Product demo.
Product demo.  3 Steps to AI-Ready Data
3 Steps to AI-Ready Data  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage 5 Reasons Data Discovery Platforms Are Best For Data Lakes


Over the past few years, data lakes have emerged as a must-have for the modern data stack. But while the technologies powering our access and analysis of data have matured, the mechanics behind understanding this data in a distributed environment have lagged behind.
Here’s where data catalogs fall short and how data discovery platforms and tools can help ensure your data lake doesn’t turn into a data swamp. In this blog we will cover:
- Data lake considerations
- Data catalogs can drown in a data lake
- What data engineers need from a data catalog
- The future: data discovery tools
- Data discovery tools automate to scale across your data lake
- Data discovery tools provide real-time visibility into data health
- Data discovery tools leverage data lineage for understanding the business impact of your data
- Data discovery tools empower self-service discovery across domains
- Data discovery tools ensure governance and optimization across the data lake
- Data discovery tools can power distributed discovery for the data lake
Data lake considerations
One of the first decisions data teams must make when building a data platform (second only perhaps to “why are we building this?”) is whether to choose a data warehouse or lake to power storage and compute for their analytics.
While data warehouses provide structure that makes it easy for data teams to efficiently operationalize data (i.e., gleaning analytic insights and supporting machine learning capabilities), that structure can make them inflexible and expensive for certain applications.
On the other hand, data lakes are infinitely flexible and customizable to support a wide range of use cases, but with that greater agility comes a host of other issues related to data organization and governance.
As a result, data teams going the the lake or even lakehouse route often struggle to answer critical questions about their data such as:
- Where does my data live?
- Who has access to it?
- How can I use this data?
- Is this data up-to-date?
- How is this data being used by the business?
And as data operations mature and data pipelines become increasingly complex, traditional data catalogs often fall short of how you would expect a data discovery platforms and tools to answer these questions.
Here’s why some of the best data engineering teams are rethinking their approach to building data catalogs — and what types of data discovery platforms data lakes need instead.
Data Catalogs Can Drown in a Data Lake

Data catalogs serve as an inventory of metadata and provide information about data health, accessibility, and location. They help data teams answer questions about where to look for data, what data represents, and how it can be used. But if we don’t know how that data is organized, all of our best laid plans (or pipelines, rather) are for naught.
In a recent article, Seshu Adunuthula, Director of Data Platforms at Intuit, aptly asked readers: “does your data lake resemble a used book store or a well-organized library?”
And it’s an increasingly relevant one for modern data teams. As companies lean into lakes, they’re often compromising the organization and order implicit in storing data in the warehouse. Data warehouses force data engineering teams to structure or at least semi-structure their data, which makes it easy to catalog, search for, and retrieve based on the needs of business users.
Historically, many companies have used data catalogs to enforce data quality and data governance standards, as they traditionally rely on data teams to manually enter and update catalog information as data assets evolve. In data lakes, data is distributed, making it difficult to document as data evolves over the course of its lifecycle.
Unstructured data is problematic as it relates to data catalogs because it’s not organized, and if it is, it’s often not declared as organized. That may work for structured or semi-structured data curated in a data warehouse, but in the context of a distributed data lake, manually enforcing governance for data as it evolves does not scale without some measure of automation.
The past: manual and centralized catalogs
Understanding the relationships between disparate data assets — as they evolve over time — is a critical, but often lacking dimension of traditional data catalogs. While modern data architectures, including data lakes, are often distributed, data catalogs are usually not, treating data like a one-dimensional entity. Unstructured data doesn’t have the kind of pre-defined model most data catalogs rely on to do their job and must go through multiple transformations to be usable.
Still, companies need to know where their data lives and who can access it, and be able to measure its overall health — even when stored in a lake instead of a warehouse. Without that visibility into data lineage from a data discovery tool, teams will continue to spend valuable time on firefighting and troubleshooting when data issues arise further downstream.
What Data Engineers Need From a Data Catalog
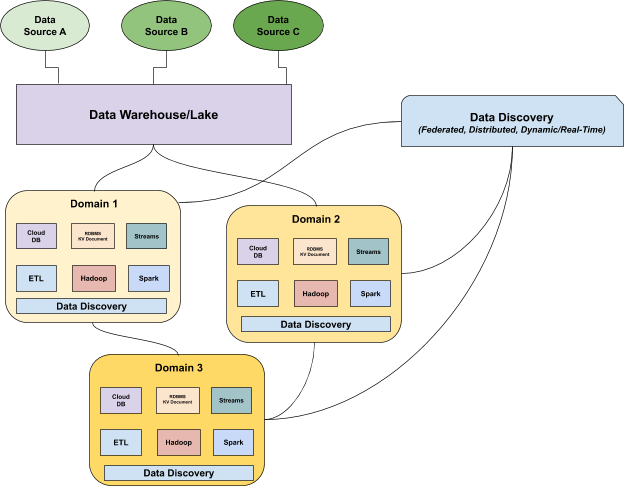
Traditional data catalogs can often meet the demands of structured data in a warehouse, but what about data engineers navigating the complex waters of a data lake?
While many data catalogs have a UI-focused workflow, data engineers need the flexibility to interact with their catalogs programmatically. They use catalogs for managing schema and metadata, and need an API-driven approach so they can accomplish a wide range of data management tasks.
Moreover, data can enter a lake across multiple points of entry, and engineers need a catalog that can adapt to and account for each one. And unlike warehouses, where the data will be cleaned and processed before entry, data lakes take in raw data without any assumptions of end-to-end health.
Within a lake, storing data can be cheap and flexible, but that makes knowing what you have and how it’s being used a real challenge. Data may be stored in a variety of ways, such as JSON or Parquet, and data engineers interact with data differently depending on the job to be done.
They may use Spark for aggregation jobs or Presto for reporting or ad-hoc queries — meaning there are many opportunities for broken or bad data to cause failures. Without a data discovery tool and data lineage, those failures within a data lake can be messy and hard to diagnose.
Within a lake, data can be interacted with in many ways, and a catalog has to be able to provide an understanding of what’s being used and what’s not. When traditional catalogs fall short, we can look to data discovery platforms as a path forward.
The future: data discovery tools and platforms
Data discovery is a new approach rooted in the distributed domain-oriented architecture proposed by Zhamak Deghani and Thoughtworks’ data mesh model. Under this framework, domain-specific data owners are held accountable for their data as products and for facilitating communication between distributed data across domains.
Modern data discovery tools fill voids where traditional data catalogs fell short through five key ways:
1. Data discovery tools automate to scale across your data lake
Using machine learning, data discovery tools automate the tracing of table and field-level lineage, mapping upstream and downstream dependencies. As your data evolves, data discovery tools ensure your understanding of your data and how it’s being used does, too.
2. Data discovery tools provide real-time visibility into data health
Unlike a traditional data catalog, data discovery tools provide real-time visibility into the data’s current state, as opposed to its “cataloged” or ideal state. Since discovery encompasses how your data is being ingested, stored, aggregated, and used by consumers, you can glean insights such as which data sets are outdated and can be deprecated, whether a given data set is production-quality, or when a given table was last updated.
3. Data discovery tools leverage data lineage for understanding the business impact of your data
This flexibility and dynamism make data discovery tools an ideal fit for bringing data lineage to data lakes, allowing you to surface the right information at the right time, and drawing connections between the many possible inputs and outflows. With data lineage, you can resolve issues more quickly when data pipelines do break, since frequently unnoticed issues like schema changes will be detected and related dependencies mapped.
4. Data discovery tools empower self-service discovery across domains
Data discovery tools also enable self-service, allowing teams to easily leverage and understand their data without a dedicated support team. To ensure this data is trustworthy and reliable, teams should also invest in data observability, which uses machine learning and custom rules to provide real-time alerting and monitoring when something does go wrong in your data lake or pipelines downstream. Monte Carlo’s data observability platform combines both data discovery and data observability capabilities.
5. Data discovery tools ensure governance and optimization across the data lake
Modern data discovery tools allow companies to understand not just what data is being used, consumed, stored, and deprecated over the course of its lifecycle, but also how, which is critical for data governance and lends insights that can be used for optimizations across the lake.
From a governance perspective, querying and processing data in the lake often occurs using a variety of tools and technologies (Spark on Databricks for this, Presto on EMR for that, etc.), and as a result, there often isn’t a single, reliable source of truth for reads and writes (like a warehouse provides). A proper data discovery tool can serve as that source of truth.
From an optimization standpoint, data discovery tools can also make it easy for stakeholders to identify the most important data assets (the ones constantly being queried!) as well as those that aren’t used, both of which can provide insights for teams to optimize their pipelines.
Data discovery tools can power distributed discovery for the data lake
As companies continue to ramp up their ingestion, storage, and utilization of data, technology that facilitates greater transparency and discoverability will be key.
Increasingly, some of the best catalogs are layering in distributed, domain-specific discovery, giving teams the visibility required to fully trust and leverage data at all stages of its lifecycle.
Personally, we couldn’t be more excited for what’s to come with data discovery tools. With the right approach, maybe we can finally drop the “data swamp” puns all together?
To stay-up-to-date with all the latest news and trends in building distributed data architectures, be sure to join the Data Mesh Learning Slack channel.
Interested in learning how to scale data discovery across your data lake? Book a time to speak with us using the form below.
Our promise: we will show you the product.
Read more posts.