Product demo.
Product demo.  3 Steps to AI-Ready Data
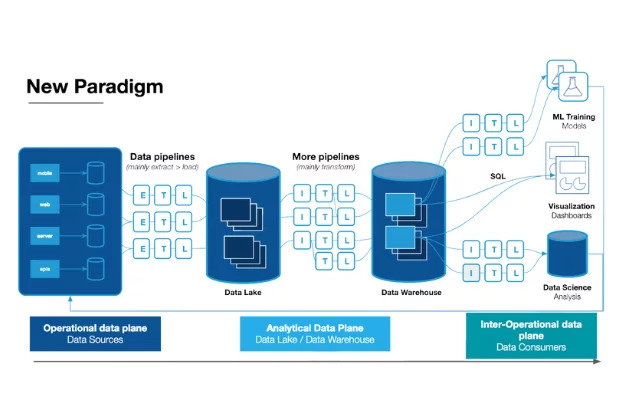
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Treat Your Data Like An Engineering Problem: An Interview with Snowflake Director of Product Management Chris Child
Monte Carlo’s Barr Moses sat down with Snowflake Director of Product Management Chris Child to talk about building data platforms at scale, how awesome data teams approach data quality, the role of data observability tools in the modern data stack, and more.
To put it simply, to understand modern data engineering, you need to understand Snowflake. And as your data platform becomes productized, you need to get serious about data quality.
Chris oversees the functionality and design of the Snowflake platform. Prior to Snowflake, he spent time as VP of Product at Segment and as a Senior Associate of an early stage tech venture capital firm.
I’ve known Chris for a long time and count him as one of the most visionary people working in data technology today. When I was at a crossroads in my career, it was Chris who I leaned on for insights into what was coming next and the role I wanted to play in shaping it.
As someone actively defining and evolving the vision, roadmap and definition of success at Snowflake, Chris’s insights provide a glimpse into the future evolution of the industry.
As Chris sees it, the next value unlock will be unifying data and its corresponding workloads across the many silos in which it still sits. Organizations will continue to find new and valuable ways to make use of their data–many of which will involve making their data stack part of their customer value proposition.
This will put pressure on teams to reach new levels of data quality, which teams will achieve by continuing to adopt reliability engineering best practices.
Enjoy the glimpse into the future. I believe you will find his perspective as helpful as I did when I grabbed coffee with him more than three years ago before deciding to launch Monte Carlo.
Barr: Snowflake has revolutionized the data space by allowing organizations to scale their data operations without needing to worry about storage and compute as the primary constraints. What do you see as the next scaling challenge and how is Snowflake working to help data teams solve it?
Chris: Even as people move to the cloud, they are ending up with data in a lot of silos. We think Snowflake can help fix this problem by providing a unified data platform that brings everything together and lets you work with all your data sets.
A big part of that strategy is our data marketplace. We want to have the data you need already accessible and available on the Snowflake for the taking. There are a lot of different data workloads, and it can be hard to keep track of everything. For example, I might want to move the data to Spark or S3 buckets for the machine learning folks to work on it. It’s easier if I can do all of it in one place where I can better control, govern and understand who is doing what and why.
We are also making data engineering on Snowflake significantly easier. We support Python and Scala now. We’ve introduced a new user interface to help users understand what’s going on with data copy history and pipeline building.
We’re continuing to work on how to make it easier for teams to discover what’s happening in their data ecosystem–we get customer requests for their own data marketplace for their companies.
Barr: I love the idea of a company data marketplace. So that’s what you’re seeing on the tech side of things. You get to work with world class data teams, what are the best practices you are seeing on the people and process side of it?
Chris: I agree, I do get to work with awesome teams. In a way, Snowflake has become synonymous with good data teams.I had some folks tell me when they are evaluating joining a team they ask if the team uses Snowflake.
In the past, data teams consisted of analysts and IT professionals that were building and managing data systems. Analysts were writing SQL or using Informatica and generally doing a good job of getting data to run, but it wasn’t being treated like an engineering problem.
In a previous role, I ended up in charge of pipelines. In the morning, the marketing team would refresh their Looker dashboards and they’d hound the engineers because something had broken in the overnight batch jobs and no one noticed. Today, that is unacceptable and it can’t scale if your data is growing ten times every year.
People are now treating pipelines like an engineering problem, and we have data engineers using engineering best practices. There has been a lot of progress in the field over the last 20 years when it comes to reliability and quality control. Things like making sure it’s in Git, have someone test it, have observability, have learnings if something goes wrong. That’s become more prominent in the last ten years or so, and has taken off in the last five.
The best data teams approach data like an engineering problem.
Barr: Many of our customers are migrating to Snowflake, or starting to introduce it to new teams. What do you recommend as the next steps for them to scale their operations as they get more serious about their data and its value?
Chris: It’s a three-step process. First, get all of your data in one place with the highest fidelity. Just get the raw data in there.
Second, come up with repeatable pipelines for getting data to your analysts. You don’t want to go back to the raw data every time you want to do something.
Third, is to get people across the organization to trust the data and make sure they are confident in the dashboards they are seeing. This last part is hard.
Data observability tools like Monte Carlo help with a huge chunk of this. The other part of the challenge is defining metrics. You can have 20 different definitions of revenue, for example, and that’s a problem.
Metric stores can help solve this. However you choose to do it, it’s important to know what the definitions are and verify it so leaders can trust the data and metrics.

Barr: Powered by Snowflake is everywhere. Can you explain what Powered by Snowflake is and how teams are using it?
Chris: We had a realization two years ago now that while Snowflake was originally built as a data warehouse, it was being used for a lot more.
We had a lot of customers that complained a query would take more than a second to run. At first I thought they were crazy, but we discovered they were building user facing applications and if it takes five seconds instead of one second, that becomes a bad customer experience.
We realized this could be an opportunity. There are a lot of use cases for building applications and using analytics in this nature–but there weren’t a lot of good options for how to do it.
In the past, analytic heavy apps were building their own custom database, but now other companies wanted to use Snowflake instead. It’s now the fastest growing part of Snowflake.

We’re going into more ways for how we enable connected applications, like what Monte Carlo is doing with your Snowflake data share. Solutions can work inside the customer account and the vendor can provide the analytical data back to the customer.
Barr: It’s funny how users will surprise you, but it goes back to a point you have made in the past that every app is becoming a data app. Can you explain what you mean by that statement?
Chris: We think every app you use is generating tremendous amounts of data around how you are using it. There are a lot of ways that data can be used.
For example, we’ve all paid for a coffee with Square. What Square realized is they have a huge treasure trove of transaction data and their merchants tend to be relatively unsophisticated regarding data.
Square decided they wanted to provide that transactional data back to merchants within their application. So now they are a data app.
This is where data observability comes in. Because, for use cases like this, now that data is part of the customer stack.
If there is an issue with the database or data quality, it’s not an employee that is upset about it, it’s a customer. Those pipelines are part of the production application and it’s incredibly important the data is on time and correct.
Applications are now going to be accessing huge amounts of data, along with data from other applications, to get big coherent views. Our hope is that data becomes more available and flows more easily between applications.
Barr: Speaking of data becoming more available and flowing between applications to create these big coherent views, how does data privacy and security fit into this picture?
Chris: The way data rules are changing is fascinating. Even recently we’ve heard rumblings of a ruling that Google Analytics will be illegal in France, or that third-party cookies are going away completely.
I think it’s a good thing we are putting some walls up. Consumers give away a lot of their data without realizing it. In the past, companies have essentially dropped a Google cookie and let Google figure out the customer patterns and then the company will advertise on top of that. That’s going away and customers are going to have to do it themselves.
We’ve been building a ton of features to track and understand where’s the sensitive data, where’s the non-sensitive data, what data needs to stay geographically located, what data can move around–all these things that I think are going to become more and more important.
Then when we start talking about sharing data across companies, what data can I share? We’re trying to build classification and anonymization natively in Snowflake to understand what data you can share and what data is risky to share.

Barr: Monte Carlo is a data observability company and I’m curious to get our thoughts on how the market has evolved. As you know, you were one of the reasons Monte Carlo started.
Chris: For those that don’t know, Barr is talking about a coffee we had in San Mateo to discuss what was next for her. I’m glad Monte Carlo has worked out, I’d feel terrible if I had pushed you in that direction and it hadn’t!
So how have things changed? Data volumes are up, silos are breaking down. It’s not enough to have someone be the owner of a data set–that doesn’t get it done anymore. We need to go beyond “is the data running?”
We need to understand if there is data quality, and if not, who is responsible for fixing it.
Data observability is important. I need to know if data is up-to-date and if I can trust the dashboard. It will become a critical piece of any data platform.
Data quality and observability are going to permeate everything we do, and what you built at Monte Carlo is going to be a critical part of it.
One of the first questions we got about the Snowflake data marketplace was around how would a user know if the data there was up-to-date.
A big part of the data engineering discipline is defining expectations of the data, and knowing when, and how, they are being met, and what to do if they aren’t.
Barr: What is your favorite part of your job?
Chris: My favorite part is talking with customers. As we said earlier, I get to talk to the best data teams and hear about their problems and the problems they are solving for their customers.
I love it when they tell me about what they are trying to do, but can’t quite get there. When we can help them unlock the solution, that is my favorite part.
Barr: What’s the biggest piece of advice you have for data teams?
Chris: The big thing is: treat data like an engineering problem. Think of it and approach it like you would build your product.
Watch Powered By: How Monte Carlo Built A Data Reliability Platform On Snowflake
Connect with Barr and Chris on LinkedIn.
Want to start integrating data observability across Snowflake and your data stack? Book a time to speak with us in the form below..
Our promise: we will show you the product.
Read more posts.