 Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Snowflake Summit 2023 Keynote Recap: Document AI, Container Services, and More!

This year’s Snowflake Summit is a bit more spread out than last, with the main keynotes taking place across the way in Ceasar’s Palace. While not far as the crow flies, it’s a scientific fact that each Vegas meter takes four times longer to walk.

That didn’t stop conference attendees from locating, descending, and swarming Ceasar’s. The line for the keynote started early and the buzz of anticipation was palpable, and only grew as people began talking their seats.
Table of Contents
Frank Slootman: an AI strategy requires a data strategy
Snowflake CEO Frank Slootman kicked off the keynote and immediately disarmed the audience of AI skepticism/weariness like a pro: “There is a drinking game, every time I say AI you have to do a shot.”
He then launched into his latest stump speech positioning Snowflake’s role in the era of Gen AI.
“We always say in order to have an AI strategy you have to have a data strategy….If you don’t have your data strategy wired in, you can’t just keep going with the past. Real choices have to be made – you can perpetuate what you’ve been doing in the past…or fundamentally shift,” he said.
The Snowflake CEO wasted no time outlining Snowflake’s evolution and expanded ambition, “Most in this room are doing data warehousing. These days we view data warehousing as a particular kind of workload.” He then went on to list Snowflake’s data lake, transactional (Unistore), hybrid, and collaborative (Data Sharing) capabilities.
Of course, he couldn’t resist adding a jab at a competitor as well saying, “A lot of efforts in Snowpark have been focused on retiring legacy Spark jobs. If you’re looking to save some money, save 2-4x on data engineering because our interpretation of Spark in Snowpark, it will run it cheaper, simpler, and more secure. Free money to be had.”
He then quickly outlined the three big announcements we would be seeing and how they tied back to the conference theme of “No Limits On Data” (which come to think of it might have been my cellphone carrier’s tagline for a while too). These were:
- Data: Expanded Iceberg table support.
- Applications: Snowflake native apps in their Marketplace.
- Workloads: Snowpark Container Services, a huge expansion of Snowpark where containerization will help “scoop up” any function that already exists and run it in Snowflake. These containers will also host LLM models to be addressed by the applications themselves.
Notably, the data and application announcements are expanded functionality to build critical mass around some of last year’s major announcements, but Snowpark Container Services sticks out right away as exciting new capabilities that will have an immediate impact on the data world.
Also interestingly, Snowflake seemed to learn their lesson from last year’s keynote. rather than have co-founder, Benoit Dageville, come out to repeat many of the announcements made by Frank, he made a quick panel appearance with Sridhar Ramaswamy, SVP Snowflake, Founder of Neeva and Mona Attariyan, Director of AI/ML to simply reiterate and reinforce the implications of those announcements.
From this point forward it became the Christian Kleinerman show (and no complaints here), as the Snowflake senior vice president of product took us from compelling demo to compelling demo.

Unified Iceberg Tables
Christian started with a quick overview, and reminder really, of Snowflake’s support of Iceberg tables. He discussed how customer feedback was focused on not having any trade-offs in terms of performance between managed and unmanaged Iceberg tables.
He then announced Unified Iceberg Tables: a single mode to interact with external data with no trade-offs whether or not the coordination of changes writes happens by Snowflake or a different system.
Document AI
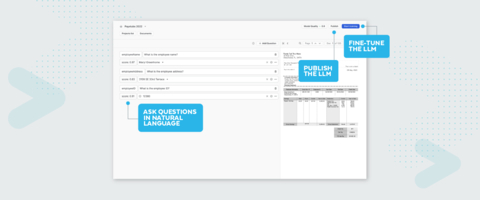
Christian’s next announcement may have been the buzziest of the buzzy: Snowflake’s Document AI. The new service combines technology from Applica, which Snowflake acquired in 2022, with a proprietary large language model to extract and better understand the unstructured data (text) within documents.
Christian showed the power of this feature by discussing a fictional snow goggle company that uses forms to inspect equipment. They can use Document AI to run queries on the data to determine what inspections passed or failed, who completed the inspection, and more. The data can then start being used to train the AI model.
What stands out about Document AI in a sea of Gen AI announcements is its ruthless practicality. This is not a SaaS vendor quickly smashing a square GenAI feature into a round hole to launch their cool marketing campaign. The applications for documents like invoices and contracts seem particularly exciting.
Some governance stuff
New governance features got quick lip service almost like an announcement amuse-bouche. So we too will list them quickly. They were:
- Query Constraints: Snowflake administrators can now define constraints to control which datasets can be accessed and leveraged for analytics and when.
- Improved Data Clean Room with Differential Privacy in SQL and Python: for Snowflake users with more extensive privacy needs, Snowflake announced an all-new differential privacy feature to boost data security during collaboration within Snowflake clean rooms.
Core Engine Updates
Just like last year, VP of Engineering, Alison Lee, took the stage to discuss updates to Snowflake’s core engine.
Last year, I mentioned how these updates are often overshadowed by flashier new features but often have a bigger impact on customers. This year, I can say these updates weren’t overshadowed.
The expanded geospatial support and 15% improvement in query duration was cool, but the talk around new warehouse utilization metrics got an audibly excited reaction from the crowd and it wasn’t hard to see why. We’ve written about Snowflake cost optimization strategies previously, and made note about how selecting the most cost efficient virtual warehouse for each workload was a process of trial and error.
Mihir Shah, CIO and Enterprise Head of Data, Fidelity took the stage to discuss how they have optimized costs in their environment of 800 datasets and 7,500 users by ingesting data once and sharing multiple views from there. That way multiple databases are eliminated. “So finance still gets view what they used to see and so does marketing but everybody’s looking at the one single data set.”
Streaming Pipelines and Dynamic Tables
As little as two years ago you might say that Snowflake is designed for analytical workloads while data lakes are more geared towards real-time and streaming use cases. That is clearly no longer the case as Christian highlighted Snowflake’s Snowpipe streaming capabilities, the ability to ingest data using a Kafka connector, entering general availability.
As part of this discussion Christian also introduced the concept of Dynamic Tables. These were introduced last year as “Materialized Tables.” These tables seek to solve many of the problems within modern data pipeline architecture: namely the issues that can be introduced through complicated data orchestration and transformation processes.
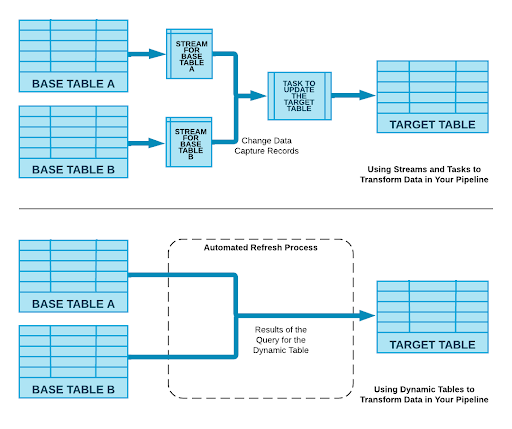
You can think of Dynamic Tables as a table combined with SQL transformation code run regularly with Snowflake tasks. So unlike other transformation tools, this option still requires a level of SQL expertise. However, Christian did discuss text to code capabilities currently in development where a large language model will automatically create the SQL code required.
The finale: Native Applications and Snowpark Container Services
The final announcements focused on what might be Snowflake’s biggest bet: becoming the iPhone app store but for data. Their marketplace and concept of native snowflake apps (hello Steamlit!) was unveiled last year, but this is clearly a multi-year effort that will require multiple pushes to reach critical mass.
To that end the press release mentions:
“Snowflake Marketplace continues to scale as the first cross-cloud marketplace for data and apps in the industry with over 36,000 unique visitors every month. Over the past year, Snowflake Marketplace has increased providers with publicly discoverable listings by 66 percent (year-over-year as of April 30, 2023), with over 430 providers publicly discoverable (as of April 30, 2023) and more collaborating privately.”
This year, Snowflake highlighted their new model registry designed to help store, publish, discover, and deploy ML models. But the main event was clearly Snowpark Container Services.
As Christian described the genesis of the service: “When we did Snowpark, we learned a lot about programming languages in the world. What we wanted to do is accelerate time to value. More run times. More languages. More libraries. The fastest way to do it was by introducing Snowpark Container Services.”
Snowpark Container Services essentially expands the types of workloads that can be brought to data including data apps and hosted LLMs but within a governed container with multiple related services from partners such as NVIDIA, Alteryx, Astronomer, Dataiku, Hex, SAS, and more.

At this point, we were starting to wonder how Snowflake was going to end with anything flashier than what they had previously announced. Christian did not disappoint by introducing what was one of the most interesting and unique tech keynote moments we’ve seen.

Ten demo engineers ran 10 live demos on Snowpark Container Services running concurrently behind a translucent screen (as you can see in the image above).
While it was impossible to fully track and understand each story being told, that wasn’t the point. The power and extensibility of the service was on full display leaving attendees to file out with an inspired sense of what might be possible.
Interested in how data observability and data quality fit in this new era of data? Talk to us!
Our promise: we will show you the product.
Read more posts.





