Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage What is Data Accuracy? Definition, Examples and KPIs


Molly Donovan
Imagine you’re on a cross-country road trip and need to fill your car up with gas before the next leg of your journey. You open up Google Maps (or Apple Maps; we won’t judge) and navigate to what the map claims is a local gas station, just a few miles away. Easy enough.
But when you drive up to the address, there’s no gas station to be found! An anomaly certainly given how reliable digital maps are these days, but a data quality error nonetheless, specifically related to data accuracy.
A key component of data quality is data accuracy – in fact, it’s one of the 6 overarching dimensions of data quality. Data accuracy is the degree to which data correctly represents the real-world events or objects it is intended to describe, like destinations on a map corresponding to real physical locations or more commonly, erroneous data in a spreadsheet.
Every day, your company relies on data to make all kinds of decisions: about pricing, about product development, about messaging strategy. If the data they use to inform these decisions isn’t accurate—that is, if it doesn’t reflect reality—then the decisions they make can result in lost revenue, eroded stakeholder trust, and wasted data engineering resources.
A Gartner study found that, “[a]t the macro level, bad data is estimated to cost the US more than $3 trillion per year. In other words, bad data is bad for business.” At certain organizations, like healthcare or fintech companies, the ramifications of inaccurate data can be compromising or even dangerous.
Data accuracy is an absolute necessity for today’s companies—and it’s becoming all the more essential as a growing volume of data flows through any given organization. In this article, we’ll highlight how to determine data accuracy, share examples of inaccurate data, and walk through common impediments to achieving more accurate data. Then, we’ll discuss how modern data teams overcome these challenges and ensure data accuracy across the business.
Let’s dive in.
Table of Contents
- How to determine data accuracy
- Examples of inaccurate data
- Data accuracy vs. data completeness
- Data accuracy vs. data quality
- How to measure data accuracy
- Common data accuracy challenges
- How to ensure data accuracy
- Ensuring data accuracy with data observability
How to determine data accuracy
Determining data accuracy involves assessing the real-world state or values of your information in relation to your expectations (i.e., is the gas station actually where the map says it is?). The specific methods and approaches can vary depending on the context and type of data, but here are some general considerations and techniques:
- Data source evaluation: Start by evaluating the credibility and expertise of the source providing the data. Consider the reputation, credentials, and expertise of the organization or individual responsible for collecting and presenting the data.
- Manual data testing: Verify the accuracy of the data by testing your pipelines for specific data checks, including freshness and volume. Do your tests pass? In other words, is it likely your data is accurate based on your expectations?
- Data collection methods: Understand the methodology used to collect the data. Evaluate whether the methods are technologically sound, transparent, and follow established standards. Look for potential biases, flaws, or limitations in the data collection process.
- Sample size and representativeness: If the data is based on a sample, assess whether the sample size is large enough to be statistically significant and representative of the target population.
- Peer consultation: Seek input from subject matter experts at your company with domain knowledge who can provide insights and perspectives to evaluate the accuracy of the data based on their expertise.
- Automated data observability. ML-enabled solutions like data observability platforms allow data teams to monitor and alert to inaccuracies in tables and dashboards by understanding historical patterns in the data and whether or not they’re consistent with current outputs. Data observability solutions also take testing a step further by providing root cause analysis tools that help teams proactively identify the root cause of data inaccuracies, as they relate to code, your data infrastructure, and even the data itself.
These six tactics can help you determine the accuracy of your data, whether via broad strokes or more granular and automated insights. Regardless of the approach you choose, it’s important to keep a scrutinous eye on whether or not your data outputs are matching (or close to) your expectations; often, relying on a few of these measures will do the trick.
Examples of inaccurate data
Inaccurate data can arise in a few different ways, all primarily due to manual errors, system hiccups, code changes, or data pipeline breakages. Below, we list a few examples:
- Data entry errors: Mistakes made during the process of entering data into a system can lead to inaccuracies. This can include typographical errors, transposition of numbers, or incorrect formatting.
- Outdated information: Data that is no longer valid or relevant due to changes over time can be considered inaccurate. For example, using population figures from several years ago would not reflect the current population size.
- Biased data: Data that is collected or presented in a biased manner can lead to inaccuracies. This can occur due to deliberate manipulation or unintentional biases in the data collection process, such as sampling biases or leading survey questions.
- Incomplete data: Missing or incomplete data can result in inaccuracies. When crucial information is omitted or unavailable, the analysis or conclusions drawn from the data may be flawed or misleading.
- Inconsistent data: Inconsistencies within a dataset can indicate inaccuracies. This can include contradictory information or data points that do not align with established patterns or trends.
- Sampling errors: If data is collected from a sample rather than the entire population, sampling errors can occur. These errors occur when the sample does not accurately represent the entire population, leading to inaccurate conclusions.
- Data misinterpretation: Inaccuracies can arise from misinterpreting the data or drawing incorrect conclusions. This can happen when data is complex or requires contextual understanding, and analysts or users misinterpret the meaning or implications of the data.
- Data manipulation or tampering: In some cases, individuals or organizations may intentionally manipulate or tamper with data to misrepresent or deceive. This can involve altering values, suppressing certain data points, or selectively presenting information to support a particular agenda.
- System or technical errors: Errors within the data storage, retrieval, or analysis systems can introduce inaccuracies. This can include software bugs, hardware malfunctions, or data integration issues that lead to incorrect calculations, transformations, or aggregations.
- Schema changes: For example, a schema change may occur during an automatic maintenance update, or a team member may make a schema change to fix a bug and unwittingly jeopardize data accuracy downstream.
These examples highlight common scenarios where data inaccuracies can occur. It’s important to be vigilant, critically evaluate the data, and employ appropriate techniques to mitigate inaccuracies.
Data accuracy vs. data completeness
To best ensure accurate data, it’s important to understand what data accuracy isn’t. Data accuracy is not synonymous with data completeness—another important factor in overall data quality.
Data accuracy refers to the correctness of values within a dataset. Data completeness, on the other hand, refers to the extent of data coverage. Complete datasets are de-duplicated, they don’t have any missing values, and the information they contain are relevant for the analysis at hand.
Data accuracy vs. data quality
Data accuracy and data quality are related concepts but they are not synonymous. While accurate data is free from errors or mistakes, high-quality data goes beyond accuracy to encompass additional aspects that contribute to its overall value and usefulness. Here’s why data can be accurate but not high quality:
- Incompleteness: Accurate data may still be considered low quality if it lacks completeness. Completeness refers to the degree to which all required data elements are present. Even if the available data is accurate, if it is missing crucial information, it may not provide a comprehensive or reliable view of the information at hand.
- Timeliness: Accurate data that is outdated or not up-to-date can be considered low quality in terms of timeliness. The relevance and usefulness of data can diminish over time, and timely information is often more valuable for decision-making or analysis.
- Consistency: Consistency is an important aspect of data quality. Even if data is accurate within individual records, inconsistencies or discrepancies across different sources or datasets can reduce its overall quality. Inconsistencies may arise due to variations in data formats, coding schemes, or definitions used by different systems or data providers.
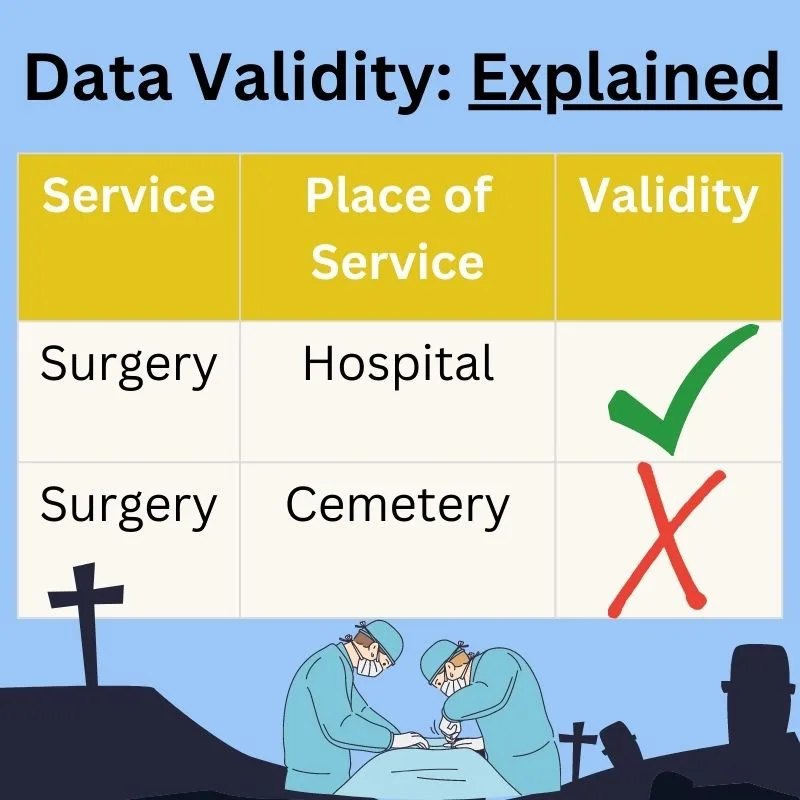
- Validity: Validity refers to whether the data accurately represents the concepts or phenomena it is intended to measure. Accurate data may still lack validity if it does not align with the intended purpose or if the measurement methods or instruments used are flawed.
- Relevance: The relevance of data to the specific problem or analysis at hand is a crucial aspect of data quality. Even if the data is accurate, if it does not address the specific questions or requirements of the task, it may be of limited value or even irrelevant.
- Contextual understanding: Data quality is also influenced by the availability of relevant contextual information. Accurate data without the necessary context or metadata can be challenging to interpret or use effectively. Contextual information includes details about the data source, collection methods, assumptions, limitations, or any other information needed for proper understanding and application of the data.
- Data integration and interoperability: High-quality data should be easily integrated with other datasets and systems. Even if individual datasets are accurate, if they are incompatible, lack standardized formats or common identifiers, or have challenges in data interoperability, it can reduce the overall quality and usability of the integrated data.
- Data governance and documentation: Adequate data governance practices, including documentation of data lineage, data definitions, and data quality rules, contribute to data quality. If accurate data lacks proper governance, documentation, or metadata, it can be difficult to assess its quality or trustworthiness.
While accuracy is a vital prong of this overarching umbrella, other factors—including completeness, consistency, and timeliness—are equally important for ensuring high data quality.
How to measure data accuracy
Data teams can measure data accuracy in a few different ways, by leveraging certain metrics and tools. Common data metrics include:
- Precision, or the ratio of relevant data to retrieved data
- Recall, which measures sensitivity and refers to the ratio of relevant data to the entire dataset
- F-1 score, which is the harmonic mean of precision and recall and calculates the frequency of accurate predictions made by a model across an entire dataset
Different teams deploy various methods and technologies to determine data accuracy, including:
- Statistical analysis, or a comprehensive review of data patterns and trends.
- Sampling techniques, or inferences made about an overarching dataset based on a sample of that dataset.
- Automated validation processes, which leverages technology to automatically ensure the correctness and applicability of data.
Common data accuracy challenges
Multiple headwinds stand in the way of consistent, comprehensive data accuracy. Teams must grapple with the following challenges.
Inaccurate data entry
When data is entered incorrectly—whether by human or schematic error—data accuracy can suffer. Again, these inaccuracies can take the form of inaccurate content (the wrong value is input) or inaccurate form (data is inconsistent, unstandardized, or duplicated).
Data integration and transformation challenges
Inaccuracies can occur in the process of moving data from one location to another, when data is merged from multiple sources. Data may be accurate at origin but become corrupted thanks to data transformation errors or alignment and reconciliation difficulties.
Data governance and management hurdles
Poor data governance practices can jeopardize the accuracy of entire datasets. When various teams have access to a certain dataset, inconsistencies in the treatment and entry of that data can arise. Data inaccuracies often occur in coordination with an insufficient data validation and verification process and with inadequate data documentation and lineage tracking.
Technological limitations
Sometimes, the accuracy of a dataset correlates closely with the strength of its overarching architecture. Technological limitations—including system glitches and errors, data storage and retrieval issues, and insufficient data quality tools and resources—can all lead to data accuracy challenges.
How to ensure data accuracy
While ensuring data accuracy comes with multiple challenges, it can be done. Today’s data teams may consider the following popular methods for bolstering data accuracy.
Data validation techniques
Organizations can implement various validation checks across their data streams to identify and rectify inaccurate data. They can do this by:
- Data profiling, or reviewing and analyzing data to create a high-level, usable overview of data accuracy
- Outlier detection, or identifying and excluding outliers from a dataset
- Cross-field validation, or ensuring data is accurate across several different fields
Data cleansing methods
Before data can be used, it needs to be cleansed in order to ensure data accuracy and, ultimately, data quality. That means data teams need to deploy techniques like standardization, which reduces the likelihood of data form inaccuracies; deduplication, which removes repeat values; and data enrichment, which combines internal data with third-party data to make the overarching dataset more actionable.
Data integration and data transformation accuracy
When integrating data from multiple sources or transforming data for analysis, it’s crucial to maintain accuracy throughout the process. This involves verifying the accuracy and consistency of data mappings, transformations, and calculations. Implement data integration and transformation routines that include data validation steps at each stage, ensuring the accuracy of the data as it moves through the pipeline. Regularly monitor and validate data integrations and transformations to identify and rectify any issues that could compromise data accuracy.
Data governance and management processes
Ensuring data accuracy isn’t a one-time project: it’s an ongoing challenge that must constantly be atop data teams’ minds. It’s essential, thus, to establish robust data governance policies, data quality frameworks, and data stewardship roles to ensure ongoing data accuracy.
While these traditional approaches are useful, they have trouble scaling as data needs grow and the modern data stack grows increasingly complex. Here’s how today’s data teams can supplement or replace these methods with data observability, an automated, end-to-end approach to managing data accuracy across the business.
Ensuring data accuracy with data observability
Data observability platforms like Monte Carlo constantly monitor data and data pipelines, automatically alerting your team when data is incomplete and providing the tools necessary to resolve these issues. Data teams have the ability to set custom data quality checks for known thresholds and establish automatic coverage for freshness, volume, and schema changes.
When they implement data observability, data teams are the first to know when issues occur, which means they can rectify any problems before they become business-critical issues. What’s more, in-depth root cause analysis tooling, like lineage that surfaces the organization’s entire data environment, helps data teams understand exactly what broke, where, why, and who was impacted. Data observability helps data teams understand errors in your team’s SQL query run history for given tables, relevant GitHub pull requests, and dbt models.
In short, data observability gives teams comprehensive, automatic, always-on confidence in their data and endows them with the tools they need to fix problems in near real-time. The best part? Modern data observability solutions implement in under 20 minutes, delivering value out-of-the-box.
When it comes to improving data accuracy, sometimes the simplest – and easiest – way is best.
Reach out today to learn how Monte Carlo can scale data reliability across your entire data pipeline and ensure data accuracy at every stage.
Our promise: we will show you the product.
Read more posts.