Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Now Featuring: Orchestration Lineage
Data pipelines get complex quickly. A pipeline supporting a single critical use case may be ingesting data from dozens of sources and refining it via multiple layers of transformation across hundreds of tables.

Just like with mathematical equations, the order of operations matter. If there is a delay or failure in one part of this intricate web of tasks, then a cascade of data issues is around the corner.
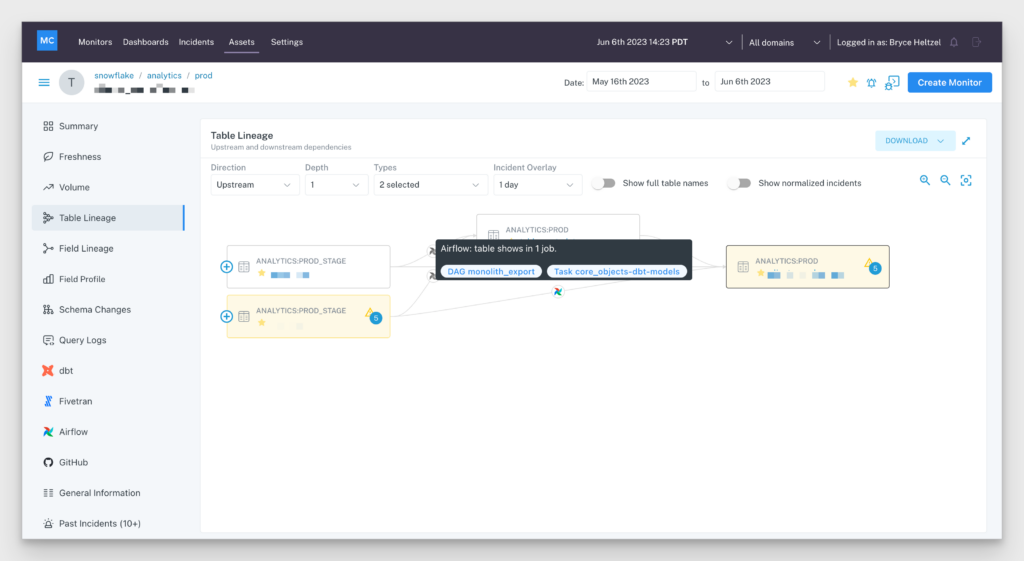
DAGs are the means of orchestrating all of these moving parts, and two of the most popular solutions for creating and executing these DAGs are Apache Airflow and Databricks Workflows.
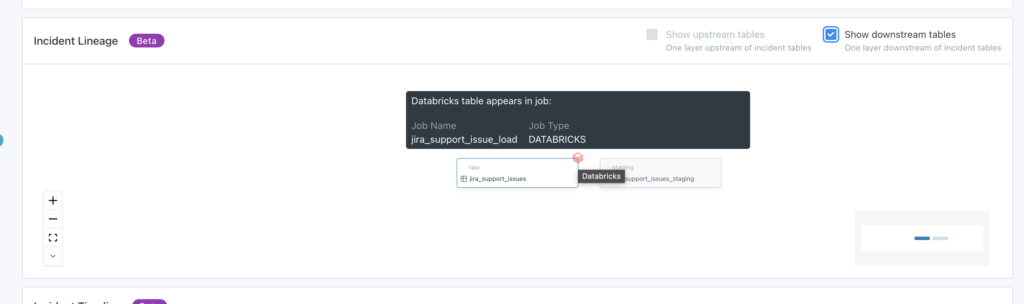
In order to find and fix data incidents quickly, data observability solutions must provide visibility into the behavior of the data, systems, and code.
Orchestration solutions fall into the systems bucket, and Monte Carlo has long surfaced Airflow job failures as incidents along with the associated metadata required to investigate and resolve these issues.

That context for investigating and resolving these system failures is now much richer, greatly accelerating the resolution process.
For example, some of the first questions data engineers want to know following an incident are:
- What DAG or workflow is populating this table?
- What was the result and duration of the recent task runs for this DAG?
- What’s the current status?
The answer is just a click away with the full upstream and downstream lineage and gantt chart just another click from there.
Now the data engineer can restart the DAG or take whatever additional steps may be required to resolve the issue.
How Does It Work?
To connect to Airflow for task observability, users can integrate using Airflow Callbacks to send a webhook back to Monte Carlo upon an event in Airflow (details).
For Airflow lineage, Monte Carlo relies on query tagging to ingest DAGs and tasks related to tables. This means leveraging functions like Snowflake query tags, BigQuery labels, query comments, cluster policies or dbt macros.
The tagged queries executed in Airflow will be later ingested by Monte Carlo which will then enhance lineage information automatically (details).
No additional set up is required for Databricks workflow lineage once you have connected to a Databricks environment leveraging Unity Catalog.
The Data Lineage Roadmap
Long before data lineage found its way into every other modern data solution, it was popularized by Monte Carlo as one of our five core pillars of data observability.
We have continued to advance these capabilities in significant ways to help data teams improve data reliability. We were the first data observability solution with field level lineage, we pioneered Spark data lineage, and now we are leading the way in unifying critical information from across the modern data systems into one cohesive mapping of data flows.
You can expect Monte Carlo to continue making data lineage more robust not only by adding more helpful context from more systems, but also making that information easier to digest with new UI improvements. In the next few weeks expect to see easier bi-directional drag navigation along with the ability to click to expand additional nodes along a specific path.
Want to know more about how data observability and data lineage can help make you deliver more reliable data? Talk to us!
Our promise: we will show you the product.
Read more posts.