Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Barr’s Top 5 Articles of 2024


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.
Still reeling from the anarchic introduction of generative AI, 2024 saw the beginnings of a tectonic shift in how we manage, enable, and activate our data for business users.
And that left a lot of things to write about.
For anyone following the data space over the last year, I shared quite a few articles on the hot-button topics that got me excited, from the evolution of data quality to the maturation of self-service architectures—and a whole lot of AI.
So, as we round out the year, here are 5 articles from 2024 that I think are worth a second look!
Catch up on what you missed or double-click on some of my favorite topics.
Table of Contents
The Past, Present, and Future of Data Quality Management
The times, they are a-changin’. And so is how we manage data quality.
If you’ve followed me for any length of time, you know I talk A LOT about data quality—and for good reason. Whether we’re talking about dashboards or ML models, garbage in always means garbage out. Unfortunately, as your data environment grows, traditional data quality methods become proportionately less effective.
And at the dizzying scale of AI, traditional data quality methods are struggling to keep pace.
Today, data quality isn’t merely a business risk—it’s an existential one. From a lack of necessary automation to a lack of incident management features, traditional data quality methods can’t monitor all the ways your data pipelines can break—or help you resolve it quickly when they do. And that’s a big problem for AI.
The meteoric rise of AI has made data quality a zero day risk for modern businesses—and the single biggest problem for data teams to solve.
In this piece, I dive into the specifics of three popular data quality methodologies—testing, monitoring, and observability—including where they perform best, where they fall short, and how you can effectively scale your data quality practice to drive data trust across products and domains.
The Data ROI Pyramid: A Method for Measuring & Maximizing Your Data Team
If “production-ready AI” was the journey in 2024, ROI was the intended destination.
When AI first strolled onto the scene in 2022, there was so much hype, it was nearly impossible to navigate the suffocating cloud of LinkedIn evangelists. Would GenAI replace data engineers? Would every workflow be enabled by ChatGPT? Was artificial general intelligence really just around the corner?
By 2024, that cloud had softened considerably. The initial AI startups were beginning to fizzle. Once frenzied boards were cooling their heels. And dev teams finally accepted the harsh reality that putting an API call out to OpenAI doesn’t magically turn a broken chatbot into an AI assistant.
Today, maximizing and measuring data team ROI is on every data leader’s agenda. And delivering value from AI investments is right near the top of that list. Unfortunately, proving the value of any data project is difficult at the simplest of times. And we’re certainly not in the simplest of times.
In the months leading up to 2024, my team spoke with a number of data leaders to discover what makes a data investment financially viable. After iterating on a variety of ROI formulas, we arrived at a solution that, if not capturing the exact value of a data team, can at least get us a little closer.
The goal of this pyramid is aimed squarely at helping data leaders
- Get closer to the business
- Balance competing priorities
- And focus on the right metrics to generate value for their stakeholders.
Curious? Enter if you dare.
5 Hard Truths About Generative AI for Technology Leaders
The truth hurts. And when it came to AI-readiness, there were a lot of organizations that needed a strong dose of reality in 2024.
For about the last 36 months or so, organizations have been scrambling to build and release new AI features that could make them competitive in the AI arms race. And what those teams found out pretty quickly was that it wasn’t the building that was the hard part—it’s creating something useful that’s the real challenge.
Want my radical candor? Here’s a truth bomb.
- Your features aren’t well adopted
- You’re scared to do more
- RAG is hard
- Your data isn’t ready
- You’ve sidelined your data engineers.
So, what’s the secret? It all starts with the data.
Check out the article for my full breakdown of the 5 hard truths every technology leader needs to understand to deliver production-ready AI in 2025.
Most Data Quality Initiatives Fail Before They Start. Here’s Why.
There’s one topic that gets me out of bed faster than anything else—and that’s operationalizing data quality.
Every day I talk to organizations ready to dedicate huge amounts of time and resources to data quality initiatives that are doomed to fail. But why? And what can teams do about it?
The reality is, you could have the best data quality strategy in the world—but if you can’t get buy-in to operationalize it across your organization, you’re still going to have the exact same number of data incidents and a whole lot less money to show for it.
Any data quality strategy worth its engineering time will be a mix of tooling and process. It’s how you incentivize that process that will make the difference.
It’s no revelation that incentives and KPIs drive good behavior. Sales compensation plans are scrutinized so closely that they often rise to the topic of board meetings. In this article, I asked the question: What if we gave the same attention to data quality scorecards?
Read on to find out.
When a Data Mesh Doesn’t Make Sense for Your Organization
If there’s one thing I’ve come to realize over my years in the data space it’s this: there will always be hype.
And if you’re old enough to remember what life was like before the AI uprising, there’s one data trend that eclipsed them all.
The data mesh.
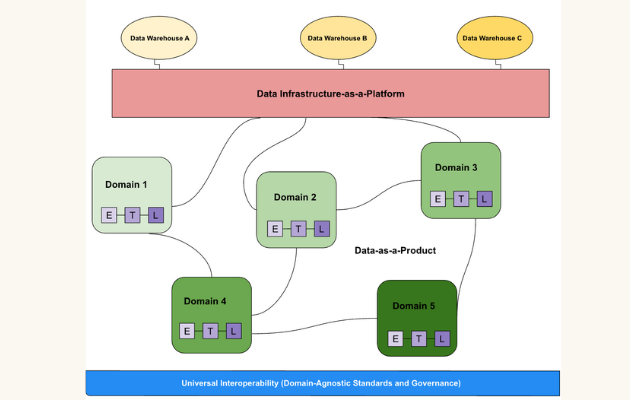
For those of you who’ve forgotten, the data mesh consists of four key components:
- Data-as-a-product
- Domain-oriented ownership
- Self-service functionality
- Interoperability and standardization
And like every trend that rises the ranks of industry hype, there was a nugget of truth to the data mesh legend.
As far as enterprise data architecture is concerned, the data mesh is a deeply thoughtful decentralized approach that effectively facilitates the creation of domain-driven, self-service data products.
The problem is that not every organization should organize their architecture this way—or has the resources to support it.
Building a data mesh is expensive—and it shouldn’t be taken lightly. Lack of talent density, overlapping product needs, and small orgs are all signals to exercise caution before wading into the data mesh.
But just because the data mesh isn’t for everyone, doesn’t mean it’s for no one—and 2024 saw also some incredible examples of large enterprise teams leveraging the data mesh to great effect: like the team at Roche that expedited their product development cycle and delivered data quality at scale in the face of growing business demand.
Our promise: we will show you the product.
Read more posts.