 Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Ultimate Data Observability Checklist

Your data team is investing in data observability to tackle your company’s new data quality initiative. Great! But what does this mean for you?
Here’s everything you should keep in mind when building or buying a data observability platform.
As data becomes an increasingly important part of decision making and product development, data reliability and quality are top of mind for data engineering and analytics teams.
To address this need, teams are becoming increasingly bullish on data observability, a new layer of the modern data stack that allows teams to keep tabs on the health of their most critical analytics and build organizational trust in data at scale. Just as robust observability and monitoring helps engineering teams prevent application downtime, data observability tools provide visibility, automation, and alerting that help data teams minimize and prevent data downtime.
Investing in data observability is becoming increasingly important as companies collect more and more (often third-party) data. Introducing new data sources and expanding access to new data consumers also naturally leads to more complex pipelines—which increases the opportunities for missing, stale, or otherwise inaccurate data to negatively affect your business.
With data observability, teams can answer common questions like:
- Is my data reliable?
- Where does my data live, and when will it be updated?
- How do I know when changes have been made to this data?
- Which data assets are most important to my business? How are they being used? Are they fresh and accurate?
As the need for data observability increases, some teams are building their own tools, while others look to existing solutions. While we couldn’t be more excited about this growing demand, we also understand that it can be challenging to cut through the noise and understand exactly what your data observability platform needs to deliver.
The following checklist will cover specific outcomes that a robust data observability platform should deliver, organized into four key categories:
- Knowing about data downtime
- Troubleshooting data issues
- Preventing data downtime in the first place
- Protecting your data with a security-first approach
Let’s dive in.
Knowing about data downtime
At a fundamental level, a data observability platform should monitor your data’s health and alert your team when pipelines break or jobs don’t run well before your downstream data consumers notice the issue in their dashboards or queries. Knowing what issues to monitor for can be overwhelming which is where a ML driven approach is critical. Instead of relying on manual tests to check for data quality issues, your data observability platform should intelligently surface when freshness, volume and schema changes are noticed.
The following are two examples of common data issues your data observability platform should automatically detect.
In the first example, we see a significant unexpected drop in data volume within a table, indicating a deletion of records which may or may not be planned.
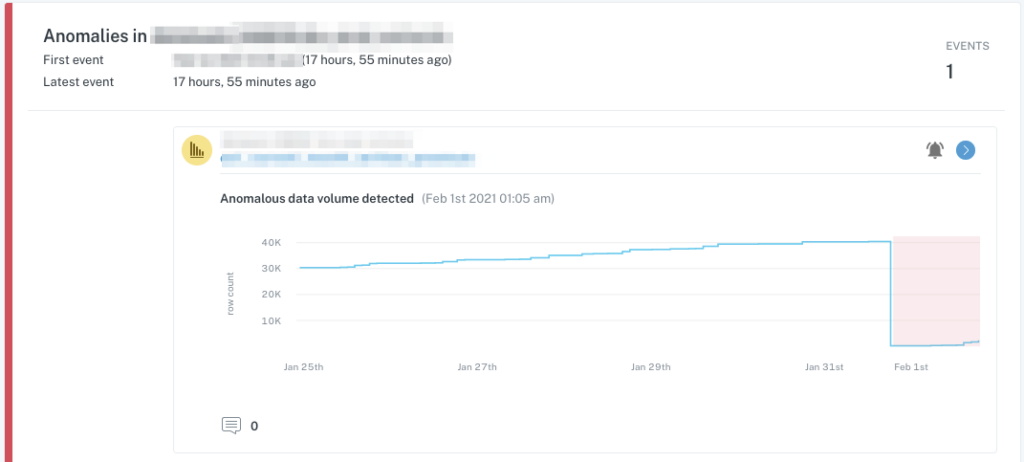
In the second example, we see a schema change to JSON data stored within a table field, which similarly may or may not be planned, but will absolutely require downstream changes when parsing the JSON values.
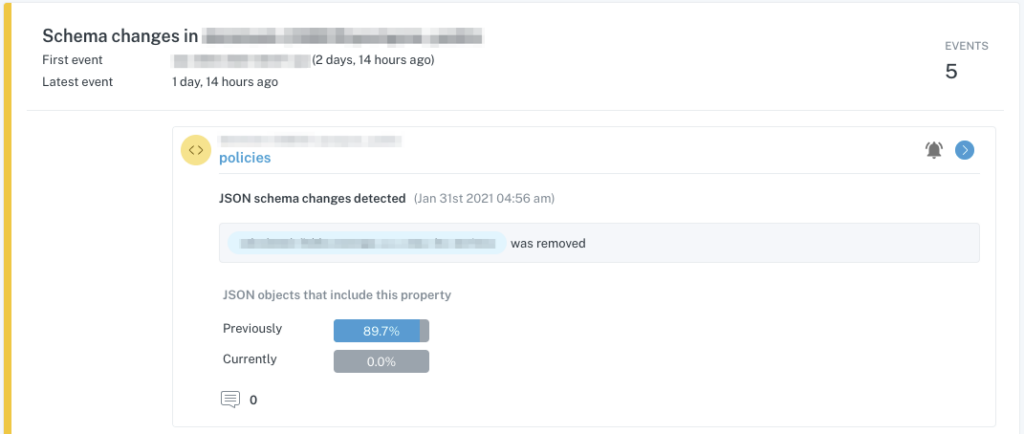
Proactively monitor and alert for data quality issues
This is table stakes for any data observability platform. Just as software engineers rely on monitoring to alert them to any outages or downtime, data teams should be able to rely on monitoring to automatically notify them of any anomalies in data health rather than waiting for an internal consumer or customer to notice something’s gone wrong (which happens to a staggering 57% of businesses.)
Alerts routed intelligently based on data set assignments and incident type
Alerts are only helpful if the proper team (i.e., the data owner) receives them. Your data observability platform should enable routing based on assignments and incident types.
Centralize, standardize, and automate data quality monitoring processes
Data observability should apply across your entire organization, standardizing and centralizing data quality monitoring to ensure every team is speaking the same language and operating from the same playbook.
Automatically generate rules based on historical data
With machine learning, your data observability platform should be able to analyze trends in your data to automatically develop hundreds of rules without anyone in your organization needing to write a single line of code—identifying anomalies, null values, or missing data, and alerting your team accordingly for further investigation.
Provide the ability for data engineers to set their own rules and thresholds based on business-specific requirements
While automation saves manual labor, your data organization knows your data assets best. As a result, your data observability platform should include the flexibility for data engineers, data analysts, and data scientists to set their own thresholds to monitor data according to business needs or as new pipelines and projects are introduced.
Automated anomaly detection based on historical trends at the field level
The aforementioned ML-based anomaly detection should function at the field level—not just the table level–based on historical metrics and statistics about your data.
Self-service data discovery
Data observability doesn’t just cover anomaly detection. A strong data observability platform will enable users to the data they need by indexing all assets (including BI reports and dashboards) for search and discovery. Data health metrics, augmented with business context, give your data consumers super powers when it comes to finding the right data for any given job.
Continuous monitoring and alerting against standard data quality dimensions as well as lineage
Alerts against quality dimensions are great: they notify you when data is missing, incomplete, or otherwise inaccurate. But without lineage—tracking all data integration operations on a record-by-record basis, across all pipelines and environments—you’ll have a much harder time figuring out what went wrong. Both should be provided by your data observability platform.
Troubleshooting data issues
The second category of outcomes — troubleshooting data issues so you can fix them, fast — should focus on making it easy to understand what data broke and why, while also giving your team the tools to track downstream and upstream dependencies before they impact the business.
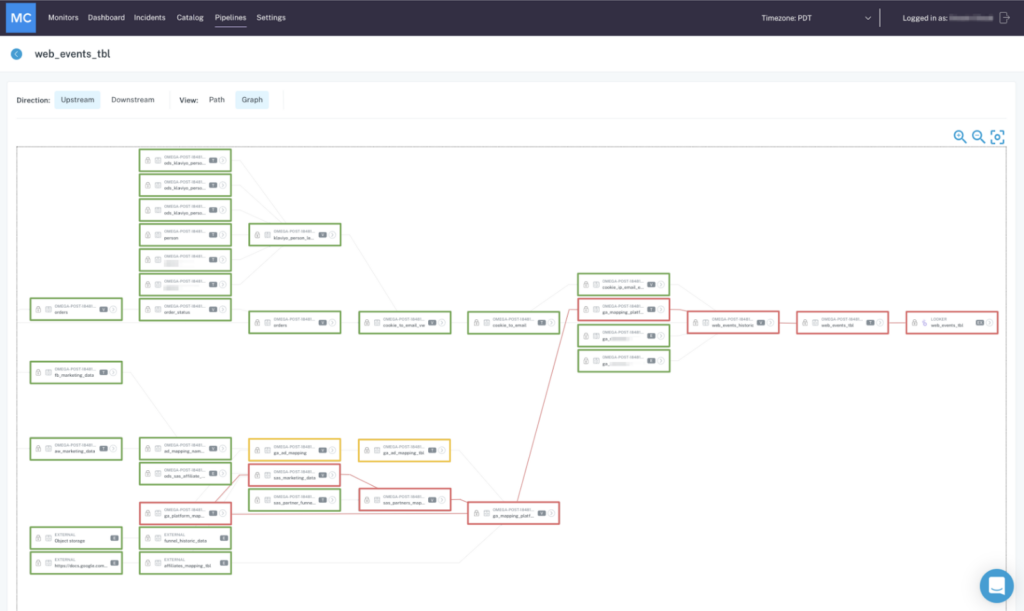
Understand the business impact of issues and prioritize issue resolution
An intelligent platform will be able to assess the likely business impact of data downtime based on downstream data consumption—and prioritize issue resolution accordingly.
Intelligently route alerts to the appropriate team(s) via their preferred channel(s)
Alerts should be meaningful communications, not white noise. Not only should your data observability platform support intelligent routing of alerts to the right team members—ideally, those alerts should be delivered via their preferred channels (think Slack, email, or SMS text message).
Search for and explore data assets with a simple UI
When it comes to addressing broken data, speed and accessibility matters. A clean, simple interface helps your team search for and review data assets swiftly, using Catalog and Lineage functionalities to identify the root cause of incidents.
Collect and display information required for investigating and resolving issues
Your platform should deliver all the relevant information required to resolve issues at the alert or case level, reducing the need for manual investigation and speeding up the time to resolution.
Root cause analysis via end-to-end lineage
When your platform provides full visibility into your end-to-end lineage, you can take the guesswork out of root cause analysis by immediately accessing the full lifecycle of your data.
Collaborate to resolve incidents and mark them as notified, resolved, no action required or false positive
Your platform should make life easier by keeping everyone affected by a given incident on the same page with visible status reports on every issue.
Access incident alert logs with complete incident information for analysis and reporting
Comprehensive logs are a must: they help every team member stay in the loop, reduce time-to-resolution for common issue types, and enable data leaders to analyze and identify recurring issues.
API integrations to ensure that monitoring and alerting about key elements of your pipeline can be routed to the appropriate party
A modern data observability platform should offer thorough API access to all attributes so you can customize workflows that fit into your existing tech stack and empower your team to save time, avoid duplicative efforts, and solve problems swiftly.
Preventing data downtime
No matter how great your data observability platform is at identifying and alerting you to data downtime, your best efforts at maintaining reliable data pipelines will be all for naught if you can’t be proactive about incident prevention. A true end-to-end data observability solution will take data quality monitoring a step further by leveraging machine learning to understand historical patterns in your data through intelligent catalog and lineage capabilities.
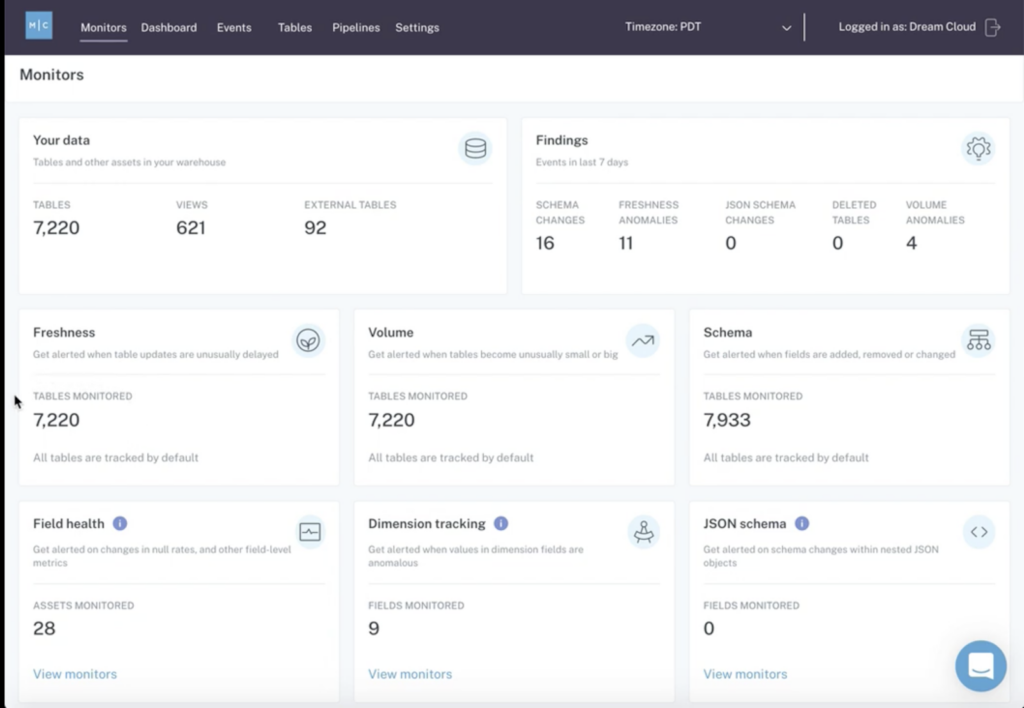
Data quality and health information for all assets
Apart from alerting when something goes wrong, data observability tooling should provide a holistic view of data quality and health for all assets at all times based on both historical patterns and the current state of data affairs.
Understand fields and field types at a glance through lineage
When a data observability platform includes lineage, you should gain a “catalog”-level view into data fields and field types that provides an at-a-glance overview of the relationships between data assets and overall data health.
Understand critical reports and dashboards tied to table and field lineage
Data observability should enable data teams to understand which BI reports use which fields—helping ensure schema changes don’t unintentionally break BI reports or frustrate downstream data consumers.
Analyze field-level metrics/ statistics and how they’ve changed over time
Your data observability platform should be able to understand how the data is changing and evolving over time, so you can track important metrics at a granular level.
Dynamically update schema metadata and information
With a data observability platform, your metadata should update dynamically, without requiring manual changes.
Identify what your key assets are and how they are being used
Your data observability platform should answer pertinent questions, including: who is using this data, what are they using it for, when are they accessing this data, and how often does this data go “down” (i.e., stale, missing, etc.)? Data observability should include insights that help you understand how key data assets are being used, helping enable version control and allowing you to identify and deprecate outdated assets—ensuring you’re not using the wrong data for important business decisions or to power digital products.
Assess timeliness and completeness by analyzing table load pattern metrics
Your data platform should help you verify assumptions about your data’s freshness and volume, ensuring that your expectations meet reality.
Protecting your data

Data observability platforms should never require data to leave your environment — full stop. The best approaches will not require having to store or access individual records, PII, or any other sensitive information. Instead, data observability should only extract query logs, metadata, and aggregated statistics about data usage to ensure that your most critical data assets are as trustworthy and reliable as possible.
Monitoring data at rest
Your data platform should be designed with a security-first approach that monitors data at rest and does not require access to your data warehouse.
SOC2-certified
Your data observability platform needs to be SOC2-certified, which measures controls including security, availability, processing integrity, confidentiality, and privacy.
Identify breaking changes quickly from query logs and schema change logs
Your platform should use metadata such as query logs and schema change logs to automatically alert when changes break your data pipelines. By using this metadata instead of the data itself, your platform provides an additional layer of security.
Getting started with data observability
Ultimately, your data observability should enable everyone who interacts with your data, from an engineer to an end consumer, to answer a complex question with confidence: “Is this data trustworthy?”
Whether you build your own solution or buy one from a vendor, true data observability will bolster trust throughout your organization and open up new opportunities for teams to leverage data. At the same time, your data engineering team should get valuable time back from constant fire drills and manual investigations, allowing them to focus on innovating, solving problems, and helping your business grow.
Interested in learning more about what to look for in a data observability platform? Reach out to Stephen and the rest of the Monte Carlo team.
Read more posts.





