 Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage RAG vs Fine Tuning: How to Choose the Right Method

Generative AI has the potential to transform your business and your data engineering team, but only when it’s done right. So how can your data team actually drive value with your LLM or GenAI initiative?
Leading organizations are often deciding between two emerging frameworks that differentiate their AI for business value: RAG vs fine tuning.
What’s the difference between retrieval augmented generation (RAG) vs fine tuning? And when should your organization choose RAG vs fine tuning? Should you use both?
We’ll dive into the fundamentals of RAG vs fine tuning, when each method is best, their benefits, and a few real-world use cases to get you started.
Table of Contents
What is Retrieval-Augmented Generation (RAG)?
Retrieval augmented generation (RAG) is an architecture framework introduced by Meta in 2020 that connects your large language model (LLM) to a curated, dynamic database. This improves the LLM’s outputs by allowing it to access and incorporate up-to-date and reliable information into its responses and reasoning.
RAG development is a complex process, and it doesn’t exist in a vacuum. It can involve prompt engineering, vector databases like Pinecone, embedding vectors and semantic layers, data modeling, data orchestration, and data pipelines – all tailored for RAG.
Here’s how a RAG flow works:
- Query processing: The process begins when a user submits a query to the system. This query is the starting point for the RAG chain’s retrieval mechanism.
- Data retrieval: Based on the query, the RAG system searches the database to find relevant data. This step involves complex algorithms to match the query with the most appropriate and contextually relevant information from the database.
- Integration with the LLM: Once the relevant data is retrieved, it’s combined with the user’s initial query and fed into the LLM.
- Response generation: Using the power of the LLM and the context provided by the retrieved data, the system generates a response that is not only accurate but tailored to the specific context of the query.

So, developing a RAG architecture is a complex undertaking for your data team, and it requires the development of data pipelines to serve the proprietary contextual data that augments the LLM. But when it’s done right, RAG can add an incredible amount of value to AI-powered data products.
What is Fine Tuning?
Fine tuning is an alternate approach to GenAI development that involves training an LLM on a smaller, specialized, labeled dataset and adjusting the model’s parameters and embeddings based on new data.
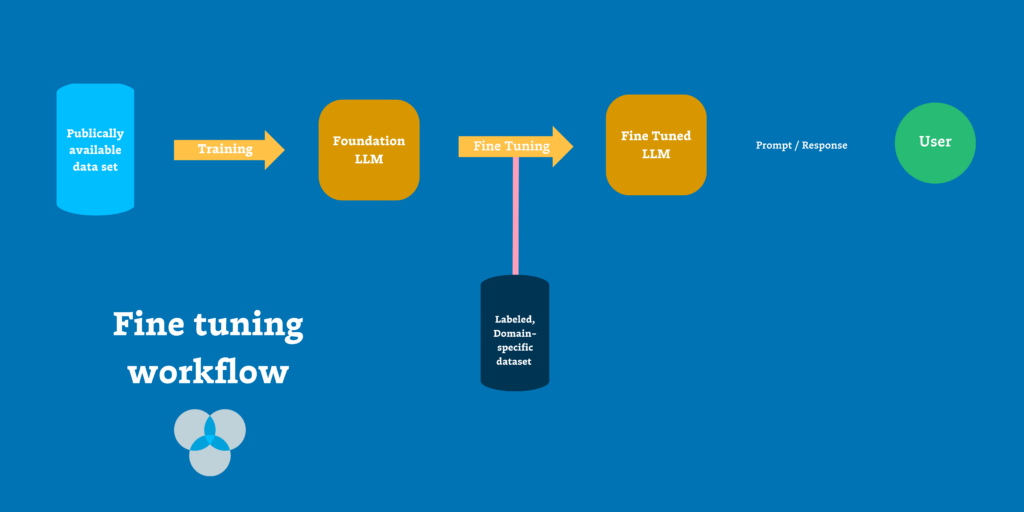
In the context of enterprise-ready AI, the end goal of RAG and fine-tuning are the same: drive greater business value from AI models. But rather than augmenting an existing LLM with access to a proprietary database, fine-tuning goes deeper by tailoring the model itself for a specific domain.
Fine-tuning involves training an LLM on a smaller, specialized, labeled dataset and adjusting the model’s parameters and embeddings based on new data. By aligning the model with the nuances and terminologies of a niche domain, fine-tuning helps the model perform better for specific tasks.
When to Use Retrieval-Augmented Generation (RAG)?
For most enterprise use cases, RAG is a better fit than fine-tuning because it’s more secure, more scalable, and more reliable.
RAG allows for enhanced security and data privacy
With RAG, your proprietary data stays within your secured database environment, allowing for strict access control; compared to fine-tuning, where the data becomes part of the model’s training set and potentially exposing it to broader access without commensurate visibility.
RAG is cost-efficient and scalable
Fine-tuning a large AI model is resource-intensive, requiring significant time and compute power. By leveraging first-party data into responses instead of model parameters, RAG is able to limit resource cost at both the compute level and eliminate the training stage, as well as the human level by avoiding the weeks- or months-long process of crafting and labeling training sets.
RAG delivers trustworthy results
The value of AI rests on its ability to deliver accurate responses. RAG excels in this area by consistently pulling from the latest curated datasets to inform its outputs. And if anything does go wrong, the data team can more easily trace the source of the response to develop a clearer understanding of how the output was formulated—and where the data went bad.
Retrieval-Augmented Generation Use Case
In early 2024, Maxime Beauchemin, creator of Apache Airflow and Superset and the founder & CEO of Preset, told us how his team uses RAG to bring AI-powered capabilities to Preset’s BI tools.
Originally, Max and his team explored using OpenAI’s API to enable AI-powered capabilities, such as customers using plain-language text-to-SQL queries. But given the limits of ChatGPT’s context window, it wasn’t possible to provide the AI with all the necessary information about their datasets — like their tables, naming conventions, column names, and data types. And when they attempted fine-tuning models and custom training, they found the infrastructure wasn’t quite there yet — especially when they also needed to segment for each one of their customers.
“I can’t wait to have infrastructure to be able to custom train or fine-tune with your own private information from your organization, your GitHub, your Wiki, your dbt project, your Airflow DAGs, your database schema,” says Max. “But we’ve talked to a bunch of other founders and people working around this problem, and it became clear to me that custom training and fine tuning is really difficult in this era.”
Given that Max and his team couldn’t take a customer’s entire database, or even just the metadata, and fit it in the context window, “We realized we needed to be really smart about RAG, which is retrieving the right information to generate the right SQL. For now, it’s all about retrieving the right information for the right questions,” he says.
When to Use Fine Tuning?
Depending on the resources available, some organizations may opt for fine tuning as an alternative to drive value from their GenAI initiative.
By aligning the model with the nuances and terminologies of a niche domain, fine-tuning helps the model perform better for specific tasks. It can be effective in domain-specific situations, like responding to detailed prompts in a niche tone or style, i.e. a legal brief or customer support ticket. It is also a great fit for overcoming information bias and other limitations, such as language repetitions or inconsistencies.
Like RAG, fine tuning requires building effective data pipelines that can make proprietary data available to the fine tuning process in the first place.
Fine Tuning Use Cases
Several studies over the past year have shown that fine-tuned models significantly outperform off-the-shelf versions of GPT-3 and other publically available models.
It has been established that for many use cases, a fine-tuned small model can outperform a large general purpose model – making fine tuning a plausible path for cost efficiency in certain cases.
For example, Snorkel AI created a data-centric foundation model to bridge the gaps between their foundation models and enterprise AI. Their Snorkel Flow capabilities include fine-tuning, along with a prompt builder and “warm start,” to give data science and machine learning teams the tools they need to effectively put foundation models to use for performance critical enterprise use cases.
This resulted in the Snorkel Flow and Data-Centric Foundation Model Development achieving the same quality as a fine-tuned GPT-3 model with a deployment model that was 1,400x smaller, required <1% as many ground truth (GT) labels, and costs 0.1% as much to run in production.
How to Choose Between RAG vs Fine Tuning
You should choose between RAG vs fine tuning based on your use case and available resources. While RAG is the preferred option for most use cases, that doesn’t mean that RAG and fine-tuning are mutually exclusive either. While fine tuning isn’t always the most practical solution – training an LLM requires a lot of time, compute, and labeling – RAG is also complex.
If you have the resources, there are certainly benefits to leveraging both—training your model to pull the most relevant data from the most targeted contextual dataset. Consider your specific needs first, and make a decision that will drive the most value for your stakeholders.
Regardless of which one you use, AI application development is going to require data pipelines that feed these models with company data through some data store. And in order for your AI to work, you need to focus on the quality and reliability of the data pipelines on which your models depend.
The only way for RAG or fine tuning to work is if you can trust the data. To achieve this, teams need to leverage data observability – a scalable, automated solution to ensure reliability of data, identify root cause, and resolve issues quickly before they impact the LLMs they service.
To learn more about how data observability can ensure the reliability of your GenAI pipelines, chat with our team here.
Our promise: we will show you the product.
Frequently Asked Questions
Is rag better than fine-tuning?
RAG is generally better for most enterprise use cases because it is more secure, scalable, and cost-efficient. It allows for enhanced security and data privacy, reduces compute resource costs, and provides trustworthy results by pulling from the latest curated datasets.
What is the difference between rag and fine-tuning vs prompt engineering?
RAG involves augmenting an LLM with access to a dynamic, curated database to improve outputs, while fine-tuning involves training an LLM on a smaller, specialized dataset to adjust its parameters for specific tasks. Prompt engineering involves crafting queries to elicit better responses from the model without altering the model or its data sources.
Can rag and fine-tuning be used together?
Yes, RAG and fine-tuning can be used together. While fine-tuning trains the model to better understand specific tasks, RAG ensures the model has access to the most relevant and up-to-date data. Combining both methods can enhance the performance and reliability of the model.
Is rag cheaper than fine-tuning?
RAG is generally more cost-efficient than fine-tuning because it limits resource costs by leveraging existing data and eliminating the need for extensive training stages. Fine-tuning requires significant time and compute power for training the model with new data, making it more resource-intensive.
What is the difference between rag and model fine-tuning?
RAG involves augmenting an LLM with access to a curated database, allowing it to retrieve relevant information dynamically for generating responses. Fine-tuning, on the other hand, involves adjusting the model’s parameters by training it on a specific, labeled dataset to improve its performance on specific tasks. Fine-tuning modifies the model itself, while RAG enhances the data the model can access.
When to use rag vs fine-tuning?
Use RAG when you need a scalable, secure, and cost-efficient solution for integrating up-to-date and reliable information into LLM outputs. Use fine-tuning when you need the model to perform better on specific tasks by training it on a specialized dataset.
What is the difference between rag, fine-tuning, and embedding?
RAG (Retrieval-Augmented Generation) connects an LLM to a curated database to improve outputs by integrating reliable information. Fine-tuning adjusts the model’s parameters by training it on a specialized dataset to improve performance on specific tasks. Embedding involves representing data in a lower-dimensional space to capture semantic relationships, used to enhance the model’s understanding of context and meaning.
Read more posts.





