Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Scaling Data Quality Management for Business Rules & Baseline Rules


Tim Osborn
Tim is a content creator at Monte Carlo who writes about data quality, technology, and snacks—occasionally in that order.
Life is full of necessary inconveniences.
Cleaning the gutters. Visiting the dentist. Writing data quality checks.
But when inconveniences stop being a speed bump and start becoming a traffic jam, it’s time to make a change.
As a data analyst, you’re responsible for the performance and veracity of your domain-specific data products. Whether that’s an executive dashboard, inventory tracking, or critical financial metrics, your work directly impacts the performance of broader domain-specific teams—and (ideally) your organization writ large. No pressure.
Data quality management isn’t the fulcrum of your role as an analyst—but your work won’t succeed without it. For the analyst, that typically means two things. Writing data quality checks. And then writing more data quality checks.
But every moment you spend managing data quality is another moment you won’t spend driving value for your stakeholders—and proving out the necessity of your work in the process.
In this article we’ll discuss the different types of data quality checks (including business rules and baseline rules) you need to validate the reliability of your data assets, when you need them, and how to scale your data quality management practice more effectively (in less time) while clawing back valuable time in the process.
Let’s dive in.
What are Business Rules and Baseline Rules?
If you think about all the rules you’ve written to validate data quality over the years, you can generally group those rules into one of two buckets:
- Baseline rules: general checks for basic data quality dimensions
- Business rules: specialized checks for domain-specific requirements
When it comes to data quality management, it’s never just one or the other. You need both business rules and baseline rules to deliver complete coverage. The challenge is knowing when and how much.
So, now that we’ve established what they are, let’s take a close look at how you can manage them more effectively.
Baseline rules
Data quality checks designed to monitor for general data quality dimensions are known as baseline rules. These tests are the same—or very similar—across fields and tables, and are often relatively easy to copy and deploy across tables. You want your ID fields to be unique, your currency ratio to never be negative, your order amounts to never be NULL—that kind of thing.
These rules are often defined by a central governance team and generally conform to the 6 dimensions of data quality, including:
- Accuracy—does the data reflect reality?
- Completeness—did we get the amount of data we expected?
- Timeliness—did the data arrive when we expected it?
- Uniqueness—is the data free from duplicates?
- Integrity—has the data been altered since ingestion?
- Validity—does the data meet certain criteria, like common acceptable formats?
On a small scale, you can likely handle writing and managing your baseline rules by hand. But as your data scales into the enterprise and beyond, your manual approach to data quality checks will quickly begin to show its cracks—and your baseline rules will be the first piece to shatter.
How to manage baseline rules at scale
I’ll come right out and say it—there are some data quality checks that you shouldn’t be writing by hand—and baseline rules are at the top of the list. It’s not simply that it isn’t scalable—although it isn’t—but it’s also not effective either.
Even if you could write manual checks to cover every single table and column in your environment, you couldn’t possibly anticipate every way that data can break. And if you can’t anticipate it, you won’t write a data quality check to monitor for it.
First you struggle with tracking or version control. Then you start to wonder if you have the right coverage across tables. Eventually you’re layering complexity on complexity trying to get the same level of coverage at 200 tables that you had with two.
Here’s how to handle it:
Automate freshness, volume, and schema checks
Applying broad rules to cover critical data quality dimensions is tedious at the best of times—at scale, it’s a full-time job.
Leveraging automation is critical to managing baseline rules at scale.
Repetitive manual tasks are the best candidates for automation because they can be programmatically deployed and have the potential to auto-scale over time.
Solutions like data observability provide baseline monitors for thing like freshness, volume, and schema right out of the box.
By automating baseline rules for critical data quality dimensions, data teams can recover hours of time that would otherwise be lost to routine monitor creation and free up analysts to deliver even more value for stakeholders in the process.
Deploy AI-powered anomaly detection for uniqueness, validity, and accuracy
Just because a baseline monitor is general, doesn’t mean it’s simple to define. Manual accuracy rules require profiling each numeric column individually to define all of the accepted ranges for various tables. Uniqueness might be different based on the specific column or table being monitored.
With AI-powered monitors and no-code validation monitors—like those available from Monte Carlo—data teams can quickly deploy a handful of monitors across all of their critical tables at once rather than writing and deploying hundreds of separate rules over a period of days or weeks.
Benefits of leveraging true AI-powered monitoring and recommendation tools:
- Thresholds are automatically defined based on historical data
- Coverage can scale all the way upstream of your data product to validate pipelines from ingestion to stakeholder consumption
These types of AI-powered monitors are truly “set it and forget it” and free data analysts up to deliver on their primary mandates and other data governance issues where their domain-expertise will be more critical.
Business Rules
Business rules are really where the rubber meets the road for data analysts. In contrast to the broad applicability of baseline rules, business rules can’t be easily deployed across multiple tables.
Business rules are checks that are specific to either a business or domain or that have been written to catch known issues within a particular pipeline. For example, an airline might want to validate that a first class ticket always costs more than an economy ticket. Or maybe a discount percentage should never exceed 10%.
These types of data quality rules generally require a deep knowledge of the business and specialized domain expertise to be managed effectively (if you’re writing business rules without an understanding of the business, that’s another issue entirely).
For some organizations, this process can be quite cumbersome, with business process owners defining the requirement and then handing it off to another member of the team to express it in SQL.
And much like baseline rules, business rules are extremely sensitive to scale.
Volume expands, systems evolve, use-cases grow; and data analysts wind up on the hook for an endless stream of data quality rules – or worse yet, waiting on the hook for someone else to prioritize them.
How to manage business rules at scale
While undoubtedly critical to the success of any data product, this tailored approach to monitoring makes business rules difficult to scale programmatically. And when these alerts do fire, there’s often no smoking gun to resolve them.
But just because you can’t automatically apply any random business monitor to your critical tables doesn’t mean you can’t automate both the development and the maintenance of that monitor.
Here’s how to scale business rules quickly across tables:
Get closer to the business
Before you can deploy effective and scalable business rules, you need to understand what matters to your business.
Even with the most AI-enabled monitors on the market at your disposal and a massive engineering team at the ready, you still won’t be able to effectively monitor and resolve every data quality issue on every table all the time. Not only would it be prohibitively expensive for nearly every enterprise data team in practice today, but it also isn’t necessary.
Like most things in data, prioritizing data quality coverage means optimizing for impact, not volume. That includes identifying gaps for the tables that see the most use—and deprecating the tables that don’t.
So, step one is to get closer to the business—to understand which of your tables actually need your attention based on where and how they’re used and which tables will be fine with basic automated coverage for critical dimensions.
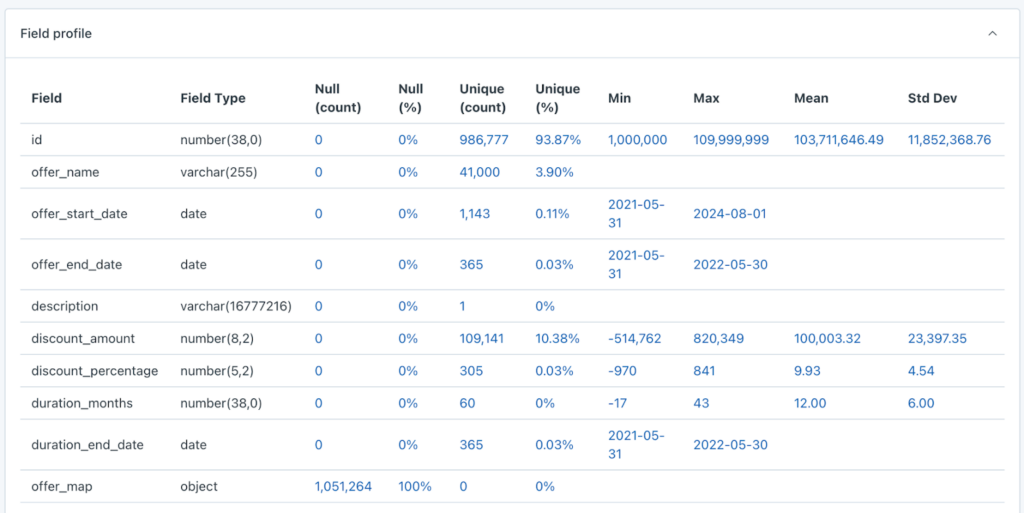
Get to know your data with no-code data profiling
Profiling your data is critical to deploying the right monitors for critical tables. Automating data profiling can help your team understand at a glance what’s in each table—and provide the right context to define monitor thresholds when the time comes.
Democratize coverage with no-code validation rules
Once you know what matters to your stakeholders—and what’s in your data—you can start deploying scalable monitors that provide the best possible coverage for your critical tables to deliver the most value and at the lowest cost. This often starts with the creation of validation monitors to ensure that data meets some predefined standard.
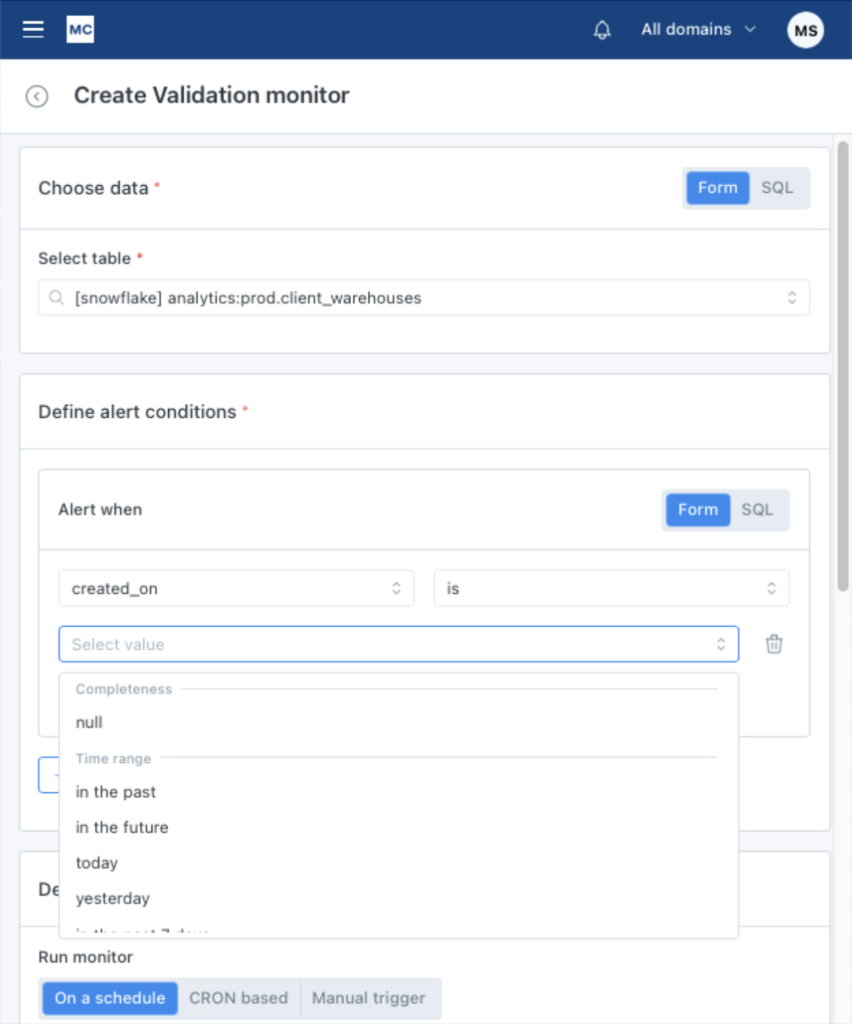
Leveraging a data quality solution that offers validation monitors in a point-and-click interface for common field types (numeric, string patterns, etc.) is one of the easiest ways to democratize validation and verify that your data meets acceptable standards.
In this instance, a monitor could be created using a simple form to set standards based on common validation checks. In the case of Monte Carlo, once you’ve selected your table, field, and operator, relevant metrics will automatically appear in the drop down menu to select.
Go further with AI-powered rule recommendations
You can’t predict all the ways data can break. And even if you could, you still wouldn’t be able to write enough data quality rules to cover them.
AI-powered monitors and no-code tooling make it easier to scale your coverage across tables by simplifying creation, automating thresholds, and programmatically maintaining monitors over time—tasks that would normally mean hours of an analyst’s time.
With some data observability tools, you can take that one step further by leveraging historical patterns to automate the identification of monitors as well through AI-powered monitor recommendations. This can be especially helpful if you’re unfamiliar with the data feeding your products and insights, and need support determining if you have enough or even the right coverage for a particular table or asset.
Built on top of our own no-code data profiling tool, Monitor Recommendations is a native feature that leverages your data’s profile to suggest deep one-click data quality monitors to deploy across critical data products.
For example, maybe the values in a particular column match typical email formatting—a data observability tool could recommend a Validation Monitor to alert when new values arrive that break format for an email address.
Or, perhaps a column consists of mostly unique values. That platform might recommend a monitor that tracks anomalous changes to the uniqueness rate and then programmatically determine the best threshold to deploy across that field.
Data Observability: An Analyst’s Secret Weapon
Scaling baseline rules, defining business rules, measuring coverage over time—when it comes to delivering reliable insights to your stakeholders, data quality is a full-time job and then some.
In the same way that your data products can’t succeed without high quality data, your data quality practice won’t succeed at scale without a modern data quality platform that can streamline and synthesize the full breadth of data quality tasks into a single automated solution.
Data observability provides comprehensive end-to-end coverage that unifies processes and offers a single pane of glass that democratizes data quality for the entire data team.
With a data observability platform, data teams are empowered to detect data quality issues faster, resolve them sooner, and scale their data quality coverage with full visibility into the health of their data and pipelines from ingestion to consumption.
From auto-scaling coverage for key data quality dimensions to AI-enabled metric monitors and instant data profiling, Monte Carlo is a data observability solution designed for data analysts, data engineers, and everyone in between.
Curious how data observability can help you spend less time managing data quality and more time driving insights? Let us know in the form below!
Our promise: we will show you the product.
Read more posts.



![[O’Reilly Book] Chapter 1: Why Data Quality Deserves Attention Now](https://www.montecarlodata.com/wp-content/uploads/2023/08/Data-Quality-Book-Cover-2000-×-1860-px-1.png)