Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is an AI Data Engineer? 4 Important Skills, Responsibilities, & Tools


Lindsay MacDonald
Lindsay is a Content Marketing Manager at Monte Carlo.
The rise of AI and GenAI has brought about the rise of new questions in the data ecosystem – and new roles. One job that has become increasingly popular across enterprise data teams is the role of the AI data engineer.
Demand for AI data engineers has grown rapidly in data-driven organizations. But what does an AI data engineer do? What are they responsible for? What skills do they need?
AI data engineers play a critical role in developing and managing AI-powered data systems. Let’s dive into the specifics.
Table of Contents
What Does an AI Data Engineer Do?
AI data engineers are data engineers that are responsible for developing and managing data pipelines that support AI and GenAI data products. Let’s dive into what that means.
Core Responsibilities of an AI Data Engineer
AI data engineers have several responsibilities related to AI data products, including:
- Building and maintaining data pipelines for AI and machine learning models
- Developing and managing data architectures that support AI workflows
- Integrating and preparing large-scale datasets for AI and ML model training.
Key Differences Between AI Data Engineers and Traditional Data Engineers
While traditional data engineers and AI data engineers have similar responsibilities, they ultimately differ in where they focus their efforts.
AI data engineers tend to focus primarily on AI, generative AI (GenAI), and machine learning (ML)-specific needs, like handling unstructured data and supporting real-time analytics. They still take on the responsibilities of a traditional data engineer, like building and managing pipelines and maintaining data quality, but they are tasked with delivering AI data products, rather than traditional data products.
The foundational skills are similar between traditional data engineers and AI data engineers are similar, with AI data engineers more heavily focused on machine learning data infrastructure, AI-specific tools, vector databases, and LLM pipelines. Let’s dive into the tools necessary to become an AI data engineer.
Essential Skills for AI Data Engineers
Expertise in Data Pipelines and ETL Processes
A foundational skill for data engineers? The ability and skills to build scalable, automated data pipelines. That means you need to know crucial ETL and ELT processes to extract, transform, and load data not only for traditional data pipelines, but for pipelines supporting AI and ML models as well.
Knowledge of AI and Machine Learning Frameworks
In order to effectively build and manage AI pipelines, an AI data engineer needs to be familiar with machine learning frameworks like TensorFlow, PyTorch, and Scikit-learn. These frameworks are used to bring AI models into production and to conduct research.
A solid understanding of these ML frameworks will enable an AI data engineer to effectively collaborate with data scientists to optimize AI model performance and improve scale and efficiency.
Proficiency in Programming Languages
Knowledge of programming languages is a must for AI data engineers and traditional data engineers alike. Both traditional and AI data engineers should be fluent in SQL for managing structured data, but AI data engineers should be proficient in NoSQL databases as well for unstructured data management.
In addition, AI data engineers should be familiar with programming languages such as Python, Java, Scala, and more for data pipeline, data lineage, and AI model development.
Big Data and Cloud Infrastructure Knowledge
Lastly, AI data engineers should be comfortable working with distributed data processing frameworks like Apache Spark and Hadoop, as well as cloud platforms like AWS, Azure, and Google Cloud.
Enterprise data organizations might run on any of these on-prem and cloud infrastructures – including combinations of them – so it’s essential to be familiar with as many as possible.
Tools and Technologies AI Data Engineers Use
In order to learn and execute the skills mentioned above, AI data engineers need to be familiar with several tools to be considered for a role, including:
AI and Machine Learning Tools
These include several tools and frameworks for developing and deploying AI models, including TensorFlow, PyTorch, Keras, and more.
Data Engineering Tools
Data engineers need to be comfortable using essential tools for data pipeline management and workflow orchestration, including Apache Kafka, Apache Spark, Airflow, Dagster, dbt, and many more. There are dozens of data engineering tools available on the market, so familiarity with a wide variety of these can increase your attractiveness as an AI data engineering candidate.
Data Storage Solutions
As we all know, data can be stored in a variety of ways. Get familiar with data warehouses, data lakes, and data lakehouses, including MongoDB, Cassandra, BigQuery, Redshift and more. Familiarity with data warehouses that offer scalable storage are especially important for AI data engineers.
Data monitoring and Data Observability Tools
Real-time monitoring for data pipelines supporting AI models is extremely important. AI data engineers should have a solid understanding of and familiarity with data observability tools, like Monte Carlo, to ensure the quality and accuracy of the pipelines and outputs of your AI and ML models.
The Role of AI Data Engineers in Supporting AI and ML Models
AI data engineers are responsible for a few key initiatives in their roles, including the following list.
Ensuring Data Quality for AI Models
Just as traditional data engineers are responsible for delivering accurate data, AI data engineers are also responsible for delivering data that’s clean, structured, accurate, and reliable for AI. Because AI data engineers are the developers and managers of the AI data pipeline, it’s their responsibility to ensure the data that’s flowing through those pipelines is trustworthy and accurate. If it’s not, then inaccurate, outdated, or stale data might make its way into an AI model – resulting in inaccurate outputs and diminishing performance.
Collaborating with Data Scientists
AI data engineers have the unique ability to enable data scientists by providing the pipeline infrastructure they need to train, test, and deploy AI models efficiently.
Together with AI data engineers, data scientists can be better prepared to build trustworthy, reliable GenAI and AI models for both internal and external stakeholders.
Real-Time Data Streaming and AI Applications
Streaming and real-time data are essential for many AI applications. In order to provide real-time recommendations or predictive analytics, data needs to be updated as its created to ensure responses are as up-to-date and accurate as possible.
AI data engineers are responsible for building data pipelines and infrastructure that support real-time data for AI-powered insights and applications.
Challenges Faced by AI Data Engineers
Just because “AI” involved doesn’t mean all the challenges go away! In fact, AI data engineers encounter many – and sometimes even more complex – challenges than traditional data engineers. Let’s examine a few.
Handling Large, Unstructured Data
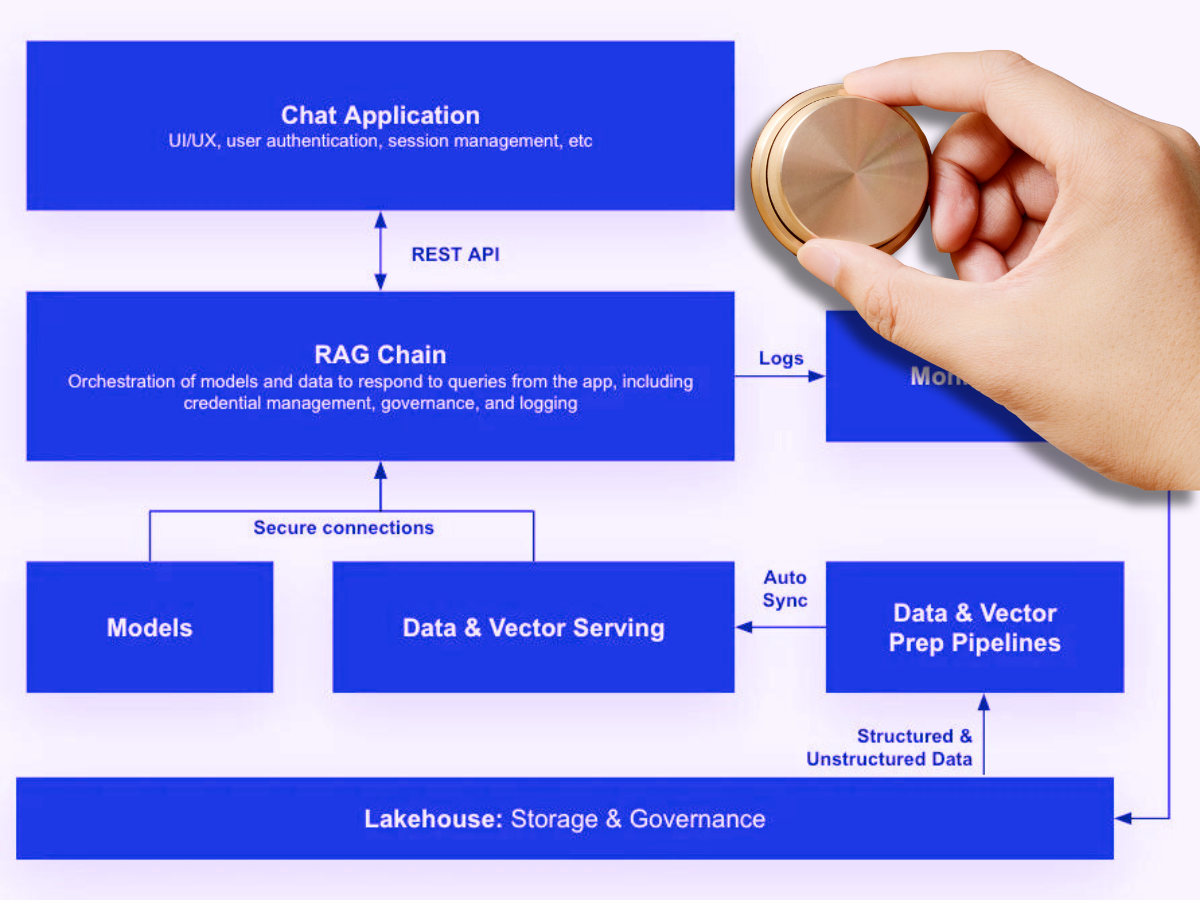
AI data engineers are often faced with the myriad complexities that come with managing and preparing massive datasets for machine learning and AI applications. This might mean having to rethink or redesign some of your data architecture to make room for a semantic layer or vector database (in the case of GenAI) that an LLM can leverage to make sense of unstructured data.
Ensuring Data Pipeline Reliability
As a data organization scales, AI data engineers are also responsible for demystifying the challenges that come with scaling data pipelines for AI workloads. In a growing organization, data drift is more frequent, and AI data engineers need to be cognizant if it happens and fix it right away. AI data engineers are the first line of defense against unreliable data pipelines that serve AI models.
Data Governance and Compliance
AI data engineers work closely with data governance, compliance, and security teams to ensure that all security regulations are abided by when building AI systems. This can come with tedious checks on secure information like PII, extra layers of security, and more meetings with the legal team. While ensuring data is secure and compliant can be a long process, it’s essential for trustworthy AI – and AI data engineers are at the helm.
The Importance of Data Observability for AI Data Engineers
AI data engineers benefit greatly from tools like data observability, which provide end-to-end data monitoring to enable them to detect, triage, and resolve data issues quickly.
Especially when dealing with AI pipelines, AI data engineers require a clear understanding of pipeline health at every stage so they can identify anomalies and resolve data quality issues before they get to the model. As we all know, garbage data in, garbage data out.
Data observability provides visibility into the health of AI pipelines, enabling AI data engineers to proactively identify data drift, get alerted to changes in inputs, and maintain the reliability of the data, ultimately preventing AI model failures.
Ensure Data Quality with Monte Carlo’s Data Observability Platform
At the end of the day, AI data engineers need reliable, high-quality data pipelines to ensure their models perform at their best. Monte Carlo’s data observability platform helps you proactively monitor and maintain data quality, resolve anomalies, and prevent data drift in real-time.
Try Monte Carlo today and empower your AI workflows with accurate and reliable data.
Our promise: we will show you the product.
Frequently Asked Questions
What does an AI data engineer do?
An AI data engineer develops and manages data pipelines specifically for AI and GenAI models. They build data architectures, integrate large-scale datasets, ensure data quality, and support AI and ML model training and deployment.
Is the data engineer replaced by AI?
AI data engineers are not being replaced by AI. Instead, they play a crucial role in supporting AI development, focusing on building and maintaining pipelines, handling real-time data, and collaborating with data scientists to optimize AI models.
Read more posts.