 Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Redefining Hosting: A Customer-Driven Journey to Better Deployments


Prateek Chawla
Prateek Chawla is a Founding Principal Engineer and Technical Lead at Monte Carlo.
No two companies are ever quite the same.
Some teams have more security needs. Other teams are concerned about costs or administration requirements.
So, when it comes to how organizations choose to deploy new software, there’s never a one-size-fits-all approach. That’s particularly true when you’re working with a customer resource as critical as data.
At Monte Carlo, our goal is always to make our customers as happy as possible. That means being flexible to how our customers want to use and deploy our product. But when you’re scaling to become the #1 Data Observability Platform, you’re likely to get more requests than your existing architecture can accommodate.
To continue delivering the best experience for our customers, we decided to take a new approach to software deployments that would enable our data observability platform to be as flexible as our customers required.
And that journey led us to look at hosting in a whole new way.
Read on to find out about our latest “agent deployments”, how we’re optimizing for customer experience, and what that means for Monte Carlo today.
Table of Contents
The history of the Monte Carlo data collector
When Monte Carlo created the data observability category way back in 2019, our “data collector” was at the core of our deployments.
It consisted of three core components:
- Data connection: the connectivity to resources like Redshift, Snowflake, BigQuery, Databricks and many more (e.g., via IP allowlisting, peering, private link, etc.)
- Data storage: any record-level or troubleshooting data (e.g., for data sampling)
- Data processing: the extraction and transformation collection engine (e.g., any business logic) (Note: data processing at Monte Carlo does not include sampling data)
In its most basic terms, the data collector was the primary lens through which Monte Carlo observed or interfaced with customer data pipelines. It was used to “collect” the metadata, query logs and other record level information that would be used to monitor for anomalies, map data lineage, and help our customers root cause their quality issues at the data, system, and code levels. (As an aside, customers could also use or supplement certain integrations with our robust developer toolkit. You can learn more about that here!)
Depending on a customer’s needs, they could deploy the Data Collector in one of two ways:
- Fully-cloud: this enabled customers to access the platform directly while Monte Carlo managed the infrastructure and any necessary maintenance
- Hybrid: alternatively, this solution offered customers a template to deploy and manage the data collector in their own AWS environment with CloudFormation
(TL;DR this approach allowed us to marry on-prem security with the deployability of a SaaS product to deliver quick time-to-value for our early customers. You can read more about that early innovation here.)
No matter which way our customers deployed, the Data Collector functioned as the bedrock of their Monte Carlo experience. And for a long time, that was the right solution.
But as Monte Carlo continued to scale, AWS wasn’t the only game in town. With over 500 Data Collector deployments and limited platform options for hybrid hosting, managing an exponential number of individual Data Collectors became our biggest bottleneck.
The challenge: expanding beyond AWS
For many of our customers, it’s important to be able to manage connectivity, data storage, and security within their own cloud.
The early Data Collector hybrid deployment was limited to AWS, but as we scaled, we wanted to make this option available for other platforms like Google Cloud, Azure, and via other deployment tools like Terraform. As we began considering the prospect of managing these new hybrid and cloud deployment architectures on a one-to-one basis alongside our existing 500 deployments, it was clear that we wouldn’t be able to scale and support our customers effectively.
We needed to evolve how we handled deployments if we were going to support these additional cloud platforms.
But as any engineer can tell you, supporting multi-cloud deployment is no easy ask. We couldn’t just flip on a switch. We needed to take into account maintainability, customer experience, and our own developer velocity if we wanted to design something that would be commercially viable.
And those constraints led us to a breakthrough.
Asking the right questions
It’s amazing what can happen when you’re willing to look at an old problem in a new way.
When we first began our multi-cloud journey, we were looking for a scalable way to deploy more Data Collectors. The question was simply, “How do we get more Data Collectors on more cloud platforms efficiently?”
But, the more we pondered the question, the more we saw the problem for what it was.
The question we needed to ask wasn’t “How do we deploy more Data Collectors?” The question we really needed to ask was, “Why do we need to deploy more Data Collectors at all?”
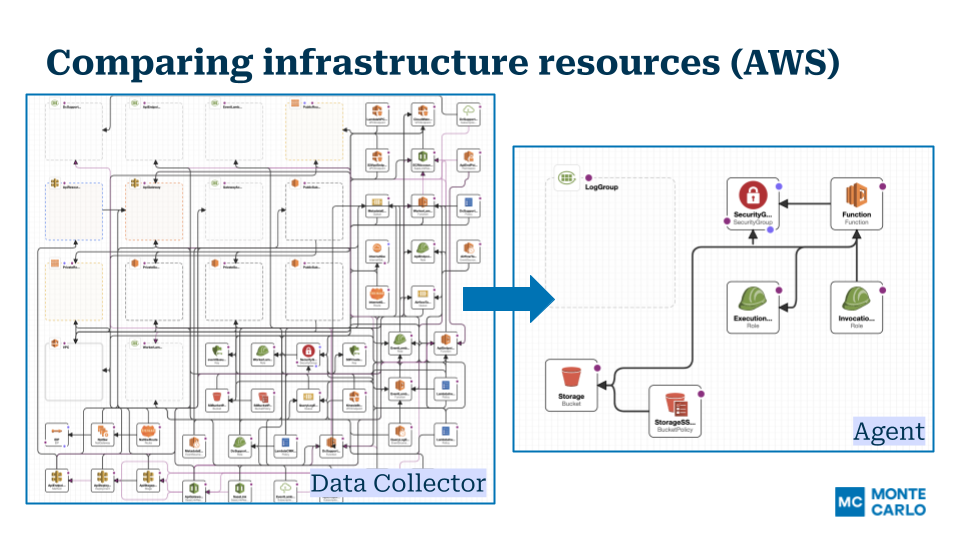
The primary limiting principle in the multi-cloud equation had very little to do with the uniqueness of the platforms and much more to do with the complexity of the code being deployed. If we could find a way to reduce the complexity of the deployment, we could remove the primary bottleneck as well.
While the Data Collector consisted of three components—storage, connectivity, and processing—that didn’t mean each of these components needed to be deployed in the same way. In fact, it was the collection engine (extraction, transformations, etc) that actually made up the bulk of the Data Collector’s complexity (~90%). So, if someone were to decouple processing from the connection and storage, the deployment would actually become a fairly lightweight problem to solve and manage long-term.
With this trifurcated approach to deployment in mind, we decided to break apart the Data Collector into three separate components that would abstract processing away from the customer’s data cloud without taking their record-level data or connectivity control with it.
And with that, the Agent and Data Store were born.
The solution: Agents and Data Stores
So, what are Agents and Data Stores and how do they solve for fast, flexible, multi-cloud deployments?
When we decided to split the hybrid deployment into its three critical components, we developed separate deployment resources for each step of the connection.
For storage, we created the Data Store. In basic terms, the Data Store is a zero-code, record-level data storage tool that sits within the customer’s cloud environment. Unlike our previous hybrid deployments which would deploy the entire Data Collector in a customer environment, the Data Store simply creates an anchor point for Monte Carlo to collate data and connect to without the need for complex infrastructure, leading to both simpler and faster deployments.
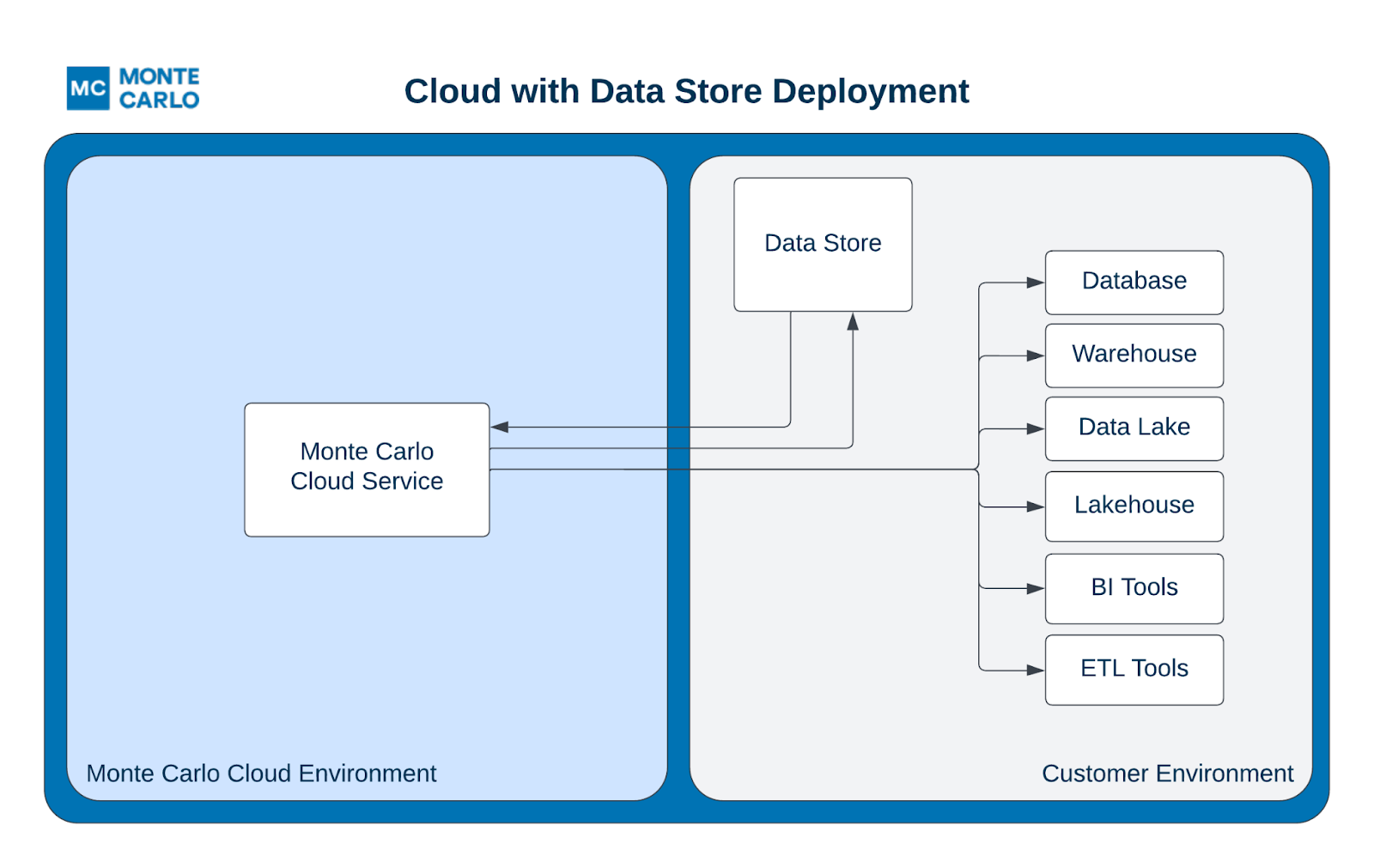
For customers who want to manage connectivity as well, we created the Agent—a light-weight, hyper-flexible, and publicly available connectivity tool that acts as an intermediary between a customer’s resources and the Monte Carlo Platform, allowing customers to better audit, validate, manage, monitor, and review requests, all the while minimizing infrastructure and maintenance.
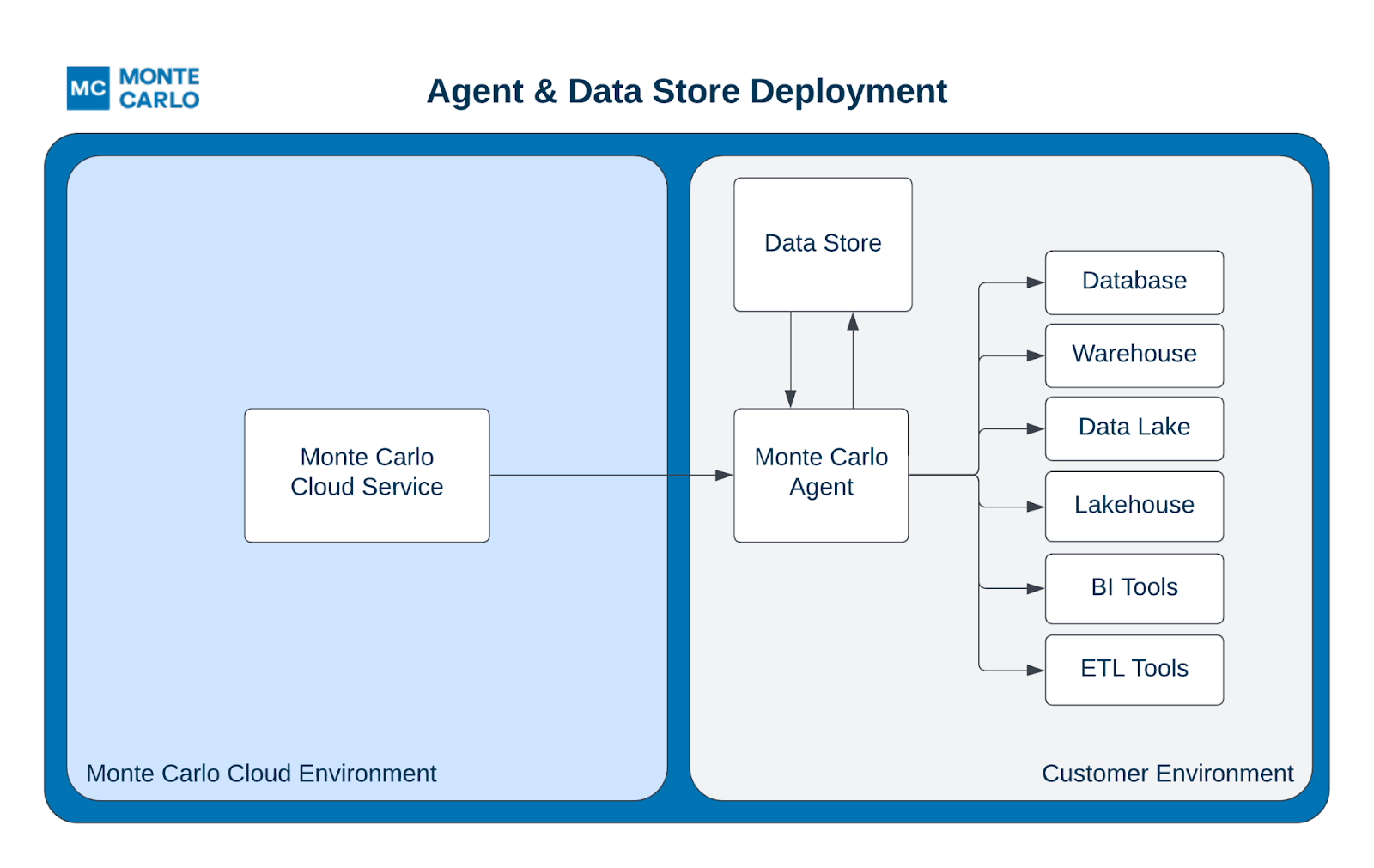
And finally, the bulk of the previous Data Collector was broken off into the Collection Engine. Whereas previous hybrid deployments would include collection and processing within the Data Collector itself, our new deployment model maintains all that processing bulk within Monte Carlo.
Using either a direct connection to the Data Store or the Agent + Data Store acting as an intermediary, Monte Carlo is able to manage the collection and processing of a hybrid customer’s observability internally without removing the record-level data itself from the safety of the Data Store. Consequently, this enables faster onboarding for new customer teams while simultaneously minimizing management, reducing cost and complexity, and serving as the base for future multi-platform performance and observability extensions.
By separating these pieces of the Data Collector, customers now have the ability to deploy in not just one or two, but three different ways:
- Full “SaaS model”: customer leverages the collection engine to talk directly to resources via options like IP allowlisting and Private Link. No code—just connect and go.
- Direct data storage deployment: customer deploys and connects to their own Data Store. Also no code!
- Hybrid deployment with the Agent: customers deploy an Agent with bundled Data Store together to act as the mediator communicating with the collection engine. A lot less code! Still connect and go!
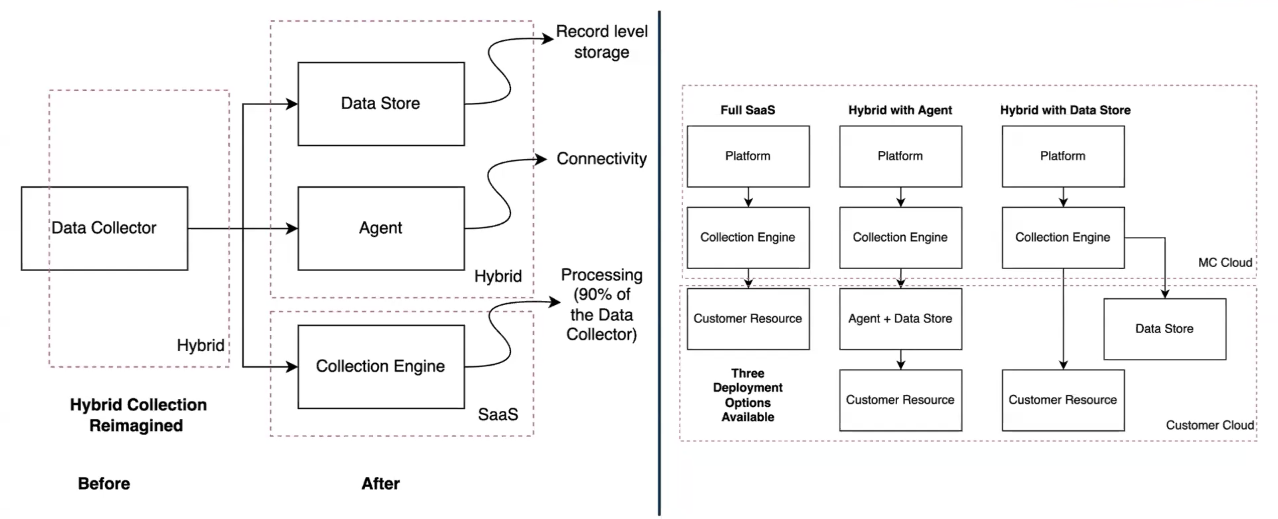
So, what do these options change? Instead of deploying a massive Data Collector that can be difficult to update or maintain, we can enable customers to manage their data and connectivity all in their own environment—while extending that opportunity to a near infinite number of cloud platforms.
Customers get more options in a lighter-weight and more stable deployment structure. And Monte Carlo is able to manage more deployments faster to make more customers as happy as possible.
The path forward: Continuous improvement
The Data Collector is now significantly easier to deploy and leverage in cloud environments across AWS, GCP, Azure, and with new deployment options like Terraform.
As we continue to listen to our customers and iterate on data collection, we’ll work to ensure onboarding and deploying is as simple and clear as possible.
Want to learn more? All our resources and docs are publically available! Check them out here:
- Agent code: https://hub.docker.com/r/montecarlodata/agent
- Agent API reference: https://apollodocs.getmontecarlo.com/
- IaC resources: https://github.com/monte-carlo-data/mcd-iac-resources
- AWS Terraform module: https://registry.terraform.io/modules/monte-carlo-data/mcd-agent/aws/latest
- GCP Terraform module: https://registry.terraform.io/modules/monte-carlo-data/mcd-agent/google/latest
- Azure Terraform module: https://registry.terraform.io/modules/monte-carlo-data/mcd-agent/azurerm/latest
Have other thoughts about the Data Collector or want to share your experiences? Click the link to let us know!
Our promise: we will show you the product.
Read more posts.





