Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Why We Built Our Feature Store in Snowflake’s Snowpark (And Moved Away From SQL)

Ryan Kearns
Ryan is a data scientist at Monte Carlo.
Every data science team has that moment where it realizes it has outgrown its initial architecture. That moment came quickly for our team and our SQL-based feature store.
Within a few years our organization had scaled from supporting dozens to hundreds of clients, each of whom seemed to require different feature requests for more advanced use cases. Our codebase and data science team were growing rapidly in parallel as well.
Realizing our tech debt bill had come due, we decided to seize the opportunity to create a more robust feature store with Python in Snowpark. Here’s how and why we did it.
Table of Contents
Why ML features are important to Monte Carlo
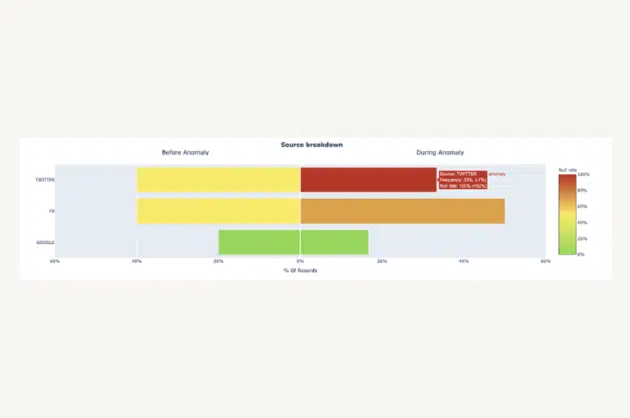
Monte Carlo’s data observability platform leverages a variety of machine learning models to infer if the behavior of the user’s data is within an expected range or anomalous. Examples include: when the data arrived, how many rows were loaded, rate of NULL values, and more signals of unreliable data.
The types of anomalies we detect are strong indications there is a broken data pipeline or other data quality issue that needs to be resolved (we help with that part too, but that’s beside the point).
To do this accurately, our ML models, like all ML models, need to understand what attributes or characteristics of the data’s behavior are important and what weight to give those attributes.
In data science we call these attributes “features,” which are essentially what the rest of the data world calls a key metric.

The machine learning algorithm that determines how much weight or significance to assign to each feature is often romanticized as the secret sauce, but feature selection, engineering, and quality control is often just as, if not more, important to a successful deployment.
Why we originally built features with SQL
Feature engineering and construction isn’t much different than other modern data pipeline architectures. You start with raw data from a source, combine it with other data, and then transform it into the desired state for your machine learning model to consume.
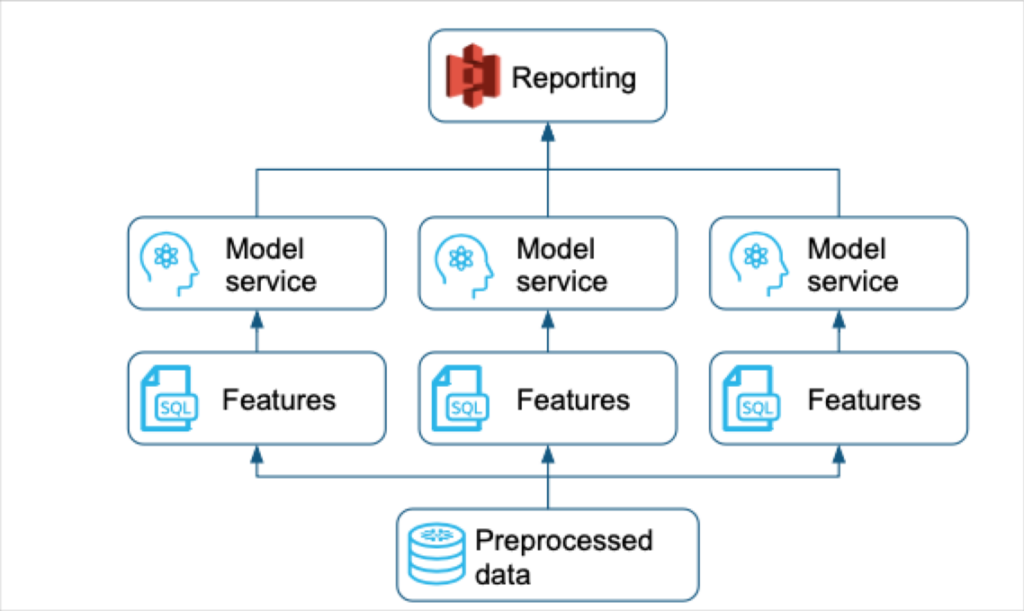
That’s why it isn’t hard to see why some organizations, including Monte Carlo when we first launched, would choose to develop their features primarily using SQL. It’s the predominant data engineering language and has several other advantages that a startup data science team would find attractive including:
- It is the most cost effective way to write code to scale to multiple customers easily. It computes aggregations and batch transactions much faster than Python.
- A query engine environment is far simpler and more reproducible than a Python environment, as it avoids theavoidsthe latter’s package and dependency management nightmares.
- It doesn’t always make sense to build sophisticated models based on a limited number of samples as you get started. In these cases, it can be helpful to blend these models with more rules and expert knowledge, which is easily expressed with SQL.
This was a measure in minutes approach that created the data observability category and drove significant value for our customers. However, it’s virtually inevitable that as your user base, training data, and models grow in volume, complexity, and variety, your feature SQL code will not be able to scale alongside.
The challenges of SQL for generating features at scale
As a query language, SQL has limitations for machine learning applications and feature generation. It is not designed for prediction or model fitting, but to understand business logic. This precludes more advanced algorithmic functionality. It also doesn’t contain all (or really any) of the libraries that enrich other languages.
But perhaps the most problematic issue with SQL generated features is the code kludge that results. It is cumbersome (a query language, not an object-oriented one) and requires much more code to execute many of the simple statistical models that form the foundation of machine learning such as linear regression.
SQL is just not as modular as other modern programming languages. ML teams can soon end up with queries hundreds or thousands of lines long that are difficult to debug, set breakpoints, decompose, or document. This tech debt creates inefficiencies and makes it hard to work with other’s code.
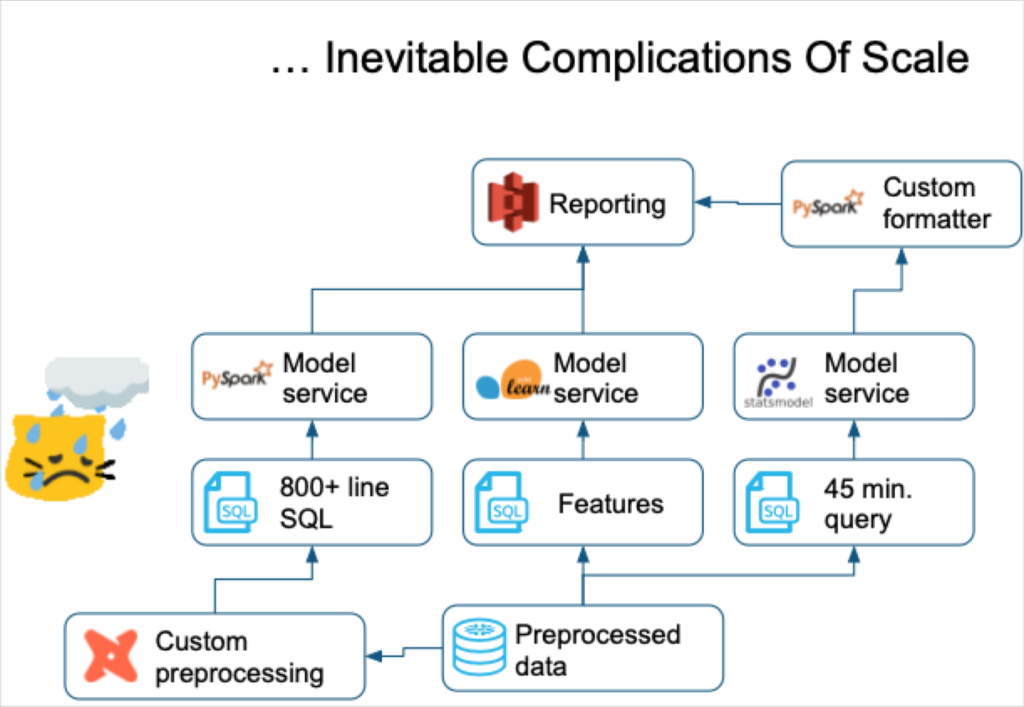
This is compounded when your organization moves from a handful of “design partner” customers to hundreds of customers, some of which have highly specialized use cases. More nuanced anomaly detection techniques were required as well as a more robust feature infrastructure to enable some model tuning for customer types. Essentially, we needed to incorporate (develop, train on, deploy, test) a much higher volume of feature requests, some of which were contradictory.
This is likely a common story for many growing data science teams. Our challenge was a universal one as well: it is easy to put off paying your tech debt. It will almost never be the most value generating task in the short-term.
However, a growing customer base and data science team made it the right time for us to create a more robust feature store/layer by leveraging Python and Snowpark.
Snowpark vs PySpark for feature generation
One of the key decision points was whether we should use Snowpark or PySpark to generate our machine learning features. We experimented with both and relatively quickly determined Snowpark was the right path for us.
One reason was the ease of provisioning Snowflake compute. We also wouldn’t need to move our data to a different storage format. We could bring our scikit-learn and statsmodels under the Snowpark umbrella as well. This would increase code reliability and decrease silos.
We also found quick and manageable ways to build in-house key feature store functionality–things like feature definitions, storage, registry, inference service, training service, model definition– atop of Snowpark.
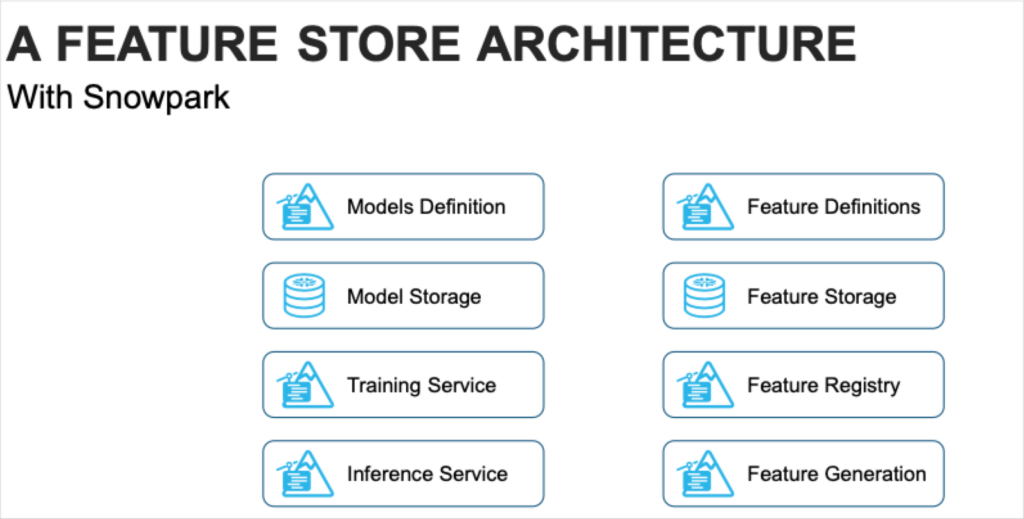
Consolidating our pre-processing and feature layers in one environment would also optimize I/O costs while requiring the fewest development hours to move from current to future implementation. Additionally, some consideration was given to the ease of maintaining a consolidated environment versus an infrastructure requiring Spark clusters to be managed.
Our feature store architecture and migration process
Not only did we decide to migrate to Snowpark, we decided to develop a more robust and sophisticated feature layer as part of the initiative.
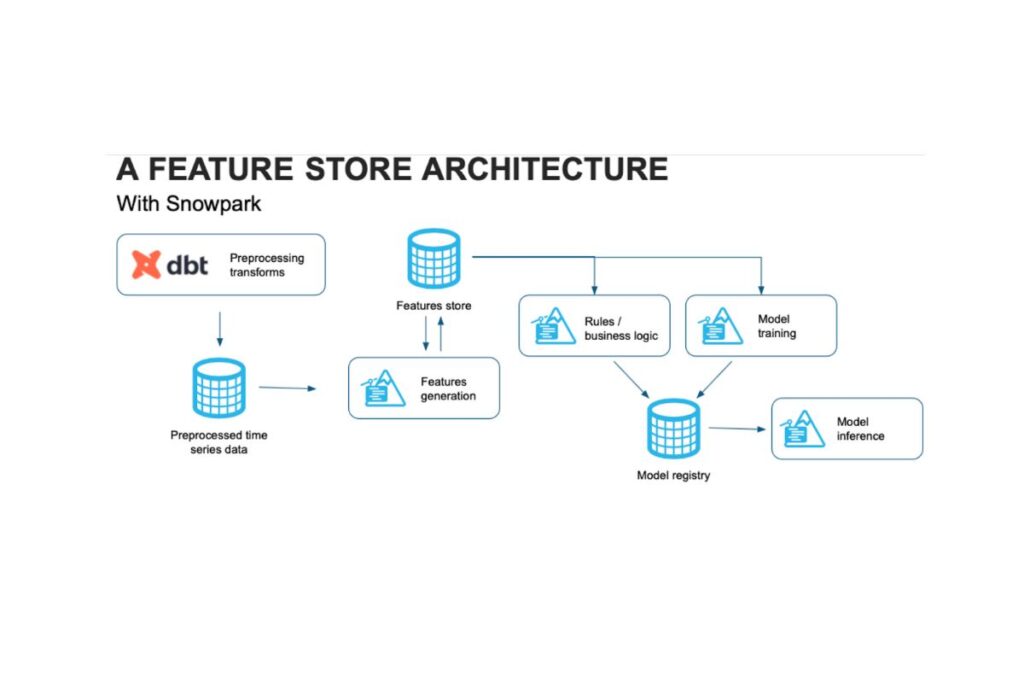
Moving to an architecture with a communal feature registry decoupled these features from our ML models which enabled:
- Increased feature reuse across models. It consolidated similar implementations to make code easier to manage, and faster to integrate.
- The reduction of compute redundancy.
- Expanded test-driven development for model deployment. An improved ability to isolate and test the effects of changing individual features, where previously this often involved running a simulation of the system end-to-end.
- The ability to use a data observability platform (Monte Carlo) to validate and ensure quality and referential integrity across the feature layer.
However, the migration and refactoring process from SQL to Python was not as easy as we had originally anticipated for two reasons.
The first reason was one of the primary reasons we were moving from SQL in the first place: code blocks were lengthy, and at times, difficult to understand. The second reason was we were asked to move as quickly as possible–Monte Carlo is an organization that prides itself on speed of execution.
When you combine these two factors the result is a few mistaken assumptions and some breaking changes. It was during this time I went from Monte Carlo dog food to power user. Data observability is an enabler, and frankly a safety net, when data science teams are pushed to move quickly. At this point, we started configuring and leveraging many of the more advanced features within our data observability platform so we could quickly define and enforce the invariants and expectations about our data.
When everything was being constantly refactored and multiple members of our team were working in parallel, Monte Carlo data quality checks helped us catch potential issues in development environments before they hit production a number of times.
For example, we configured many Monte Carlo custom rules to codify and enforce simple expectations about our data:
- “Timedeltas between progressive data points along the time axis should be positive.”
- “Features expressing probabilities should be bound between 0 and 1.”
- “Anomaly detectors that report themselves ‘online’ need non-NULL detection thresholds.”
We surprised ourselves with how often these “obvious” invariants would end up broken in dev over a proposed (and seemingly innocuous) architectural change.
We also configured Monte Carlo monitors on numeric values to let our own anomaly detection work for us:
- “Here’s the historical rate of notifications broken down by [warehouse type / customer / detector subtype]. Notify me if it ever significantly changes.”
I’d encourage data science teams to consider this type of data quality monitoring as organizations race to incorporate GenAI and similar initiatives at a breakneck pace.
The early results: better ML models, more customer value
While we are still relatively early in our journey, I can say with confidence that migrating our feature store to Snowpark has increased the value our ML models generate for our customers.
Processes aren’t just more efficient (in one case the runtime of an inference algorithm was reduced from one hour to 20 minutes), model granularity has increased as well. I’ll provide one quick example here.
Time series decomposition is a critical component dictating how data freshness anomaly detectors work and handle seasonality. Our data freshness detectors have always been good at handling seasonality, but some of our customers with financial data were asking for more precise models that could better discern between patterns during trading hours and during non-trading hours. The detector understood a 16 hour gap in table updates may not be anomalous, but now it also understands that 16 hour gap is in fact anomalous if it occurs during trading hours.
The technique required to do this–time series (seasonal) decomposition–is close to impossible to do in SQL, yet machine learning Python libraries like statsmodels and scikit-learn easily handle it out of the box. This allows our team to focus on tweaking parameters and performance to our needs rather than implementing the baseline algorithm.
Overall, our conclusion is Snowpark has increased our modularity and reliability while allowing our ML and analytics use cases to happily co-exist.
Interested in how data observability can help with your data science, machine learning, and AI use cases in your modern data stack? Talk to us by scheduling a time using the form below!
Our promise: we will show you the product.
Read more posts.