Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage How to Make Data Quality (A Little) Less Painful for Analysts

As a data analyst, you’re responsible for delivering trusted insights to your stakeholders.
Unfortunately, that trust often comes at the cost of your time (and maybe a little sleep as well).
The truth is, most analysts lose hours profiling their data, identifying thresholds, creating manual rules, and following up on data quality issues—all to make sure the data products they deliver to stakeholders meet six dimensions of data quality or more. And every hour that’s spent on data quality is another hour that can’t be spent delivering value.
What’s a data analyst to do?
Below are five ways you can take data quality off your endless to do list—and get a better night’s sleep in the process.
Automate test creation for baseline rules
If there’s one thing that’s true about data it’s this: it gets bigger.
Unfortunately for most analysts, scaling data quality monitors to validate critical baseline dimensions—like timeliness, completeness, and uniqueness—is a disturbingly manual process.
From duplication and version control to coverage tracking and maintenance, each step in the testing process is another layer of complexity to be managed by hand in the time-devouring black-hole that is manual testing.
It’s tedious with five tables. It’s impossible with 500.
But if manual baseline monitors are a time killer, then automation is the antidote.
Repetitive manual tasks are always the best candidates for automation—and with solutions like data observability, auto-scaling baseline monitors are available right out of the box.
By automating baseline rules for critical data quality dimensions, data teams can recover hours of time that would otherwise be lost to routine monitor creation and free up analysts to deliver even more value for stakeholders in the process.
Leverage AI-powered monitor suggestions for business rules
You don’t know what you don’t know… and that’s certainly true for the millions of ways your data can break.
But even if you could predict every possible permutation of bad data—which you can’t—you wouldn’t be able to manually define and write all those data quality rules to cover them.
Unlike baseline rules, which provide broad general coverage across an entire database, business rules provide specialized coverage designed to monitor for specific problems that are unique to a given table or business case.
For instance, you may want uniqueness as a general principle across a given table, but asking for a customer_state column to be 100% unique would be silly. You don’t want a spike of nulls for most tables, but you probably don’t want ANY nulls on a column that’s near 100% complete like an ID key. Or, you may want to alert on future values that exceed certain thresholds, but it would take hours pouring through an Excel spreadsheet to define those thresholds on your own.
This tailored approach to quality coverage makes business rules difficult to scale programmatically. However, just because you can’t automatically apply a given business monitor doesn’t mean you can’t still automate its definition and thresholds.
Monitor Recommendations—like those available from Monte Carlo—help analysts identify and deploy the right machine learning monitors at the right time to deliver quick and tailored data quality coverage for critical tables.
From column-matching for email formats to Null rates for ID fields, leveraging historic data patterns into an AI-powered monitor recommendation tool will not only simplify the discovery of new risks but also the definition and deployment of field-specific data monitors to cover them.
Deploy no-code validation tools
If you’re operating from an established governance framework, your data will almost certainly have some kind of standards to conform to—and when it doesn’t, you’ll need to know about it.
Validating standards has historically required setting hard thresholds for important fields—like validating timestamps to confirm when a record was updated—and then enforcing governance protocols when standards aren’t met. The problem here—as you might have guessed—is that most data teams still depend on manually crafting SQL statements to validate those individual records.
More than simply being tedious to create (which they are), validation monitors also often require analysts to provide the requirements to technical data engineers instead to express the rule more effectively in SQL.
And the only thing worse than being on the hook for writing a data validation monitor is waiting on the hook for a data engineer to write it instead.
Using a no-code validation solution is one of the fastest ways to streamline validation and provide monitor creation power to the analysts with the domain expertise to define them.
In this instance, a monitor is created using a simple form to set standards based on common validation checks. For example, once you’ve selected your table, field, and operator in Monte Carlo’s UI, relevant metrics will automatically appear in the drop down menu to select.
Numeric columns have options to validate conditions such as NULL, zero, not a number, negative, or manually entered ranges. Strings can also be monitored to check for specific completeness metrics, formats, and manually entered values. You can even build complex validations involving multiple variables and conditions to cover more specialized business cases.
(You can see the full list of metrics available from Monte Carlo here.)
No-code validation monitoring empowers all members of the data team—regardless of SQL proficiency—to deploy deep data quality monitors and enforce governance standards at scale.
Route data quality alerts to your domain Slack channels
How many times have you learned about a data quality issue from a broken dashboard? Probably too many.
As an analyst, you’ll rarely discover data quality issues before they’re impacting something downstream. That leaves a lot of time for inaccurate insights to make it to the wild.
What’s more, even if data engineers ultimately fix the problem, you’ll likely still be tapped to help with root cause analysis along the way—and that means you’ll need to be informed at the right time, in the right place, and with the right information to be effective.
To expedite incident discovery and simplify the RCA process, data teams should centralize data quality alerts and incident communication through a domain-specific comms channel.
By leveraging something like Slack for alerts and incident routing, data teams can keep upstream and downstream stakeholders informed simultaneously, while also supporting incident owners with the right RCA context to expedite triage and resolution when the time comes.
What’s more, a robust alerting integration (like those available through Monte Carlo) won’t just clarify problems and solutions—it can also be used to clarify process ownership as well. By leveraging features like Monte Carlo’s data product owners into your centralized alerting strategy, you can make it easy to understand at a glance who owns what during the incident management process and keep each owner informed about the latest status of the issue.
Conduct regular data audits to prioritize coverage and deprecate unused tables
As an analyst, there’s nothing worse than a business user leveraging a report with stale tables—except maybe that business user ignoring your reports altogether.
But with the average analyst supporting hundreds of tables and multiple interdependent data products, it’s hard not to have a few gaps now and again.
No data team can provide complete data quality coverage for all their tables all the time. And the reality is, they don’t need to. Like most things in data, prioritizing data quality coverage means optimizing for impact, not volume. That includes identifying gaps for the tables that see the most use—and deprecating the tables that don’t.
In other words, to optimize data quality coverage, you need to get in the habit of auditing your data.
I recommend looking at two criteria to optimize coverage:
- table usage—how often a table is leveraged into a critical data asset
- and quality coverage—how completely critical tables are covered for the most important data quality dimensions.
Auditing table usage
By auditing table usage, you’ll be able to validate which tables impact the most downstream users—and consequently where your efforts can provide the most immediate value—as well as what tables might be candidates for easy depreciation based on low-utilization or the value of their downstream products.
While there are plenty of long and painful ways to handle this step in the process, a comprehensive end-to-end field lineage tool can easily provide this information at a glance for each of your data products. If an asset is important, you’ll immediately know which tables are feeding it—and which tables are just soaking up storage space.
Of course, if you like parsing SQL, that’s always an option too.
Auditing data quality coverage
Comprehensive quality coverage is essential for reducing risk to your most critical data products.
The key distinction here being “critical”.
Tables that aren’t frequently utilized or supporting at least one critical data product probably aren’t tables that need comprehensive coverage. That doesn’t mean those tables don’t matter (necessarily), but it does mean they won’t require a regular coverage audit.
However, for assets that do feed mission critical data products—as identified in part one of your audit—that comprehensive coverage is non-negotiable.
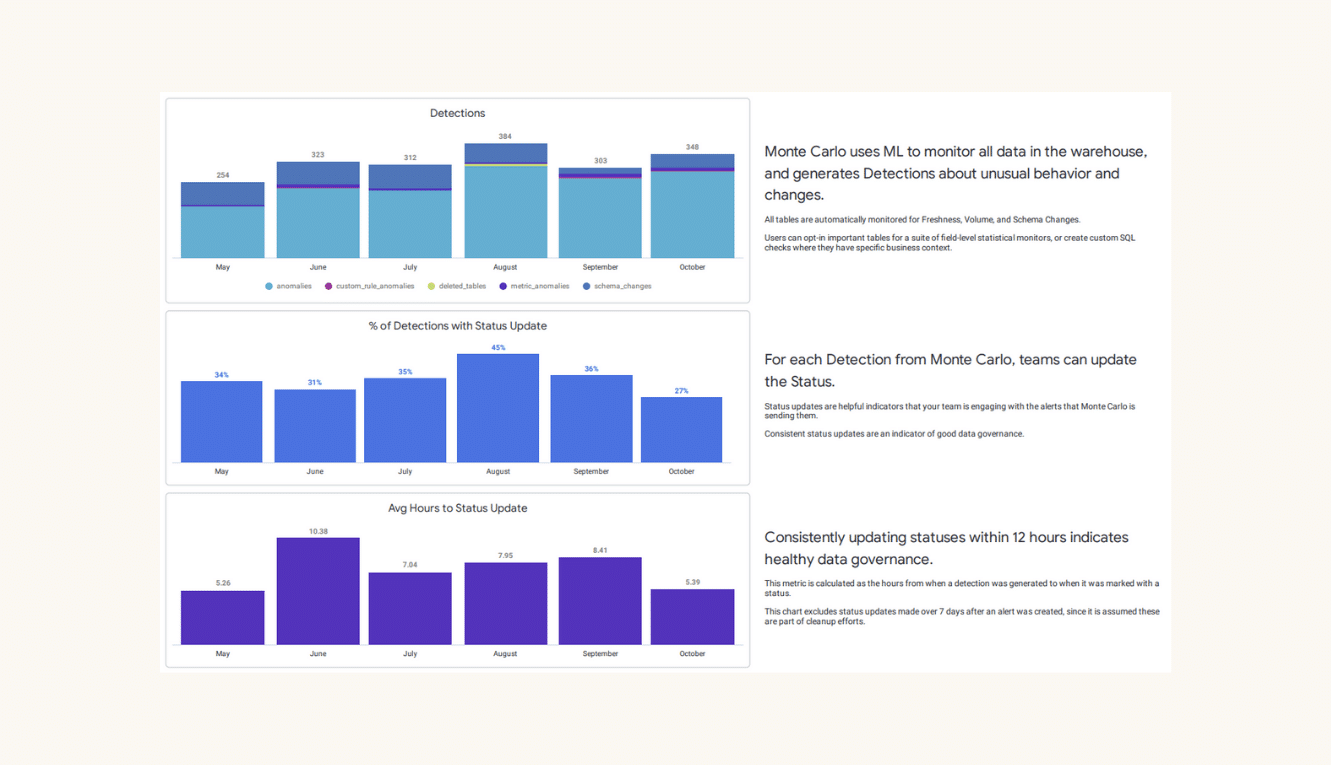
So, what is data quality coverage? Usually represented as a percentage, data quality coverage is a representation of how many monitors have been deployed across a given product to cover critical data quality dimensions.
Historically, coverage would be applied and audited by table. However, tools like Monte Carlo’s Data Product Dashboard have now made it possible to understand this rule coverage in context by managing coverage by data product instead. With product-based coverage metrics, you can understand how well your critical tables are being monitored in aggregate—and quickly apply the right monitors across tables when they aren’t.
Data observability is your data quality pain reliever
Automation may not be the key to happiness—but when it comes to a data analyst’s workflow, it’s definitely the key to reducing data quality pain.
Unfortunately, operationalizing data quality tooling is challenging at the best of times—and when you consider each of the tools required to automate data quality management at scale, that challenge becomes near-to-impossible.
But, what if all of that automation could be rolled up into a single solution that could support not only the analysts managing the products but also the data engineers, architects, and data leaders supporting the platform as well?
Enter data observability. With AI-powered monitors, automated field-level lineage, and RCA insights built in, data observability makes it easy to detect, triage, and resolve data quality issues at any scale.
And Monte Carlo is the only data observability solution that provides all that essential automation in a single platform designed for everyone on the data team.
SQL experience not required.
As a data analyst, your time should be spent driving insights, not setting data quality rules. With data observability from Monte Carlo, you can take data quality off your to-do list for good—and put ‘a good night’s sleep’ back on the agenda in the process.
Our promise: we will show you the product.
Read more posts.
![[VIDEO] Introducing Data Downtime: From Firefighting to Winning](https://www.montecarlodata.com/wp-content/uploads/2020/08/My-Post-10.png)