 Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How Skyscanner Enabled Data & AI Governance with Monte Carlo


Sydney Nielsen
Sydney is Monte Carlo's customer marketing manager. When she's not obsessing over customer happiness, she's playing with her cat, Frieda, sewing, or chasing after her daughter.
For over 20 years, Skyscanner has been helping travelers plan and book trips with confidence— including airfare, hotels, and car rentals.
As digital natives, the organization is no stranger to staggering volume. Over the years, Skyscanner has grown organically to include a vast network of high-volume data producers and consumers, including:
- Serving over 110 million monthly users
- Partnering with hundreds of travel providers
- Operating in 30+ languages and 180 countries
- An fulfilling over 5,000 search requests per second
All told, their apps produce 30 billion streaming events each day. And for years, this enormous amount of data was managed in an enormously complex system.
But since 2020, Skyscanner’s data leaders have been on a journey to simplify and modernize their data stack — building trust in data and establishing an organization-wide approach to data and AI governance along the way.
We were excited to sit down with Skyscanner’s Principal Software Engineer JM Laplante and Director of Engineering Michael Ewins — fresh off his inspiring presentation at Big Data London — to learn how their teams are harnessing data lineage and observability to enable data governance at scale.
Table of Contents
The challenge: more data led to more complexity
At the start of the decade, Skyscanner was facing a maze of data complexity. Disparate, disconnected systems made it difficult to join data effectively and get quick answers to questions—and a mix of institutional knowledge and guesswork was required to root cause and resolve problems in their pipelines.
According to Michael, Skyscanner’s complex systems and pipelines, “ led to data downtime, data delays, and incomplete data — and all of this was causing problems for our customers. They couldn’t get consistent answers and obviously, that made them unhappy.”
The data team at Skyscanner began to re-evaluate their data stack, looking for ways to reduce data pipeline issues. After one particularly tough week in the winter of 2021, when marketing data was disrupted by daily incidents and downtime, a group of data engineers decided to create a full diagram of the data systems.
It took eight people from different teams two full days to untangle the pipelines and produce a labyrinth of a diagram. Michael then managed to color-code the different lines for the major data sets. “It would just melt your brain,” he told us. “It was a spaghetti lineage diagram.”
The challenge: data quality became unmanageable across bespoke tools
This spaghetti lineage wasn’t totally surprising. Skyscanner has hundreds of engineers, data scientists, and data analysts. And most teams were operating with siloed pipelines — they had bespoke solutions to check and manage data quality. But with a complex system and large volumes of data, teams couldn’t possibly manage data quality effectively—much less consistently.
The data teams were maintaining 30,000 datasets, and often found anomalies or issues that had gone unnoticed for months. This meant business teams were operating with less-than-ideal data, and once an incident was detected, the team had to spend painstaking hours reassembling and backfilling datasets.
“The longer you go with a data quality issue, the more time that will take an engineer to backfill the data to rectify the problem,” JM told us. “That is not a cheap thing to do.”
Engineers would devise ad-hoc manual data quality checks when incidents occurred, but the team knew they needed an automated, scalable approach to detecting anomalies much faster and minimizing the cost of data downtime.
The solution: simplified systems and end-to-end data observability
As data leaders came to terms with the challenges they faced, they formed a “data tribe” to bring together data specialists across the company. They began to focus on three pillars: improving reliability, building trust, and ensuring people could make data-driven decisions quickly.
While their first instinct was to create more systems and pipelines — “in an attempt to build our way out of trouble”, as Michael said — the true answer was to reduce.
Over the next few years, the team assembled a streamlined data stack, including Kafka, AWS Kinesis for streaming, Databricks for Spark processing, Tableau for reporting, Amplitude for product analytics, MLFlow for machine learning, Unity Catalog for discoverability and access control, and Monte Carlo for data observability.
The team considered a few options for data observability, looking for a solution that would automate basic quality checks and provide lineage visibility when data incidents occurred. Ultimately, Michael and his team chose Monte Carlo for a few reasons, including its robust integration with Databricks (a non-negotiable for their team), thought leadership that resonated with their experiences, and Monte Carlo’s ability to deliver on critical success criteria.
At the same time, data leaders took a hard look at the volume of their data.
“We had 30k datasets and needed to focus on the most important business use cases,” Michael said in London. “We identified our business-critical use cases, followed the tangled lineage back, and found that there were about 350 business-critical sets. Only 1% of our data was business-critical.”
This was a huge disconnect. Skyscanner’s data teams needed a simplified approach to reliability that would focus on those business-critical assets. With their modern data stack assembled, Michael and his team created a framework called the “healthy data pyramid” to focus their efforts and more effectively communicate their plans to the larger organization.

The team began using the pyramid to quantify and measure data quality across its business-critical datasets, gradually moving each dataset up from level zero as it evolved. Here’s what that looked like:
- Level 1 — assigning and documenting ownership
- Level 2 — understanding who uses data and where it comes from
- Level 3 — answering questions around data quality dimensions such as completeness and freshness
- Level 4 — increasing specific column-level and field-level checks for the most important datasets based on business-critical assets.
Michael and his team used Unity Catalog to track and implement levels one and two, and relied on Monte Carlo for levels three and four. Now, with the ability to automate clear end-to-end lineage and implement appropriate quality checks by dataset, the team could begin scaling reliability to actually improve data trust across the organization.
The outcome: Faster incident resolution and increased data ownership
Data observability delivers automated anomaly detection, intelligent alerting, and end-to-end field-level lineage to help diagnose and expedite incident resolution. Skyscanner’s data team can now detect data incidents in moments, not months.
Michael also credits Monte Carlo with supporting their goal of helping teams not just assign data owners, but act like them. He specifically cited the Status Update Rate feature, which provides visibility into how quickly teams are taking action on alerts.
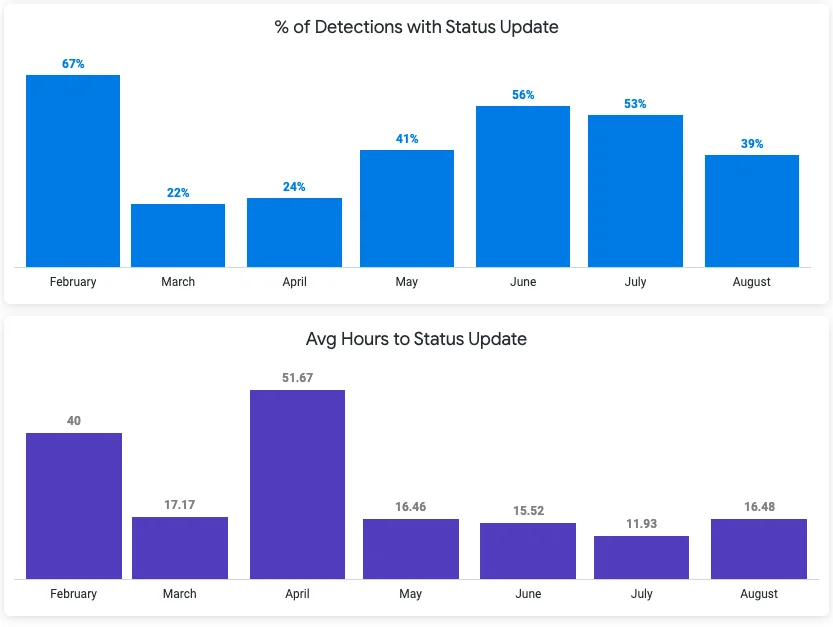
“It’s not enough to purely introduce the monitoring and alerts — you’ve actually got to do something about it,” Michael said. “The Status Update Rate aligns very well for us with our behavioral change.”
The outcome: less time and resources spent on data quality
Skyscanner’s data teams are using data observability to not only address incidents more quickly, but prevent them in the future.
As JM told us, “When a data incident occurs, we can see gaps in data quality monitors — and put them into other data sets as well, so if the issue reoccurs, we can flag it automatically. That’s a cost saving, because future incidents are easier to detect.”
And when incidents are detected more quickly, issues can be resolved and backfilled more efficiently—reducing costs and limiting the business impact of data downtime in the process.
“In the past, we might have to backfill six months of data to when the issue started,” JM told us. “But if we can detect an issue in a day, then a one-day backfill can be a lot cheaper. There are lots of benefits, like engineering time, that we’re seeing from data observability.”
The outcome: more trust in the data
Ultimately, their fresh approach to data governance and ownership is helping Skyscanner achieve the goal they set out to deliver five years ago: building trust in the data.
“Our mission, essentially, is to help the organization trust their data so that we can drive faster, better decisions and create better products,” Michael told us. “These changes do take time, and we’re still on the journey. But we now have all of our data in Unity Catalog, and we’re now using this trusted data in our ecosystem to power what we call our data and AI flywheel.”

Those 30 billion events produced within Skyscanner’s ecosystem each day are now transformed, enriched, used to power machine learning models, served to reporting systems, and sent back to customers to provide better experiences.
“You could argue that all of Skyscanner is basically data and algorithms,” Michael told us. He believes that reliable, trusted data is the key to Skyscanner’s future success.
Looking ahead: the future of data quality at Skyscanner
As Michael, JM, and their teams continue on their journey to data governance, they plan to explore how data observability can support their ongoing adoption of AI tools and LLM-powered customer experiences. Already, they’re using Monte Carlo to spot data quality issues in ML training data.
“We have bespoke code that will identify hallucinations or undesirable outcomes in the outputs of a large language model,” JM told us. “We can set thresholds in Monte Carlo and then use the alerting and UI to declare incidents in our LLM outputs. Those capabilities fit into the picture for AI.”
Improving data quality and reliability will also be paramount as Skyscanner, like many companies, moves to increase self-serve data access across their organization. As more teams learn to check data quality metrics and understand the lineage of their data sources, the reliability of their data will increase as well.
“What we’re trying to drive is ‘Act like an owner.’ You’re responsible for the data you produce, but also for the data you consume,” Michael told us. “You want to be consuming good quality data, rather than just any random stuff. Collaboration and ownership have been part of our cultural values since I joined Skyscanner five or six years ago — they’re part of our DNA. But we need to drive that through data as well.”
Ready to see how data observability can improve incident response and build trust at your organization? Let’s talk!
Our promise: we will show you the product.
Read more posts.



