Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage The Art of Data Workflows: A Step-by-Step Guide


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
Why do some data strategies thrive while others struggle?
It all comes down to the planning of their data workflow.
Companies with a robust and well-defined data workflow can turn raw data into actionable insights, while those without one might struggle to make sense of their data.
In this article, we’ll dive in to understand what a data workflow is, why it’s important, and how to implement a successful data workflow to ensure your data team can deliver successful, reliable data products.
Table of Contents
What is a Data Workflow?
A data workflow is the series of steps that a company needs to follow to achieve their data goals. It covers everything from data collection to data maintenance, ensuring that data is properly managed, analyzed, and utilized to drive business decisions.
Why Having a Data Workflow is Important
Having an organized data workflow is important because it gives structure to your data management strategy. It helps in achieving consistency, improving data quality, and ensuring that data-driven decisions are based on accurate and reliable information.
How to Implement a Data Workflow: From Planning to Maintenance
There are multiple steps for building a data workflow. Let’s explore each stage of this process, from initial goal setting to ongoing maintenance, using an eCommerce company as our guide.

1. Goal Planning and Data Identification
Before diving into data collection, it’s crucial to establish clear objectives. This stage involves defining specific, measurable data goals aligned with business objectives and identifying the types and sources of data needed to achieve these goals.
Our eCommerce company sets an ambitious goal: to increase customer lifetime value by 20%. To achieve this, they identify key data points they’ll need, including purchase history, browsing behavior, customer demographics, and customer service interactions.
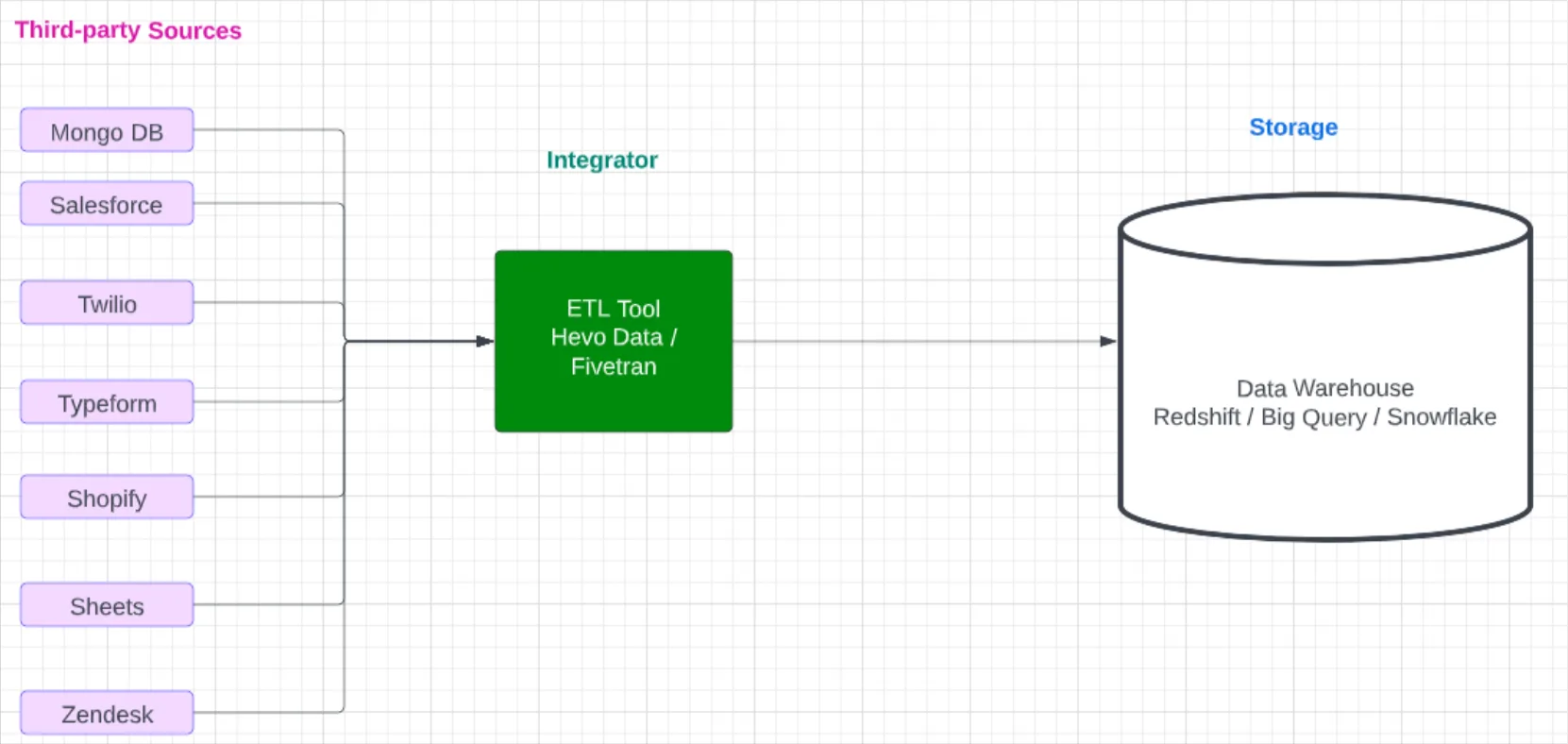
2. Data Extraction
With goals set, the next step is gathering the required data. This phase includes connecting to various data sources and implementing data collection methods.
The eCommerce company begins extracting data from multiple sources: their website analytics platform provides user behavior data, the CRM system offers customer information, the inventory management software supplies product data, and social media APIs deliver customer sentiment insights.
3. Data Cleaning and Transformation
Raw data often contains errors and inconsistencies. This crucial stage involves identifying and correcting errors, removing duplicates, and transforming data into a structure suitable for analysis.
Our eCommerce company faces several challenges here. They standardize product names that vary across different systems, correct errors in customer address information, and transform raw click-stream data into meaningful user journey metrics.
4. Data Loading
Once cleaned and transformed, data needs to be stored for analysis. This step includes selecting appropriate storage solutions and loading the processed data.
The eCommerce company opts for a cloud-based data warehouse. They design an efficient schema, organizing data into fact and dimension tables for optimized querying and analysis of sales, customer behavior, and inventory movements.
5. Data Validation
Ensuring data quality is an ongoing process. This stage involves implementing automated data quality checks and verifying data accuracy and completeness.
To maintain data integrity, the eCommerce platform implements automated checks to flag any unusual patterns in order data, such as sudden spikes in returns or abnormal pricing. This ensures reliable data for sales forecasting and inventory management.
6. Data Analysis and Modeling
This is where data transforms into actionable insights. Key activities include applying statistical analysis techniques and developing machine learning models.
The company’s data science team gets to work, developing a machine learning model to predict customer churn. They identify key factors influencing customer loyalty, such as shipping times and the effectiveness of product recommendations, providing valuable insights for improving customer retention strategies.
7. Data Governance
Proper management of data assets is critical. This ongoing process involves establishing data access controls, implementing security measures, and ensuring regulatory compliance.
Given the sensitive nature of customer data, the eCommerce company implements strict data governance policies. They ensure compliance with regulations like GDPR and CCPA, establishing clear guidelines on data usage for personalized marketing and customer analytics.
8. Data Maintenance
To keep the data workflow effective, regular upkeep is necessary. This includes scheduling regular updates, monitoring data quality, and optimizing systems for performance.
The eCommerce company establishes a robust maintenance routine. They schedule nightly updates of sales and inventory data, archive historical transaction data after two years to optimize storage, and regularly fine-tune their database indices. Additionally, they integrate a data observability platform such as Monte Carlo.
All of this ensures accurate and reliable information for decision-making, operational efficiency, and regulatory compliance.
By following these steps, the eCommerce company creates a comprehensive data workflow that not only meets its immediate analytical needs but also ensures long-term data reliability and usefulness. This data-driven approach ultimately drives business growth, enhances customer satisfaction, and gives them a competitive edge in the fast-paced world of online retail.
Common Data Workflow Challenges
As we saw with our eCommerce example, implementing a data workflow isn’t without its challenges. Common issues include ensuring data quality and integration, managing scalability and performance, and maintaining security and privacy.
Data Quality and Integration
The usual blocker to any data workflow is the accuracy and completeness of a company’s data. There can be inconsistencies between different data sources and systems that first need to be resolved before the rest of the process can continue.
Scalability and Performance
Then, as the volume, velocity, and variety of data increase, managing scalability becomes the main concern. Addressing performance bottlenecks in data processing and ensuring system responsiveness as data grows are essential to maintain efficiency.
Security and Privacy
But protecting sensitive data from breaches and ensuring compliance with data protection regulations are also ongoing worries. Balancing the need for data accessibility with the necessity of maintaining privacy requires robust security measures.
Tools to Solve Data Workflow Challenges
To overcome these complexities of modern data workflows, we can use a variety of specialized tools and platforms. Here are some categories of common solutions:
ETL (Extract, Transform, Load) Tools
To best tackle data integration issues, it is best to use a robust set of ETL tools. These tools automate the process of extracting data from various sources, transforming it to fit operational needs, and loading it into the target database. Some examples are Apache Kafka, Apache Nifi, and Fivetran.
Data Orchestration Tools
Another option for organizing data across multiple systems is data orchestration tools. These tools coordinate and automate complex sequences of data processing tasks across multiple systems, improving efficiency, reducing errors, and enabling better management of interdependent data tasks.
As we discussed in our article on data orchestration tools, Apache Airflow is by far the most popular option, but there also exists some great alternatives such as Luigi, Prefect, and Dagster that may better suit your needs.
Data Observability Platforms
But how do we know that any of these tools are actually working as intended? That is where data observability comes in. Data observability platforms monitor and measure the quality and performance of data throughout its lifecycle, detecting anomalies and allowing us to troubleshoot issues quickly to ensure data reliability.
Keep the Data Flowing with Monte Carlo
One such example is Monte Carlo. Monte Carlo’s data observability platform provides automated anomaly detection, end-to-end data lineage, and real-time monitoring, making it an essential tool for maintaining the integrity and performance of your data workflow. By using Monte Carlo, organizations can ensure that their data remains accurate, consistent, and reliable to ultimately drive better decision-making and business outcomes.
To see how Monte Carlo can transform your data strategy, speak to our team!
Our promise: we will show you the product.
Frequently Asked Questions
What is the difference between data pipeline and workflow?
A data pipeline focuses on the movement and processing of data from one point to another, involving tasks like extraction, transformation, and loading (ETL). A data workflow, on the other hand, encompasses a broader scope, including all the steps needed to achieve specific data goals, from data collection and transformation to analysis, governance, and maintenance.
What are the steps in a data workflow?
The steps in a data workflow include: 1. Goal planning and data identification 2. Data extraction 3. Data cleaning and transformation 4. Data loading 5. Data validation 6. Data analysis and modeling 7. Data governance 8. Data maintenance. Each step ensures that data is properly managed, analyzed, and utilized to drive business decisions effectively.
Read more posts.