Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
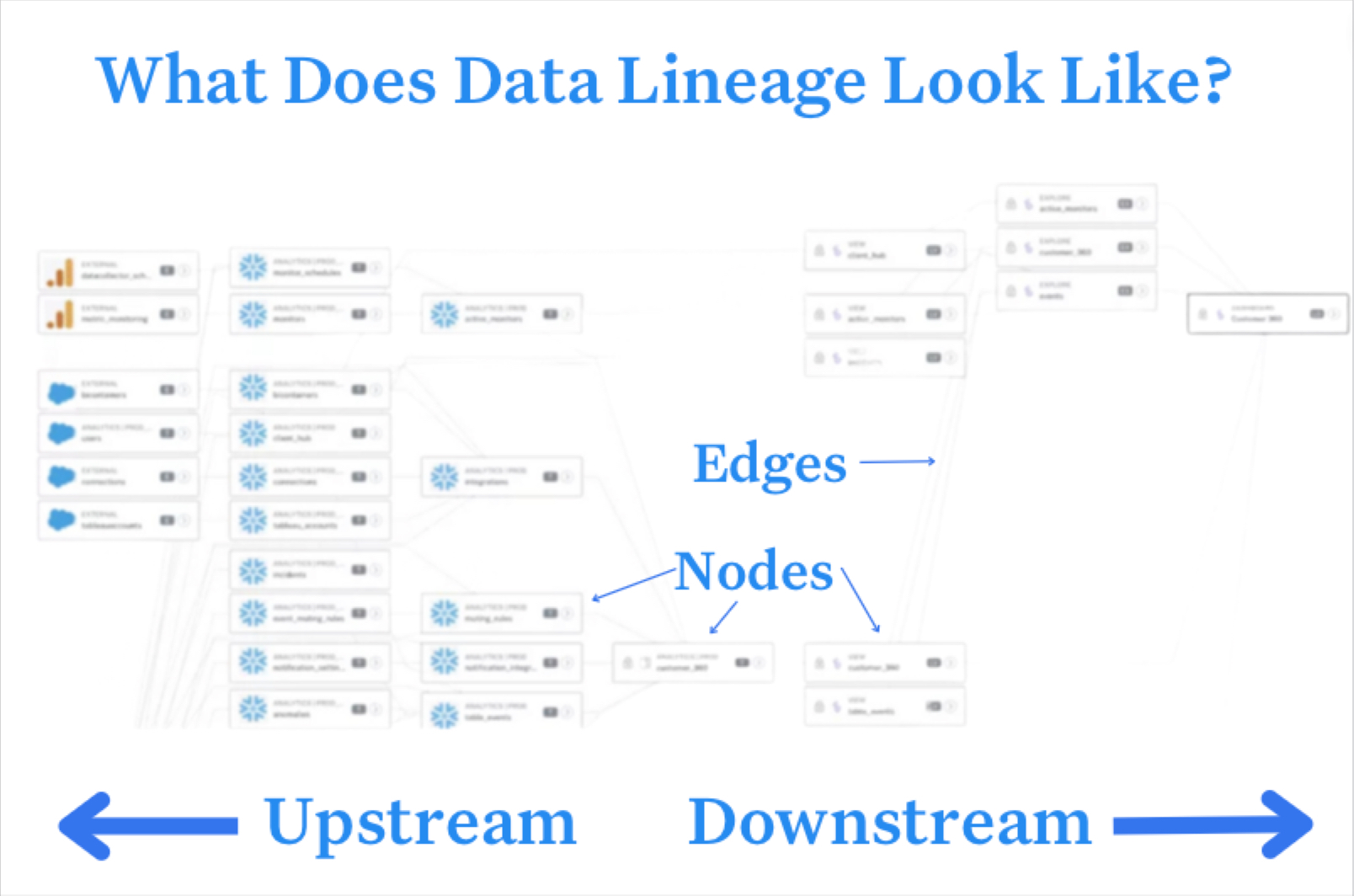
The ULTIMATE Guide To Data Lineage Now Featuring: Kafka Lineage

Michael Segner
Michael writes about data engineering, data quality, and data teams.
The majority of data ingestion today involves batch pipelines that extract data at predefined intervals. For example, every hour all new updates in Salesforce will be extracted and loaded into the central data warehouse or lakehouse.
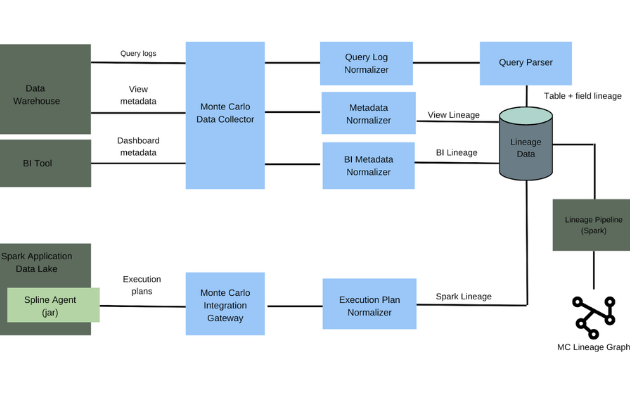
Efficiently monitoring and observing these pipelines end-to-end is essential to data reliability. This is an area Monte Carlo pioneered with automated machine learning monitors to detect data freshness, volume, quality and schema anomalies alongside data lineage to trace the origin of the incident. Also known as data observability.
And while batch processing is still prevalent, data streaming is rapidly becoming widely adopted to support use cases where data timeliness is paramount. Instead of processing data in intervals, data is extracted and loaded for each event as it occurs.
The need to process this data for analytical dashboards, machine learning models, and Gen AI applications still exists as does the need for this data to be reliable and high-quality. So while data will stream directly from service to service or application to application, it also frequently ends up in a data warehouse or lakehouse.
Which is why we are excited Monte Carlo continues to support the most robust data streaming lineage capabilities of any data observability solution. These capabilities are crucial in enabling data teams to resolve incidents and trace data flows (and data incidents) across their data streams, transactional databases, and warehouse/lakehouses.

Let’s dive into some details.
Table of Contents
Supporting the many flavors of Kafka
Apache Kafka is an open-source technology that is leveraged by many different processing frameworks and managed solutions.
Today, Monte Carlo connects with Kafka clusters and Kafka Connect clusters through Confluent Cloud, AWS MSK, self-hosted platforms, and other cluster providers such as Aiven.
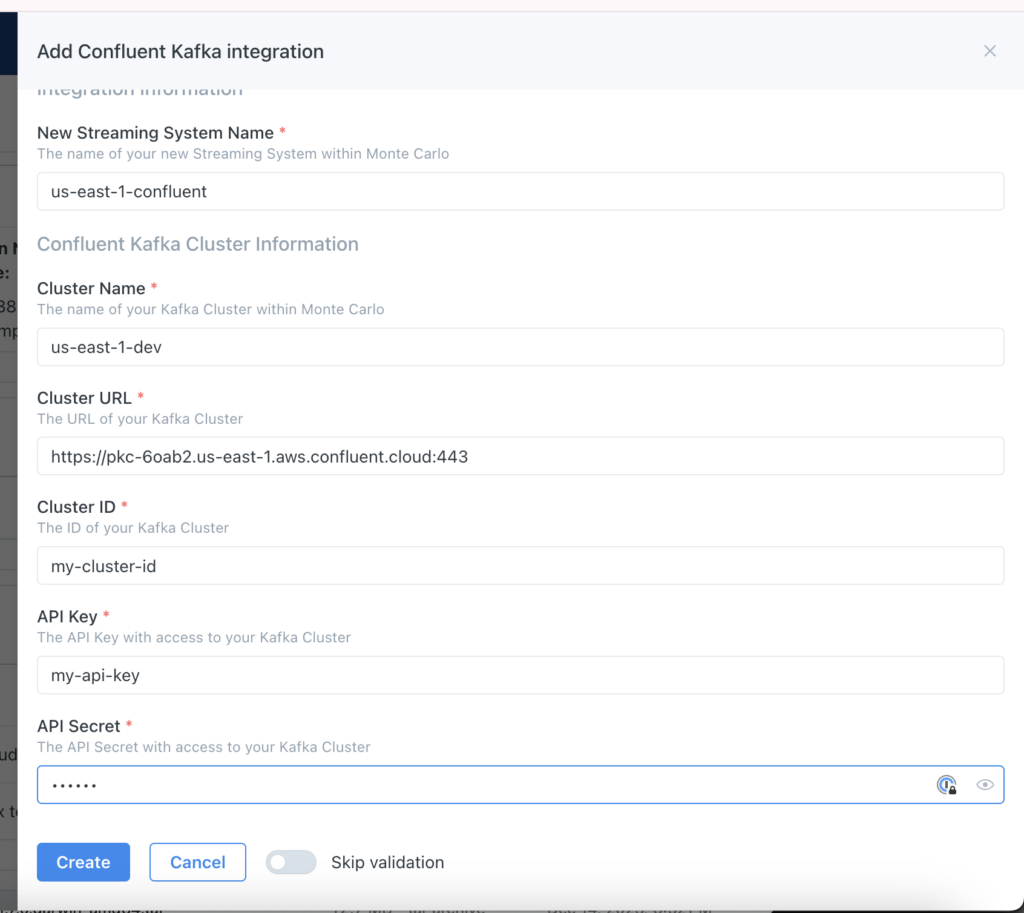
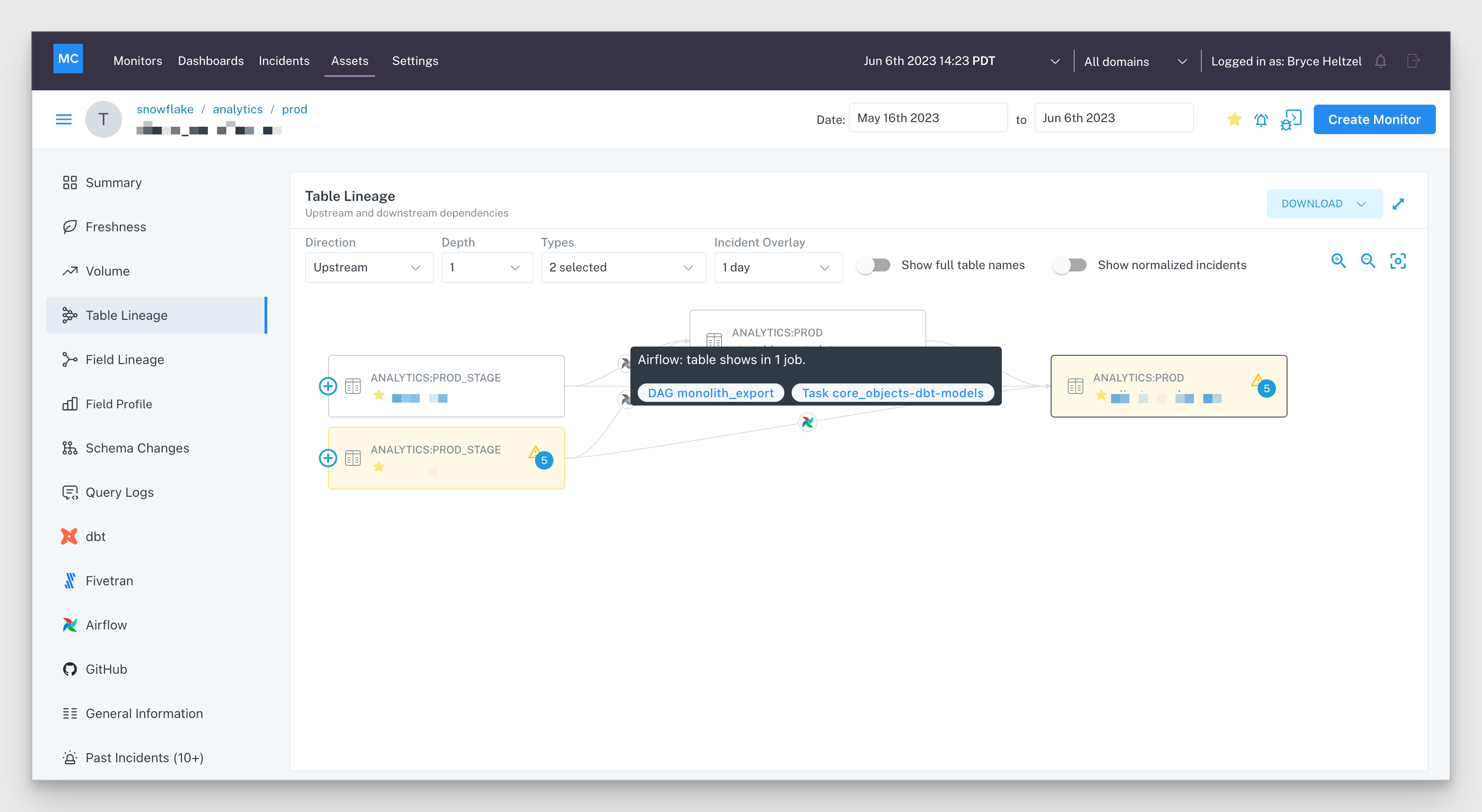
Once connected, lineage is automatically populated and updated including all downstream dashboards. Kafka Topics (streams) are also created within the Assets tab with key metadata, tags, and schema fields surfaced.

Sinks, sources and cross database stitching
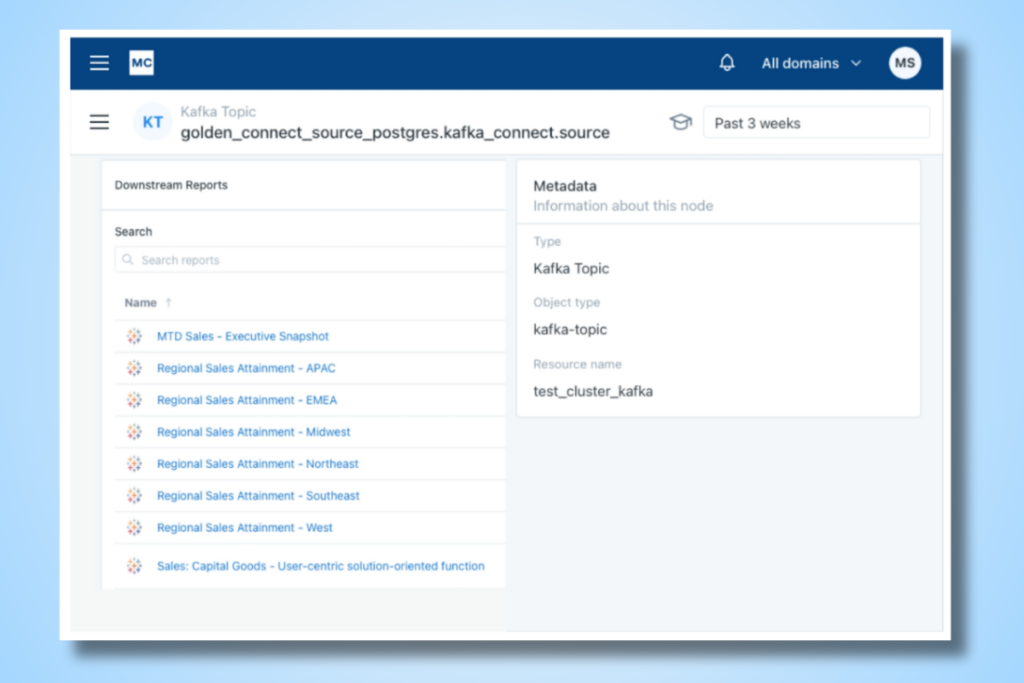
Monte Carlo tracks your Topics and Kafka Connectors to create cross database lineage. This is particularly helpful in illustrating two common data architecture patterns:
- Kafka is upstream of a data warehouse and serving as a “sink” into BigQuery, Snowflake, or Redshift.
- Kafka is serving as a “source” downstream of a transactional or operational database such as Postgres, MySQL, MongoDB, or Debezium CDC.
And of course as the image below illustrates there are pipelines that will involve both patterns! In cases, Monte Carlo will stitch the source transactional table to the target warehouse table through Kafka Topics.

On the roadmap
Monte Carlo continues to lead the way when it comes to end-to-end data observability. That means continuing to support upstream and downstream data assets like Kafka topics and connectors to create a holistic view for data teams to understand their pipelines.
We plan to continue to develop our Kafka support. This includes more lineage functionality as well as automated machine learning monitors for data freshness, volume, schema and quality.
If you are interested in additional sources and monitors please get in touch with our team!
Our promise: we will show you the product.
Read more posts.