Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Checkout.com Achieves Data Reliability at Scale with Monte Carlo

Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
One of the fastest-growing companies in Europe, Checkout.com is charting the future of finance and payments. Founded in 2009 and headquartered in London, the company offers an end-to-end global platform that enables businesses and communities to thrive in the digital economy. By nature of its work in the financial services industry, Checkout.com deals with huge volumes of data on a daily basis.
“Given that we are in the financial sector, we see quite disparate use-cases for both analytical and operational reporting which require high-levels of accuracy” says Checkout.com Senior Data Engineer Martynas Matimaitis. “That forced our hands to adopt data observability—or essentially data quality and data freshness—quite early on in our journey, and that became a crucial part of our day-to-day business.”
Checkout.com employs a decentralized data strategy, and data observability is a critical component of that architecture. Observing the full range of the company’s data is no small task: the data team monitors 4600+ data sets, supports 300+ active data platform users every day, and supports 1200+ dbt models that run various transformations on a daily basis.
Martynas is responsible for ensuring the reliability of Checkout.com’s data, which customers rely on to power their financial transactions. As the company scaled, Martynas and his team found that the manual monitors and tests they had established to maintain optimal levels of data quality and freshness were unable to keep pace with Checkout.com’s rate of growth and volume of data.
“We understood that data quality is a crucial thing on our team, so we started with manually-configured monitors and tests for essentially every single pipeline that we were releasing,” explains Martynas. While that system was effective early in Checkout.com’s life, it quickly become unwieldy as the company scaled. As data team members began working with thousands of pipelines, they needed to write individual tests for every pipeline. Whenever a pipeline changed, the data team had to update tests—and that created a bottleneck that interfered with business as usual and threatened data quality.
Martynas and his team needed to improve their approach to solving for data quality in Checkout.com’s fast-paced, fast-growing environment.
“When we had all of our discussions with Monte Carlo, we found that their approach to data observability was the best fit,” says Martynas.
Martynas found that Monte Carlo’s unified UI, its examination of different types of incidents, and its ability to enable Checkout.com to modularize different domains and assign different data sets to different teams best suited his team’s needs.
With Monte Carlo, Martynas and his data team gained visibility into data across domains, scaled their data testing and monitoring, and shifted from being viewed as a perennial bottleneck to a driver of solutions across the company.
Here’s how.
The problem: over-reliance on manual testing and a lack of visibility across domains
Checkout.com’s decentralized data structure and reliance on manual tests and monitors meant that data engineering was a single point of failure for data issues. Multiple product and business teams within the company served as subject matter experts for their own data, and as such they autonomously conducted their own batch data processing, built their own data products, and ran their own data reports. This meant that the data team received multiple small requests from multiple teams on a daily basis but lacked the data ownership necessary to solve these problems efficiently and effectively.
Moreover, as the company migrated toward a data mesh approach and multiple functional areas leveraged data in their work, the data team lacked visibility into data across domains. This visibility deficit threatened the team’s overarching mandate to maintain optimal levels of data freshness, data quality, and data latency.
The system the team had implemented relied on manual testing and monitoring and was not scalable. Martynas and his colleagues found that frequently-failing pipelines required constant updates, and the team grappled with both a slew of false positives and alert fatigue and business-impacting incidents that were detected too late.
The solution: Monte Carlo’s data observability platform
Checkout.com partnered with Monte Carlo to deploy a custom data observability platform that leveraged the following five key components to automate monitoring, centralize UI, and enable faster and more efficient incident management.
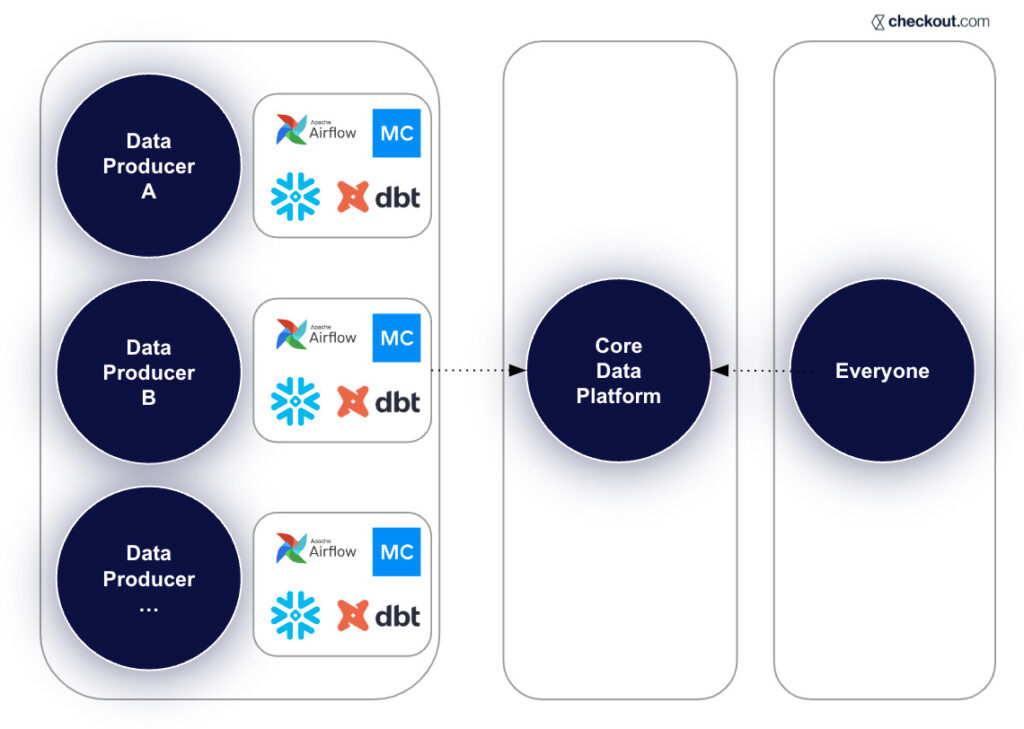
Dedicated domains for data owners
“Giving the power back to the domain owners and the domain experts, I think, is one of the most important steps” in achieving improved data observability, says Martynas.
The company’s data team worked with Monte Carlo to modularize its tooling and thus enable producers across the data platform, which empowered individual teams and reduced pressure on the data team.
Designating dedicated domains “creates an environment where the actual data owners who are the domain experts have visibility into their own data,” says Martynas. “And any issues that actually might come up are directed to them [rather than to the data team], which causes a lot faster turnaround, and there’s no longer a bottleneck on a single team.”
Monitors as code
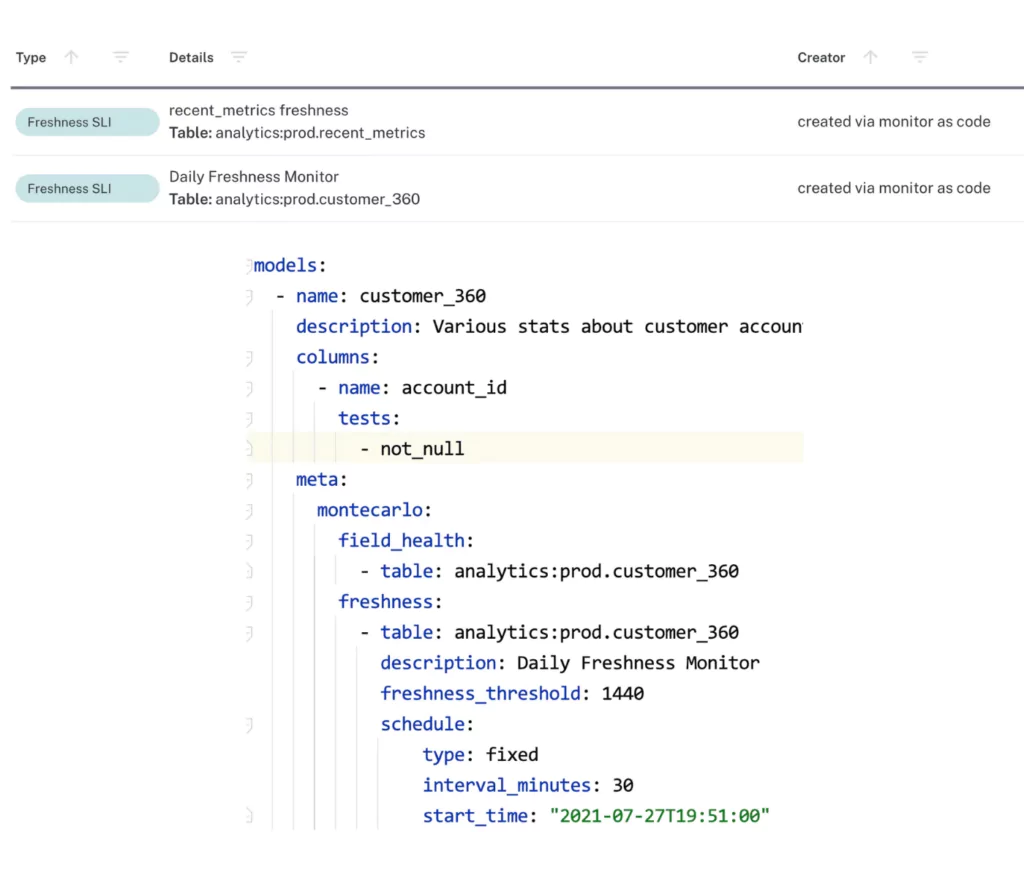
The Checkout.com data team reduced its reliance on manual monitors and tests by adding Monte Carlo’s Monitors as Code functionality into every deployment pipeline. Monitors as Code is a code-based solution that allows data teams to rapidly scale how they would deploy and manage custom Monte Carlo monitors. Checkout.com used this feature to deploy monitors within its dbt repository, which helped harmonize and scale the data platform.
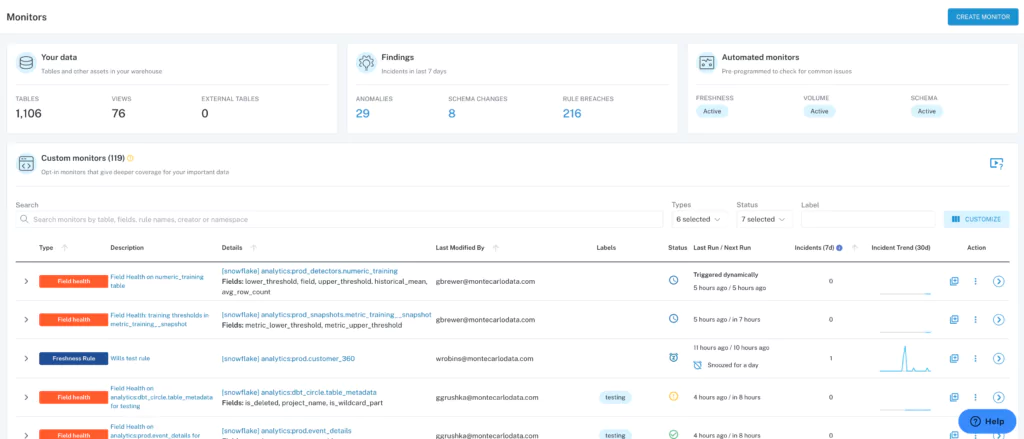
Central UI to manage data incident resolution
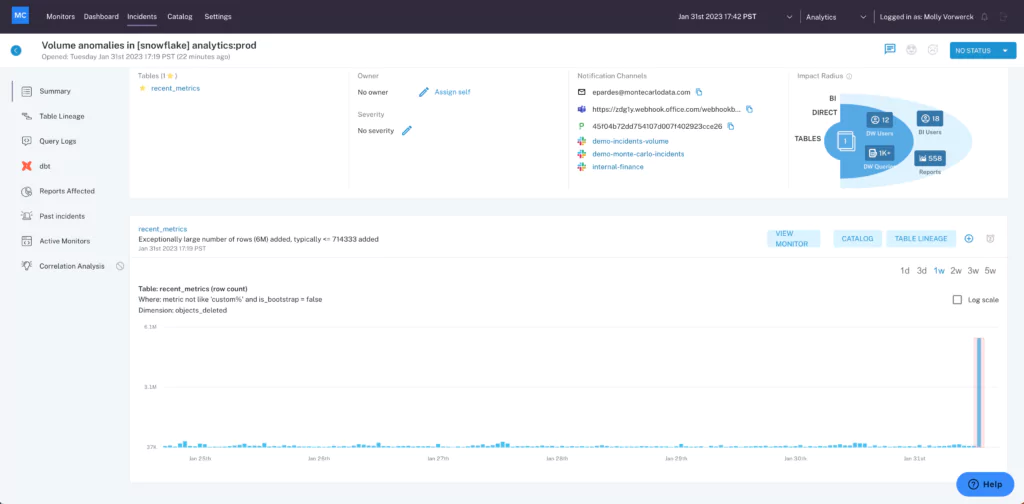
Partnering with Monte Carlo enabled the data team to gain greater visibility over the entire data platform and streamline incident management and resolution by leveraging Monte Carlo’s central UI.
“Monitoring logic is now part of the same depository and is stacked in the same place as a data pipeline, and it becomes an integral part of every single deployment,” says Martynas. In addition, that centralized monitoring logic enables the clear and easy display of all monitors and issues, which expedites time to resolution.
ML-based, opt-in anomaly detection monitors
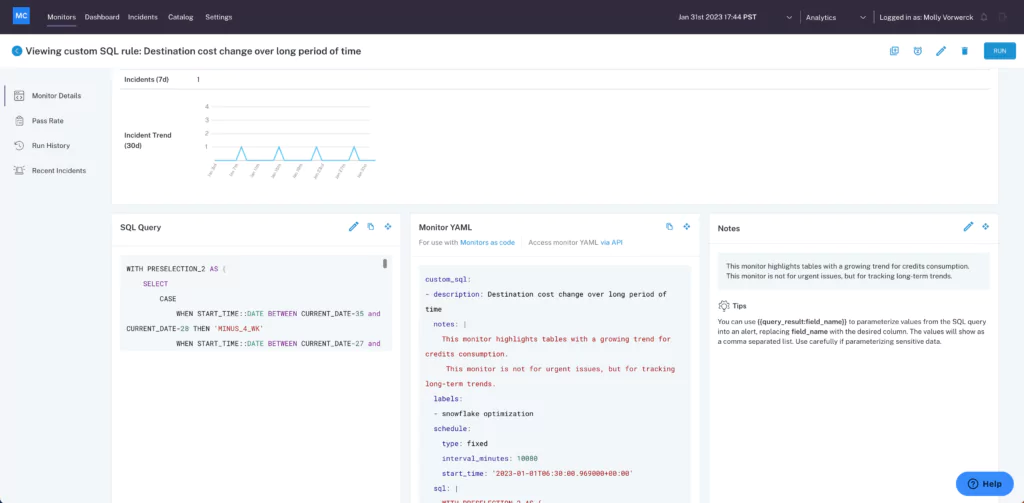
Manual monitoring and data tracking simply wasn’t sustainable for Martynas and his team. Once they deployed Monte Carlo, however, they were able to automate much of this monitoring with Monte Carlo’s machine learning-based anomaly detection monitors.
“ML-based anomaly detection beats manual threshold basically any day of the week,” says Martynas. “If you actually try to look at [schema changes or anomalies] manually in your entire data warehouse, that’s what takes so much effort to actually capture. Now, since these models are actually constantly learning and they’re adapting to all the changes and load patterns, over time you get only very few false positives.”
Implementing Monte Carlo’s ML technology not only streamlined and expedited the data monitoring process, it also improved data quality. “All of these inputs create this combined ecosystem,” Martynas explains. “The more inputs you give, the better the results are, and they become faster and they become way more accurate.”
Integrations with Datadog & PagerDuty for larger incident management workflow for data/engineering Teams
Once Checkout.com had established a strong foundation of data observability with Monte Carlo, the data team was able to add integrations with Datadog and PagerDuty, its monitoring tools of choice, to create a comprehensive incident management workflow for the entire team. The team worked with Monte Carlo to receive fine-grained metrics reports that offer data insights in a highly extendible, repeatable way.
Ultimately, Monte Carlo’s flexible, modular system equipped the data team with the tools it needed to respond to multiple scenarios—both expected and unexpected—in a fast, efficient way.
The Outcomes: Better Visibility, Faster Issue Resolution, and Greater Scalability
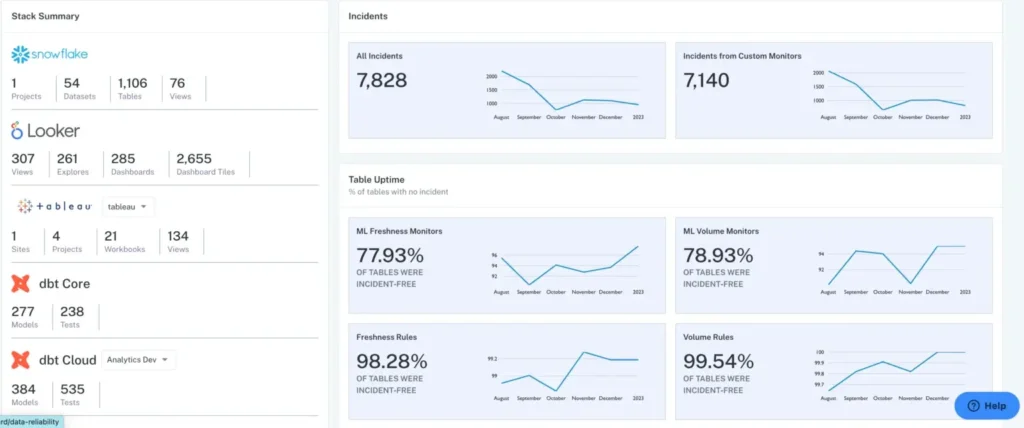
Partnering with Monte Carlo restored efficiency, efficacy, and governance for the data team and enabled faster issue detection and resolution at scale.
Implementing Monte Carlo’s flexible data monitoring tools enabled the data team to detect and resolve issues across Snowflake, Airflow, dbt, and Looker data platforms more quickly. By replacing manual testing and monitoring with Monte Carlo’s automated, ML-based system, Checkout.com saved valuable time for data engineers while gaining confidence that all appropriate issues were being identified.
That automation empowered the data team to scale its data observability approach beyond dbt tests to achieve greater data quality coverage. This not only bolstered the data team’s reputation within the company, it also gave constituents across departments confidence that they were working with the highest-quality, most reliable data possible—a major concern in the financial services industry.
Monte Carlo’s central UI gave the team broader and more transparent insight over the complete data ecosystem. That, in turn, enabled the team to triage data quality issues based on business impact and become leaner, more effective members of the company as a whole.
Conclusion: a culture of data observability at Checkout.com
As one of the fastest-growing fintechs in Europe, Checkout.com relies on huge volumes of data to operate—and it’s imperative that that data is up-to-date and reliable 24/7. Before deploying Monte Carlo, the Checkout.com data team struggled to maintain the high data quality and data observability standards it had set for itself while relying on manual testing and monitoring, lacking overarching data visibility, and operating within a decentralized data architecture.
Monte Carlo helped the Checkout.com data team combat those challenges. Instituting Monte Carlo’s data observability solution empowered Checkout.com to scale beyond manual tests, achieve greater data quality coverage, and identify and resolve issues more quickly.
The scope of solutions Monte Carlo offers has, in turn, affected Checkout.com’s corporate culture.
“Data observability is becoming more than just data quality,” says Martynas. “It’s becoming an actual, maybe even a cultural fit and a cultural approach, how companies or teams are actually looking into their data. Because [companies] look at data as an essential resource that they want to use for their crucial operations or bring out value, they understand that having high-quality data is becoming a crucial part of their business. And I hope that this trend will continue moving forward.”
Ready to learn more about data observability and empower your company to drive adoption and trust of your data? Reach out to the Monte Carlo team today!
Our promise: we will show you the product.
Read more posts.