 Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is Data Downtime?
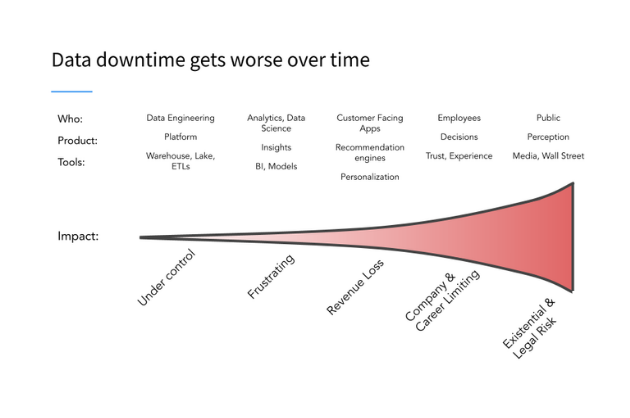
Has your CEO ever looked at a report you showed him and said the numbers looked off? Has a customer ever called out incorrect data in your product’s dashboards?
I’m sad to say, you’ve been the victim of data downtime.
In 2016, while I was leading a team at Gainsight, fondly called Gainsight on Gainsight (GonG), I became all too familiar with these issues. We were responsible for our customer data and analytics, including key reports reviewed weekly by our CEO and quarterly by our board of directors. Seemingly every Monday morning, I would wake up to a series of emails about errors in the data.
It felt like every time we fixed a problem, three other things went wrong. What’s worse, we weren’t catching the issues on our own. Instead, other people, including our very patient CEO, were the one’s actually alerting us. Recently, I talked to a CEO of another company who told me he used to go around the office and put sticky notes saying “this is wrong” on monitors displaying analytics with erroneous data.
At Gainsight, I had the privilege of working with hundreds of companies that were leading industries in their approach to customer data and deriving insights to improve business outcomes. But I saw firsthand that while many companies were striving to become data-driven, they were still falling short. But why?
It was because they had lost faith in their data. And the culprit? You guessed it. Data downtime.
In this post, I’ll discuss what data downtime is, why I coined the term all those years ago, how to identify it, and most importantly, what to do about it.
Let’s dive in.
Table of Contents

What is data downtime?
I’ve met countless founders and business leaders who’ve shared how persistent data issues within company data and dashboards have negatively impacted their culture and hindered their ambitions to drive data adoption across their teams. And the more leaders I met with, the more obvious the problem became. So, I gave it a name, and got to work solving it.
I call this problem “data downtime.”
So, what is data downtime?
Data downtime refers to periods of time when your data is partial, erroneous, missing or otherwise inaccurate. The problem of data downtime is incredibly costly for data-driven organizations, but while it affects almost every data team across industries, it’s still typically addressed reactively on an ad-hoc basis.
The term downtime harkens back to the early days of the Internet. Back then, online applications were a nice-to-have, and if they were down for a while — it really wasn’t a big deal.
Back then, since businesses weren’t yet totally dependent on those applications, they could afford a little downtime now and then. Fast forward two decades, and online applications are mission-critical to almost every business. As a result, companies measure downtime meticulously and invest a lot of resources in avoiding those service interruptions.
In the same ways companies became reliant on online applications, companies have become increasingly reliant on data—to manage daily operations, power consumer products, and even to make their most mission-critical decisions. But while data has become just as essential to the modern business, it’s still not being treated with the same level of diligence—a level of diligence it desperately needs.
While more and more companies are putting SLAs in place to hold data teams accountable for their data’s reliability, there’s still a long way to go. In the coming years, and particularly as GenAI takes grows in popularity, data downtime will continue to take center stage—and along with it, the strategies and practices to fight it.
Examples of data downtime impacting a business
Now that we know what data downtime is, let’s consider how to identify it.
Data downtime can occur for a variety of reasons, including for example an unexpected change in schema or buggy code changes. It is usually challenging to catch this before internal or external customers do, and it is very time consuming to understand root cause and remediate it quickly.
Here are some examples of how data downtime might be affecting your company:
- Consumers of data, internal and external, are calling up with complaints about your data and are gradually losing trust. The customer might be thinking “Why am I the person spot checking data errors for this company?” Perhaps the CEO thinks: “If this chart is wrong, what other charts are wrong?”
- You are struggling to get adoption for data-driven decision making in your company, putting yourself at a disadvantage against your competitors. Folks might be saying “The data is broken anyway and we can’t trust it, so let’s just go with our intuition.”
- Your analytics/BI, data science, data engineering and product engineering teams are spending time on firefighting, debugging and fixing data issues rather than making progress on other priorities that can add material value to your customers. This can include time wasted on communication (“Which team in the organization is responsible for fixing this issue?”), accountability (“Who owns this pipeline or dashboard?”), troubleshooting (“Which specific table or field is corrupt?”), or efficiency (“What has already been done here? Am I repeating someone else’s work?”).
7 common causes of data downtime
While data downtime comes in a variety of forms and outages, data downtime issues (sometimes referred to as data quality issues) tend to trace back to a handful of common problems. Here are 8 of the most common data downtime issues:
- NULL values: a field that has been left blank either intentionally or through a pipeline error owing to something like an API outage.
- Schema changes: a broken pipeline caused by an upstream schema change.
- Volume issues: how much data is entering your pipelines? Is it more than expected? Less? When these numbers fall outside your expected range, it’s considered a volume issue.
- Distribution errors: data that skews outside an acceptable range and therefore no longer reflects reality.
- Inaccurate data: anytime data is incorrectly represented. Inaccurate data could be as simple as an SDR adding an extra zero to a revenue number or a doctor incorrectly typing a patient’s weight.
- Duplicate data: any data record that’s been copied and shared into another data record in your database.
- Relational issues: sometimes referred to as referential integrity, this problem connotes issues that exist between parent-child table relationships in a database.
- Typing errors: the most human of data downtime issues—typing errors. In a distributed professional landscape, the opportunity for little typing errors to make their way into your pipelines is virtually unlimited.
- Late data: data that hasn’t refreshed on time and is therefore no longer accurate for downstream users.
Because of the proliferation of downtime issues and causes, and the seemingly inordinate num bar of opportunities where they might occur, it’s important to have some sort of data downtime analysis protocol in place, including machine learning monitors to detect unknown unknown issues broadly, a robust data quality testing practice for known issues, and data lineage to map out root causes and resolve issues faster. This is most effectively supported through the use of an end-to-end data observability solution.
How do you calculate data downtime?
The formula to calculate data downtime is relatively simple. To understand the impact of data downtime on your organization, you’ll need to have a few pieces of information: the number of incidents over a given time period, how long it took you to detect the average incident, and how long it took you to resolve the average incident.
Once you have that information, you can follow the formula below:
Number of incidents x (average time to detection + average time to resolution)
This is helpful in measuring how your overall data product reliability is trending. But in this case, we aren’t as interested in the aggregate data downtime or the efficiency of the team (yet).
Should data downtime be a KPI?
Data teams can draw a direct line between the availability of a data asset and its performance for a given use case. If the data pipeline is up, that data asset has the opportunity to deliver value. If the data pipeline is down, the opportunity to deliver value goes down with it.
Because data uptime is directly correlated to the impact—and by extension the ROI—of your data assets, it behooves data teams to consider data downtime as a critical KPI for high-value data assets.
Of course, the less valuable a data asset is, the less impact data downtime is likely to have. But if data downtime doesn’t demonstrably impact a data asset, is it really a data asset your team should be maintaining in the first place?
Data downtime needs data observability
Tomasz Tunguz recently predicted that “Data Engineering is the new Customer Success.” In the same way that customer success was a nascent discipline and is now becoming a prominent function in every business, data engineering is expected to similarly grow. I couldn’t agree more and would add that the problem of data downtime spans many teams in data-driven organizations.
As companies become more data-driven and sophisticated in their use of data, along with business functions increasingly becoming heavier consumers of data, I expect the problem of data downtime to amplify and grow in importance (New: see just how much with our data quality value calculator). Solutions like data lineage—a key component of data observability—have already emerged to help teams across the industry mitigate data downtime.
At Monte Carlo, we’re committed to empowering the future of reliable data and AI, and stamping out data downtime wherever we find it.
If data downtime is something you’ve experienced, I’d love to hear from you!
Our promise: we will show you the product.
Read more posts.





