about data engineering, data quality, and data teams.
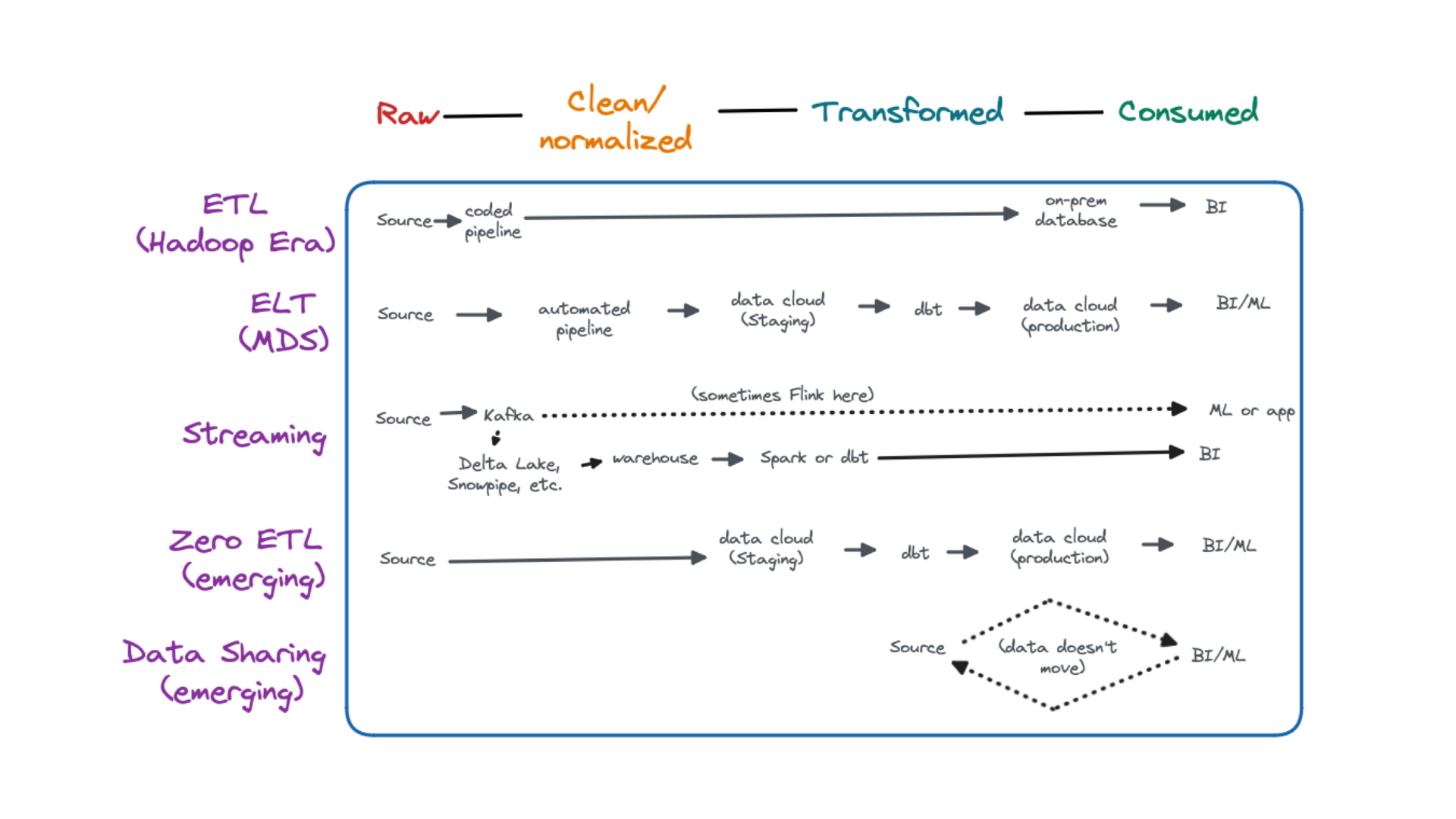
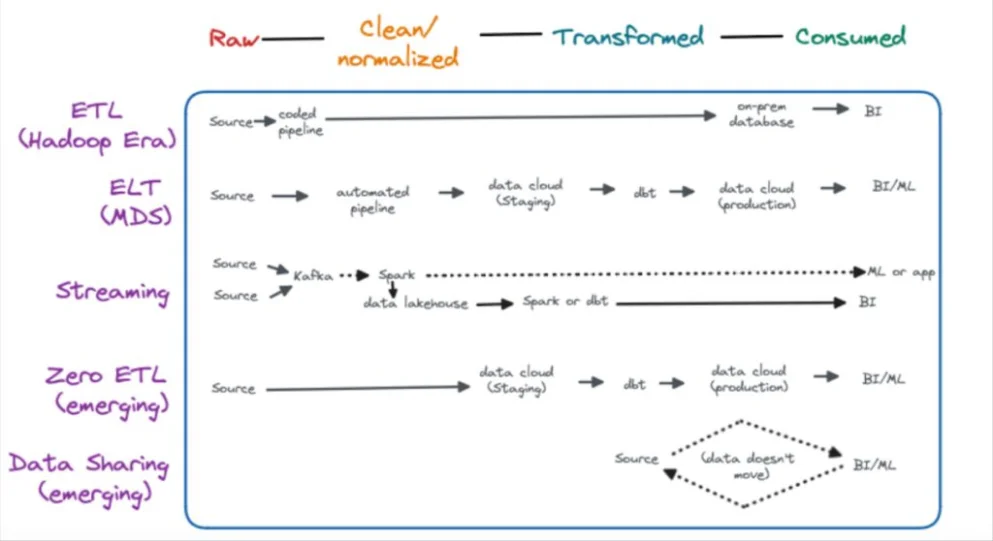
Data pipelines are a set of processes that enable the flow of data from one system to another, and one such process you can use is ETL (extract, transform, load).
The way to think of the relationship between the two is that ETL is a data pipeline, but not all data pipelines are ETL.
Besides ETL, there are quite a few ways to process data that fall under the umbrella of data pipelines, including real time processing, data sharing, ELT, and Zero ETL.
The reason ETL is commonly confused for or used as a synonym for data pipelines is that ETL was one of the most popular data pipeline architectures for a long time. Today, most data leveraging a modern data platform will deploy multiple types of data pipeline with ELT being the most common.
What is an ETL pipeline?
ETL provides a structured and systematic approach to data processing. The three steps – extract, transform, and load – are clearly defined, making it easier to manage and monitor the data processing workflow.
The transformation step, in particular, allows for data cleaning and validation. This ensures that the data loaded into the target system is accurate, consistent, and reliable.
However, a transformation rule that worked perfectly today might fail tomorrow due to changes in the data source, schema modifications, or system updates. To really ensure data quality requires a more comprehensive, continuous, and collaborative approach.
This is where a data observability platform like Monte Carlo comes into play. Monte Carlo provides an automated, end-to-end solution to monitor data health and reliability. It goes beyond the transformation step of ETL and provides continuous visibility into your data pipelines.
Interested in how data observability can help you automate your data quality monitoring and accelerate issue resolution? Talk to us!
Our promise: we will show you the product.
Read more posts.