Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Good Pipelines, Bad Data


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
It’s 2020, and we’re still using “photos and a paper trail” to validate data. In the recent Iowa election, data inconsistencies eroded trust in the results. This is just one of the many recent, and prominent, examples of how pervasive “data downtime” corrupts good pipelines.
Data downtime refers to periods of time when your data is partial, erroneous, missing or otherwise inaccurate — and almost every data organization I know struggles with it. In fact, this HBR article cites a study that found companies lose an average of $15M per year due to bad data. In this blog post, I will cover an approach to managing data downtime that has been adopted by some of the best teams in the industry.
So, what does it mean to measure data downtime?
To begin unpacking that, let’s look into what counts as “downtime”. Data downtime refers to any time data is “down”, i.e. when data teams find themselves answering “no” to common questions such as:
- Is the data in this report up-to-date?
- Is the data complete?
- Are fields within reasonable ranges?
- Do my assumptions about upstream sources still hold true?
- … and more
Or in other words… Can I trust my data?
Answering these questions in real time is hard.
Data organizations large and small are challenged with these questions since (1) consistently tracking this information across data pipelines requires substantial resources; (2) at best, information is limited to a small subset of the data that had been laboriously instrumented; and (3) even when available, sifting through this information is tedious enough that teams often find about data issues in hindsight.
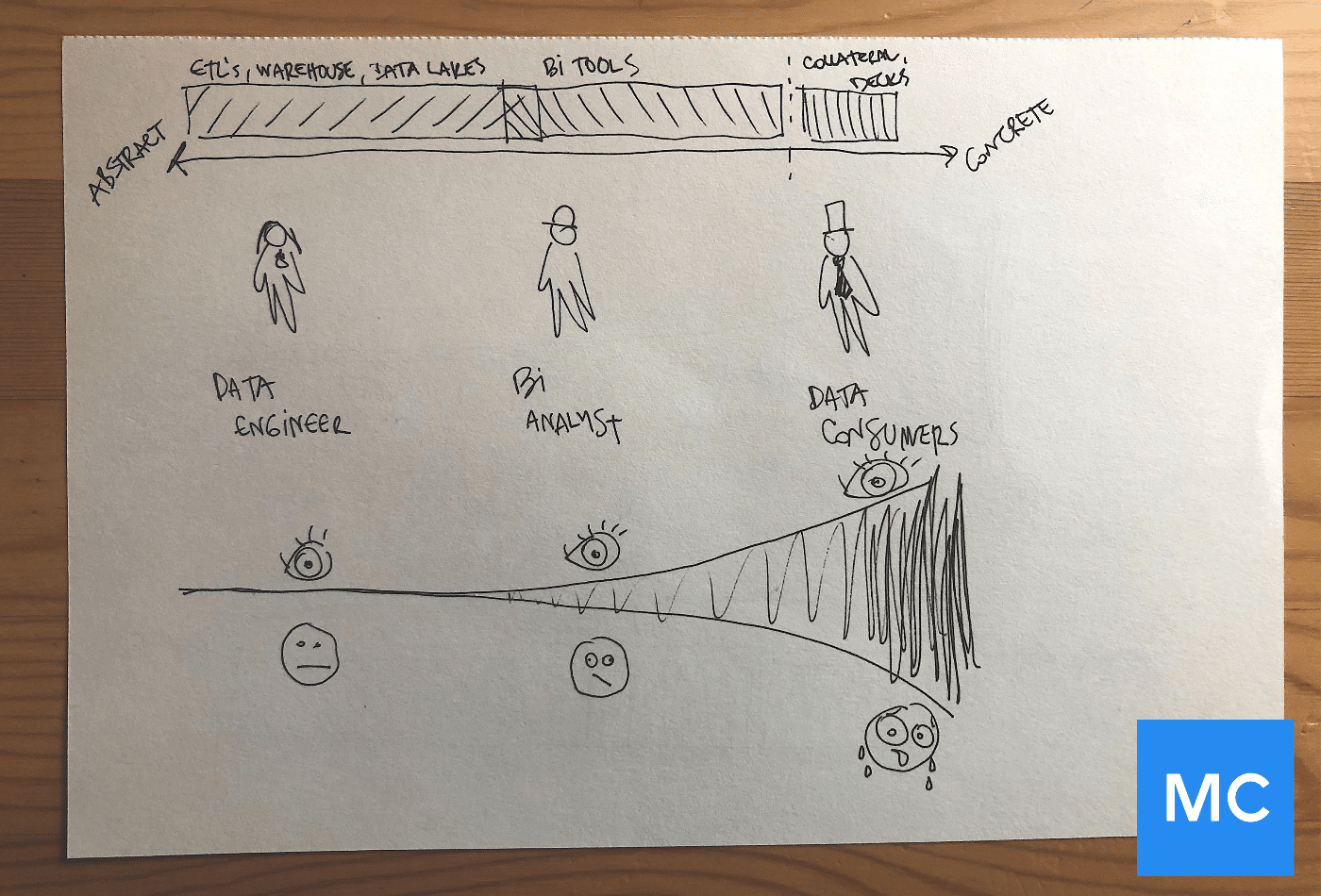
In fact, it is typical that data consumers — product managers, marketing experts, executives, data scientists, or even customers — identify data downtime right at the moment when they need to use the data. And somehow, that always happens late on a Friday afternoon…
How come we know everything about how well our data infrastructure is performing, but so little about whether the data is right?
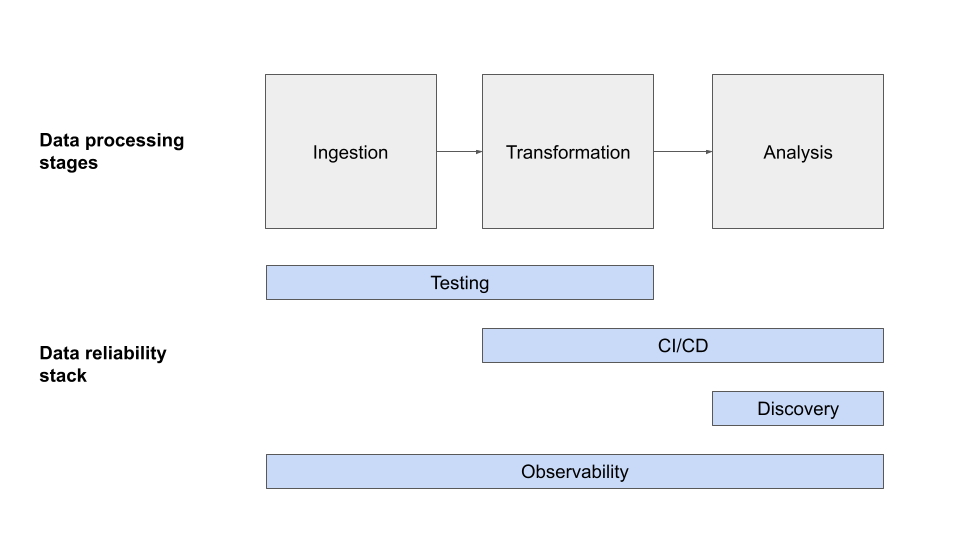
A helpful corollary here is drawing on the world of infrastructure observability. Almost every engineering team has tools to monitor and track infrastructure and guarantee that it is performing as expected. This is often referred to as observability — the ability to determine a system’s health based on its outputs.
Great data teams make investments in data observability — the ability to determine whether the data flowing in the system is healthy. With observability comes the opportunity to detect issues in your perfectly good pipelines before they impact data consumers, and to then pinpoint and fix problems in minutes instead of days and weeks.
So what makes for great data observability? Based on learnings from over 100 data teams, we’ve identified the following:

Each pillar encapsulates a series of questions which, in aggregate, provide a holistic view of data health.
- Freshness: is the data recent? When was the last time it was generated? What upstream data is included/omitted?
- Distribution: is the data within accepted ranges? Is it properly formatted? Is it complete?
- Volume: has all the data arrived?
- Schema: what is the schema, and how has it changed? Who has made these changes and for what reasons?
- Lineage: for a given data asset, what are the upstream sources and downstream assets which are impacted by it? Who are the people generating this data, and who is relying on it for decision making?
Admittedly, data can break in endless ways and for a wide range of reasons. Surprisingly, we have found time and time again that these pillars — if tracked and monitored — will surface almost any meaningful data downtime event.
Interested in learning how to save your good pipelines from bad data?
Our promise: we will show you the product.
Read more posts.