 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Monte Carlo First To Detect Breaking Code Changes With New Databricks, GitLab Integrations


Peter Milligan
Peter leads public relations and analyst relations at Monte Carlo.

Michael Segner
Michael writes about data engineering, data quality, and data teams.
Monte Carlo, the data observability leader, today announced industry-first features that help identify Databricks query code changes and GitLab pull requests that result in data quality incidents.
To provide business insights and power critical applications, engineers extract data from a variety of sources and then aggregate and transform it into the form required for consumption.
Changes in that transformation query code–whether simple mistakes or intentional updates with unforeseen consequences–are one of the primary causes for data quality issues.
Resolving these incidents is a time-intensive process. According to a Monte Carlo and Wakefield Research survey of more than 200 data professionals, it takes an average of 15 hours to resolve the root cause once the anomaly has been detected.
“Based on our experience monitoring more than 10 million tables, approximately a third of data incidents stem from code related root causes,” said Lior Gavish, CTO and co-founder, Monte Carlo. “By increasing visibility into relevant code changes and pull requests, we can help teams reduce the resulting data downtime by 80 percent or more.”
Monte Carlo is the only data observability provider that accelerates the resolution of code-related data quality incidents by surfacing query logs from Databricks SQL Warehouse as well as cloud native data warehouses such as Snowflake, AWS Redshift, and Google BigQuery.
Monte Carlo also links GitHub and now GitLab pull requests to relevant data assets, allowing data teams to quickly assess which code updating events have impacted data quality.
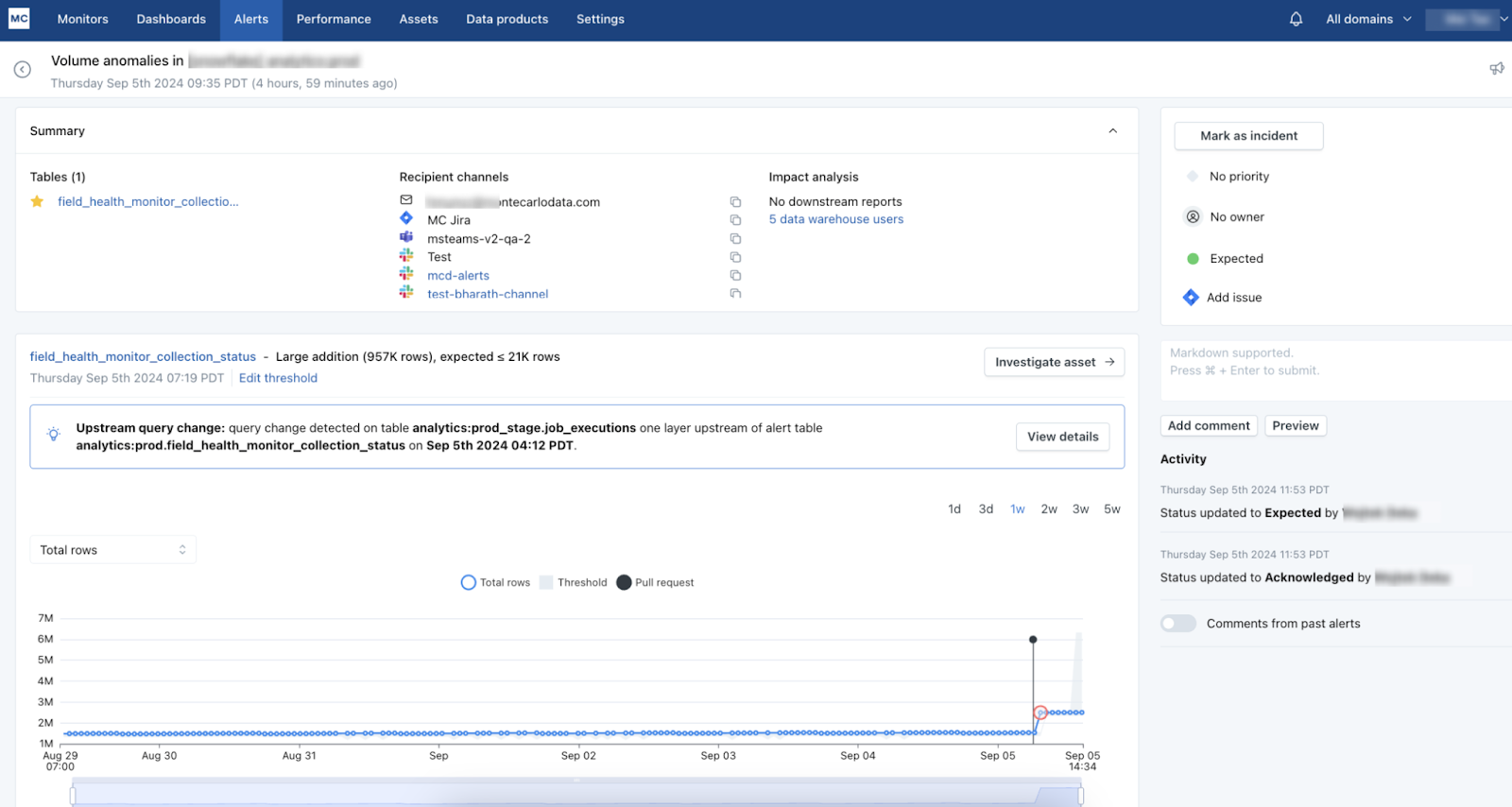
Anomalies can also be automatically correlated directly to specific query changes or pull requests based on when and where in the pipeline they occurred.
“Historically, data quality solutions have been focused on detecting data quality incidents,” said Barr Moses, CEO and co-founder, Monte Carlo. “Our vision is to take the next step and provide visibility into the three primary ways data breaks: problematic data sources, system failures, and code changes. Accelerating the root cause analysis process makes data teams more efficient, and reduces the risk that poor data quality will negatively impact business operations and investments in AI.”
Building The Data Observability “Data, System, Code” Framework
Incident management and resolution is a core focus of Monte Carlo’s development roadmap. The data observability platform recently announced the DataOps Dashboard, which enables teams to measure and improve key operational metrics such as the number of data incidents as well as the average time to respond and resolve for each team.
Monte Carlo is also prioritizing support for GenAI related pipelines with recent Pinecone vector monitoring and Kafka lineage announcements.
To learn more about Monte Carlo visit: https://www.montecarlodata.com/
Our promise: we will show you the product.
Read more posts.




