Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How a Fortune 500 CPG Leader Takes a Proactive Approach to Data Quality


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Did you know that breakfast cereal and data go hand in hand?
With over 100 household brands, this CPG leader is one of the largest manufacturers of branded consumer packaged goods in the world—and that doesn’t happen without a whole lot of data.
And over the years, their appetite for new data products has only continued to grow
“Data is everywhere,” says Sanchit Srivastava, Senior Manager of Data Analytics. “It’s really fueling our everyday decisions. Our focus, which is making food the world loves, involves making consumer-centric decisions and enabling our customers with all possible healthy options.”
As the data team prepares to take the company into the future with new priority Generative AI initiatives, the need for accurate and reliable data has taken center stage.
Curious how a Fortune 500 company manages data quality across a family of distributed brands—each with its own products and pipelines?
We sat down with Sanchit to learn more about how a Fortune 500 CPG leader operationalized end-to-end data observability across business domains and how they’re approaching reliable generative AI development.
Read on!
Table of Contents
The impact of bad data was expanding—and something needed to change
With a data stack that includes GCP, Azure services, and a variety of columnar databases for operational analytics, the data team supports operational data products and decision-making across all areas of their colossal organization.
Data analytics helps power inventory management for both brick-and-mortar and eCommerce, logistics data powers supply chain management, data insights directly support product development and innovation, and data even powers consumer engagement like customer benefits and retail strategies.
With data playing a critical role at every level of the business, operational success was dependent on the reliability of its data.
But, with such an expansive modern data organization, their existing approaches to data quality management, like manual rule creation, data audits, and ad-hoc requests, were difficult to scale.
“Most of the approach was reactive in nature, with little to no insight into the impact radius of a data anomaly,” said Sanchit. “This typically led to an even larger impact with no central repository for root cause analysis.”
On top of an expanding impact radius and increasing time-to-resolution, the data team was losing more and more of its critical engineering time to data quality issues as well—sapping limited resources without delivering new value.
“Developers were blocking multiple days per week every week just to audit the data on the pre-built rules,” says Sanchit. “The business was changing every day, but we were still running old rules. They were having to spend this time looking back instead of looking for future problems.”
This reactive approach eventually tipped the scales when a report with bad data led to a business decision that impacted operations. Resolution only began after the business identified the issue in production and valuable time to make business decisions was already lost.
“At the time the business decision had to be made, we instead had to start the process of rectifying the data – that led to delays in business operations and data load SLAs, and the impact radius became wider and wider…It was an issue which could have been avoided by a more proactive approach to data quality, and it was the issue that broke the camel’s back.”
The team decided it was time to re-examine their approach to data quality – and transforming incident management was going to be their first step.
Transforming from reactive to proactive data quality
Anyone who’s been in the data quality or governance world for long will tell you that great data quality incident management is always a mix of process and technology.
A great process only works if you’ve got the tooling and monitoring to power it. And the right data quality tool is only helpful if you can also implement the right process to operationalize it.
That’s why when the team took aim at their data quality gaps, they took aim at answering the biggest question first: who owns data quality anyway?
Moving data quality ownership from developers to data analysts
You can resolve a data quality issue until you can identify who’s responsible for it. Of course, that doesn’t mean just pointing fingers when something goes wrong—it simply means empowering teams to own the product and its performance.
When data quality transformation began, data engineering was owning data quality nose to tail. When downstream users discovered a problem, it was an engineer who was tapped to root-cause and resolve it. Unfortunately, the scale of its data environment—and the myriad opportunities for bad data to rear its head—far outpaced the data engineering team’s ability to manage it. Because of this, the team was losing time resolving data quality issues when they could have been spending that time driving analytics with new models and experiments.
The data team knew something had to change.
“That was an initial key goal for us,” says Sanchit. “We didn’t want developers to be fixing data quality anymore. Data analysts should be playing a bigger role there.”
In this new era of data quality, data analysts would take an active role in the implementation and management of monitoring and resolution for their critical data products. Once Sanchit knew who would be proactively owning data quality, the next step was empowering them with the right tools to be successful.
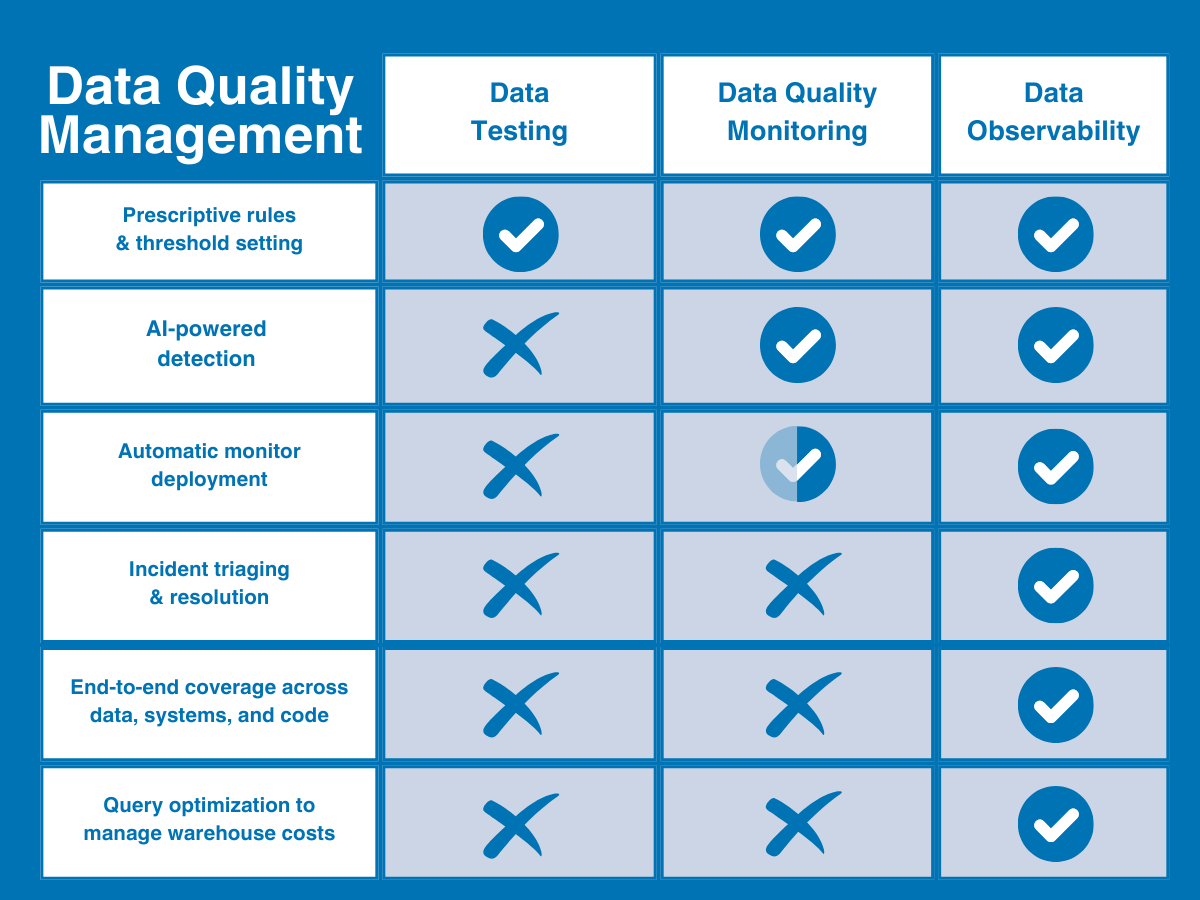
And that’s where data observability came into play.
Implementing data observability to scale detection and resolution
Choosing the right data quality tool was essential to their transformation. With a proliferation of new tooling and approaches to data quality on the market, the team relied on a clear understanding of their goals and constraints in order to make the best decision for the team—chief among them was their new ownership direction.
When the team began searching for the right data observability solution, they knew it would need to be analyst-friendly.
“We wanted a tool that was simple enough that everyone could use it – technical enough for engineers, but simple enough that business enablers could easily use it as well,” said Sanchit.
However, that wasn’t all they needed.
In addition to usability, their ideal tool would also need to offer a comprehensive suite of functionalities that could effectively address their bottlenecks and empower the team to easily scale coverage across domains.
“We needed a combination of tools: data quality, data lineage, incident management, and collaboration that could enable us to be proactive,” says Sanchit. “This tool wouldn’t need to be our analytics, but it would need to be peripheral to our analytics – it would need to make sure our analytics are doing their job.”
For the data team, the ideal data quality tool would:
- Provide a single pane of glass to understand the health of data running from end-to-end, from ingestion to consumption
- Coverage at the data, system, and code levels to understand what broke and why
- Automate data lineage across their analytics platform to understand the impact of incidents at a glance
- Operate entirely within the existing data environment
- Onboard quickly out-of-the-box with open flexibility for custom integrations
- Leverage AI and ML to increase productivity by automating manual tasks like data profiling and threshold setting
- And do it all with strong security and privacy controls.
After evaluating several vendors available on the market, only one solution ticked all the boxes.
“We felt Monte Carlo fit the bill,” says Sanchit.
Monte Carlo’s quick deployment and easy-to-use tools had the team up and running fast, and in no time at all, their data quality vision was becoming a reality.
“Analysts can write [data quality] rules directly on the Monte Carlo UI. And when an anomaly is identified, it’s automatically informed to our user base via Microsoft Teams and to our data catalog via Monte Carlo’s integration with Alation…Our largest growing user base is our analysts now,” Sanchit continued.
Monte Carlo’s mix of elegant usability and robust automated coverage made it the ideal data quality solution for users across domains. And, thanks to a tight integration between the Alation Data Intelligence Platform and Monte Carlo, even non-technical users can quickly see data quality issues within their data catalog. Now that multiple domains were up and operationalizing Monte Carlo, the use-cases were flowing in.
Let’s dive into five domain-specific use cases where data observability is helping this Fortune500 CPG leader manage data quality at scale.
Use case: Maintaining trust for external sustainability data
One of the company’s present endeavors—the Sustainability Initiative Project—is dedicated to supporting farmers, communities, and the health of the planet. The data supporting this initiative is reported externally, extending its impact to the broader brand and stakeholders, including investors, regulators, and customers.
Because this data is highly visible, it needs to be accurate and transparent at all times – and Monte Carlo has been there to monitor and maintain it.
Monte Carlo’s data observability has enabled the team to:
- Identify the legitimacy of source data. Because sustainability reporting is highly dependent on data from other functions and systems, the ability to determine whether the changes at the source are legitimate or not is crucial. Monte Carlo automatically investigates the source of the change, the rationale behind it, and its potential impact on reporting. If the change is deemed illegitimate, the team can take corrective actions to ensure data accuracy and maintain stakeholder trust.
- Enable immediate notifications to improve stakeholder trust. Monte Carlo’s automated notification system underscores the importance of being informed about changes immediately. This allows for prompt investigation and understanding of the cause behind the change, enabling swift action to address any potential issues.
Use case: Managing pipeline integrity for trade management systems
When a project required a solution to maintain the accuracy and integrity of base files coming out of the company’s Business and Plants system, the team turned to Monte Carlo to manage the integrity of the pipeline.
Without a robust data quality framework, the team risked inaccurate data flowing into consumption tables which could lead to flawed decision making, operational inefficiencies, or even impacts to downstream applications, like their Reporting and TPM solutions.
The team implemented a data validation and monitoring rule engine, testing the rules against base files, and then embedding them within their composer DAGs using Monte Carlo’s circuit breakers to stop any inaccurate data.
This approach enabled the team to break the pipeline in scenarios where data quality rules failed, keeping inaccurate data from flowing into their consumption tables and systems. This has enabled the team to reduce data errors, improve decision making, and enhance their operational efficiency.
Use case: Monitoring data science pipelines with complex dependencies
On the data science side of things, the team recently went live with 47 custom monitors across 33 of their most important tables.
When it comes to traditional manual testing, it’s nearly impossible to detect issues effectively across complex pipelines—and it’s even more unlikely to resolve them before they impact downstream consumers.
Fortunately, Monte Carlo makes it simple to monitor distributed and complex pipelines for engineers and data scientists alike, with features like automated profiling and lineage and out-of-the-box monitors that scale with your data.
“I view this as an investment,” said one member of the team. “It’s like paying for insurance. When something bad happens, the impact is minimized by allowing us to identify it and narrow down the issue quicker.”
Use case: Saving analysts time with out-of-the-box monitoring
As Sanchit mentioned, the most prominent Monte Carlo users at his organization are the data analyst teams themselves. The most commonly used features among analysts?
Custom SQL monitoring and out-of-the-box asset monitoring.
“Monte Carlo saves me tons of time as an analyst, especially when we’re bringing in new data or creating new pipelines,” said one data analyst. “Without Monte Carlo, I’d have to watch the new data every day to make sure it’s working as expected. It’s much more efficient to just make a custom SQL rule and get notified if the table doesn’t update or is refreshing with stale data.”
The analyst continued, “The asset monitoring is really helpful if I want to see the history of a table… It’s great to be able to answer questions about the frequency of table updates and the kinds of SQL statements that are routinely run against tables without having to track someone down. Monte Carlo does a great job of delivering this neatly.”
Today, the analyst teams are working toward adopting a holistic approach to their data quality management by embracing Monte Carlo as their sole data quality resource.
“As a team, we’re increasing our reliance on Monte Carlo in our support process as well,” says the analyst. “The biggest win here is with our SAP footprint in GCP. All of our SAP ingestions are real-time, so we don’t receive any kind of DAG failure if a connection is broken. Monte Carlo is the perfect solution to monitor this routinely and alert us if there’s an issue.”
Leveraging reliable data in GenAI initiatives
The data team is no stranger to the rapid rise of generative AI. “For us, it’s a game changer,” said Sanchit. “We’re investing in using it in a responsible manner.”
The team is looking into ways they can leverage generative AI primarily for productivity and data democratization use cases. “We’re looking into using existing LLMs to increase our productivity… Doing document, video, and image summarization tasks faster and easier.”
The team is also looking to enable NLP-driven analytics on data platforms, making data insights like orders, invoices, and website data available to more of their agents. This kind of ‘Guided Analytics’ will enable end-users to have easier access to data they previously had to go through developers to receive.
But, according to Sanchit, this can only happen if their data quality is ready. “Good generation can only happen when input is good,” says Sanchit. “Data quality and data governance have huge roles to play.”
The future of data quality for this Fortune 500 leader
These examples are just a few of the many ways this data team is leveraging Monte Carlo across their data organization.
Looking toward the future, the data team is measuring data quality transformation across several KPIs, including:
- Time saved in hours
- Total tickets resolved
- Financial savings by incident
- Reduction in incidents
- Times to detection and resolution
- Increased data trust (NPS scores)
And for Sanchit, the true value of data observability is its ability to improve all of these metrics at once.
“We all have data quality. We all have data monitoring. We’ve all heard lineage. We know what collaboration is. We know what the data resolution process looks like. But all of these were different tools. Four years ago, you had to buy or build your own data quality framework and you’d have to maintain it, and every component required a different process,” said Sanchit.
“Now, imagine a world where all of this is in one place, with no code, no support needed, with AI on top of it. That’s what data observability is. If an organization wants their data to be reliable, communicable, and faster to be fixed and resolved, and they think building all these separate pillars is not worthwhile, then they should look for data observability tools. If you want to be agile, reliable, and faster, you should invest in your data.”
If you’re a data leader, investing in your data quality isn’t a project for tomorrow. It’s the need of the hour today—and every day after.
As this Fortune500 CPG team continues to embrace the centrality of data quality—from customer support to GenAI—Sanchit and his team will be looking to Monte Carlo to power the ship.
To learn more about how your organization can leverage data observability, speak to our team.
Our promise: we will show you the product.
Read more posts.