Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Implementing Data Lineage in Python: Manual Techniques & 3 Automated Tools


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
It’s 9am and you’re rushing to generate a report for your 10 a.m. meeting. But as you scan the numbers, something feels… off. Sales weren’t stellar this quarter, but you didn’t expect them to be this low. Something’s definitely wrong. Now, what do you do?
Without Python data lineage, you could waste valuable time hunting through databases, running SQL queries to trace the numbers back to their source. Or you could dig through old emails, hoping to find the Excel files where each store reported their data—praying that a simple typo is to blame.
But as you begin to scroll through your emails, you spot a message from IT that you brushed off last week: The data lineage system is finalized and ready for use. A wave of relief washes over you. With just a few clicks, you trace the numbers back to their source, identify the error, and correct it. Crisis averted. Your report—and your morning—is saved!
Table of Contents
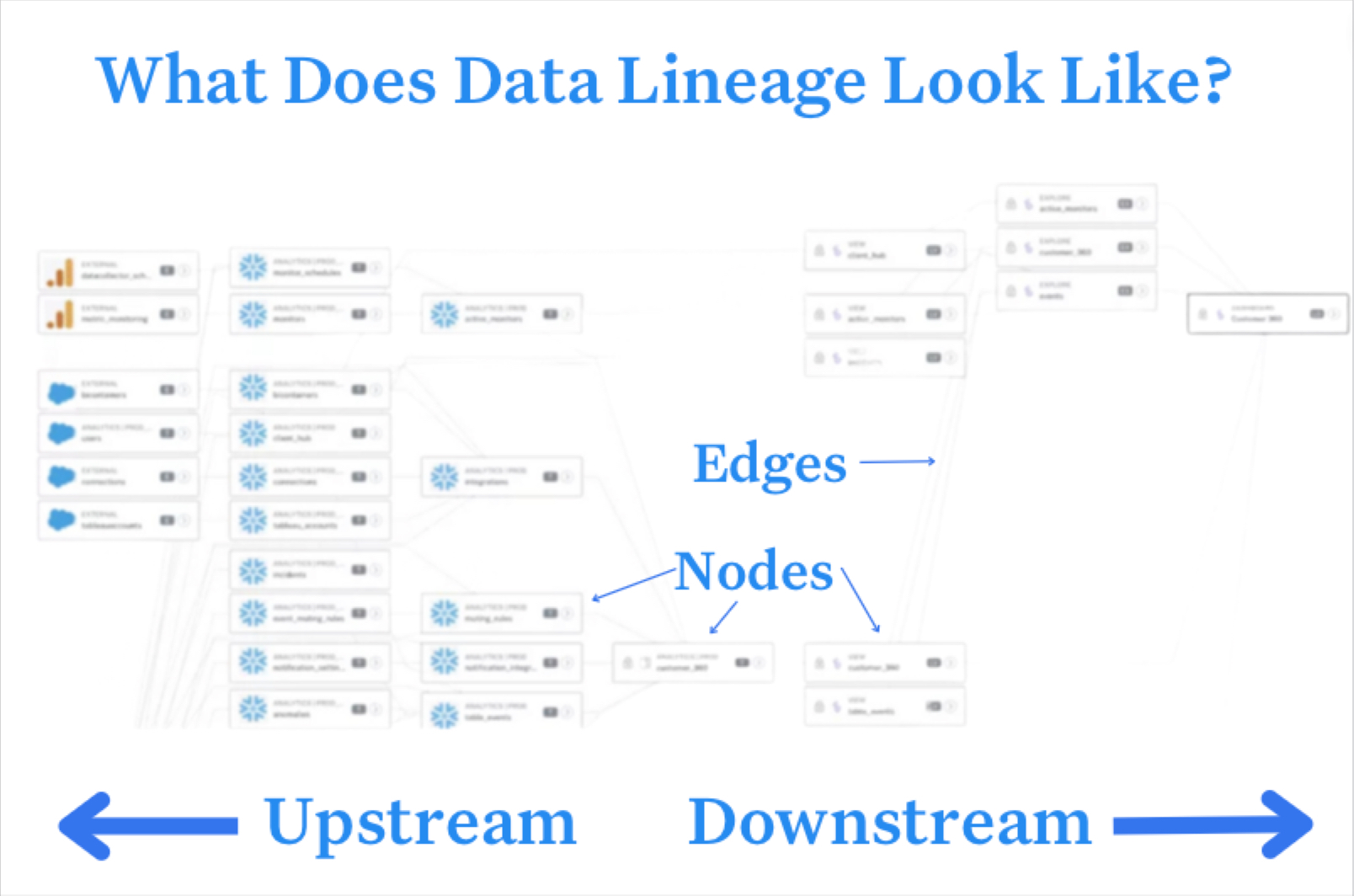
What is Data Lineage?
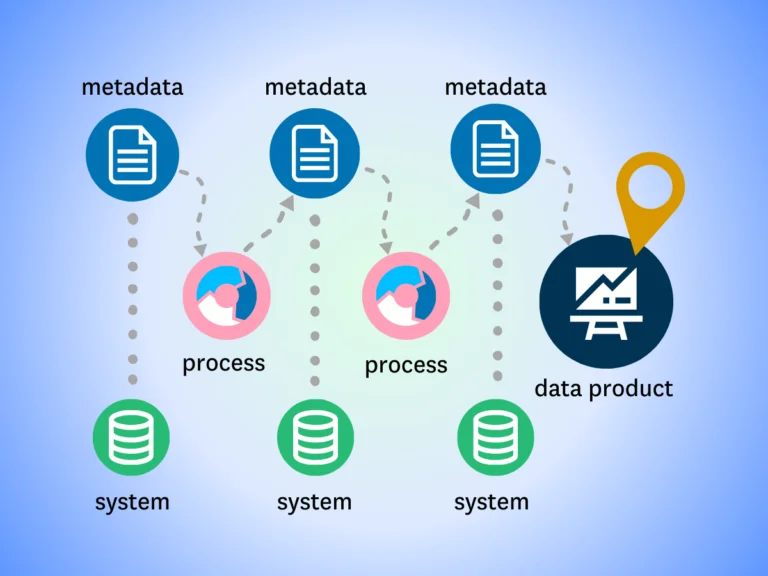
Data lineage is the process of tracking data as it moves and evolves throughout its lifecycle, from creation to consumption and eventual deletion. This involves documenting many parts of the data’s journey, including where it was stored, who owned it, and how it was uploaded, modified, and accessed.

Tracking data lineage is especially important when working with Python, as the language is so easy to use that you can end up digging your own grave if you start making large unintended changes to your most important datasets. With a data lineage system in place, it is usually only a few clicks in a nice interface to find out where the data could have been corrupted.
Automated Tools for Python Data Lineage
So how can we easily add data lineage to our Python workflows?
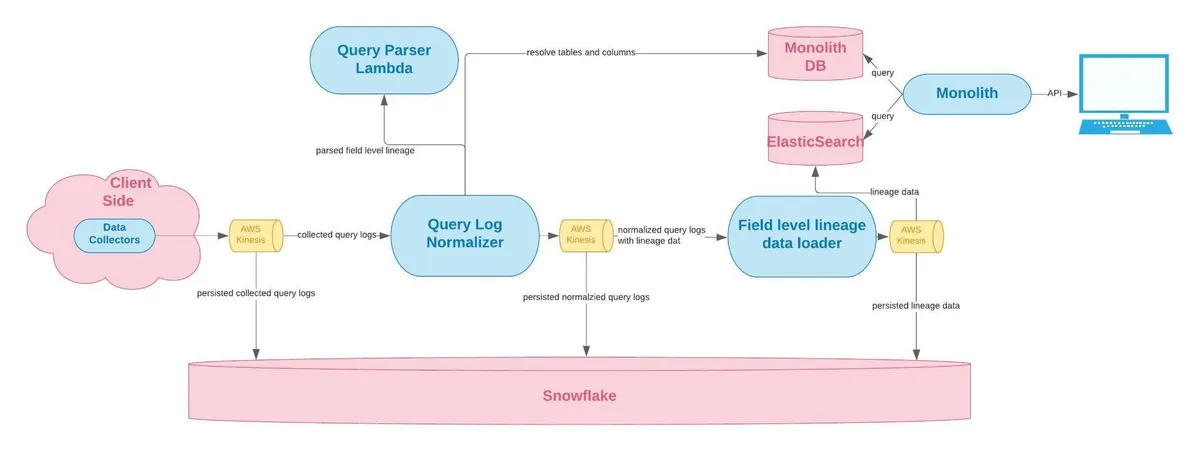
The standard practice is to choose one automated data lineage system, like OpenLineage or Monte Carlo, and then have each of your other tools and scripts report to it whenever they access or modify data.
Here is a list of the most popular tools for data lineage in Python:
- OpenLineage and Marquez: OpenLineage is an open framework for data lineage collection and analysis. Marquez is a metadata service that implements the OpenLineage API. Together, they are the most popular standardized way to collect, store, and analyze metadata about data pipelines, across various tools and systems.
- Apache Airflow Lineage Plugin: It is also common to use plugins for your existing pipelines to track data lineage. The popular open source Apache Airflow platform has one such plugin for also using OpenLineage. It allows you to define inlets (data sources) and outlets (data destinations) for your Airflow tasks. This information is then used to automatically generate a graph of data dependencies across your workflows, providing a clear picture of how data flows through your Airflow DAGs.
- Great Expectations: While usually a data validation framework, Great Expectations indirectly also contributes to data lineage. It allows you to create “expectations” about your data, which can be used to validate data quality at various points in your pipeline. By tracking these validations, you can gain insights into how data changes and moves through your systems.
Each of these tools offers a different approach to capturing and managing data lineage, allowing you to choose the one that best fits your existing infrastructure and needs.
Manual Data Lineage Workflow in Python
But if you are just starting out building a new data system, or your current tooling isn’t supported by an automated tool, you may have to do some manual tracking using Python’s built-in logging.
While not as robust, it is very easy to get started. For example, here is how you would add data lineage tracking to a common scikit-learn workflow:
# Set up logging
logging.basicConfig(filename='data_lineage.log', level=logging.INFO)# Load dataset
iris = datasets.load_iris()
X, y = iris.data, iris.target
logging.info(f"Loaded dataset: {iris['DESCR']}")# Split the dataset
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
logging.info(f"Split data into train and test sets with test_size=0.2")# Train model
model = RandomForestClassifier()
model.fit(X_train, y_train)
logging.info(f"Trained RandomForest model with parameters: {model.get_params()}")Challenges in Python Data Lineage
But what if we forget to log something?
That is the main reason to try and avoid manual lineage tracking when possible. You don’t want to process terabytes of data only to find out later you forgot to log one transformation that happened to mess everything up.
And this isn’t only an issue brought about by rushed interns. In many ways, Python’s ease of use also sets it up for failure when trying to track data lineage. Take for example this function for appending to a list:
def append_to_list(new_element, to_list=[]):
to_list.append(new_element)
return to_listBecause of the way Python handles mutable default arguments, instead of two calls to this function producing this:
first_list = append_to_list(5) # Expected result: [5]
second_list = append_to_list(9) # Expected result: [9]You instead get this:
first_list = append_to_list(5) # Actual result: [5]
second_list = append_to_list(9) # Actual result: [5, 9]And these types of implicit in-place changes are widespread for Python. They can come from list comprehensions, lambda functions, or really any other data package like Numby, Pandas, or Scikit-learn.
Boost Data Trust with Monte Carlo’s Automated Data Lineage
So with all of the challenges of managing a manual lineage system, an automated platform is definitely the right choice. But why stop there when you can go further with an entire data observability suite instead?
While lineage focuses on tracing data origins and transformations, data observability covers real-time monitoring, anomaly detection, and performance metrics. It allows you to go further and proactively identify and resolve data issues, ensure data reliability, and gain deeper insights into their data system’s overall health and behavior.
Enter your email below to learn more about how data observability with Monte Carlo can take you further than just data lineage tracking.
Our promise: we will show you the product.
Read more posts.