Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Ready or Not. The Post Modern Data Stack Is Coming.


Barr Moses
CEO and Co-founder, Monte Carlo. Proponent of data reliability and action movies.

Shane Murray
Shane is Field CTO of Monte Carlo. Previously, he served as the SVP of Data & Insights at The New York Times.
If you don’t like change, data engineering is not for you. Little in this space has escaped reinvention.
The most prominent, recent examples are Snowflake and Databricks disrupting the concept of the database and ushering in the modern data stack era.
As part of this movement, Fivetran and dbt fundamentally altered the data pipeline from ETL to ELT. Hightouch interrupted SaaS eating the world in an attempt to shift the center of gravity to the data warehouse. Monte Carlo joined the fray and said, “Maybe having engineers manually code unit tests isn’t the best way to ensure data quality.”
Today, data engineers continue to stomp on hard coded pipelines and on-premises servers as they march up the modern data stack slope of enlightenment. The inevitable consolidation and trough of disillusionment appear at a safe distance on the horizon.
And so it almost seems unfair that new ideas are already springing up to disrupt the disruptors:
- Zero-ETL has data ingestion in its sights
- AI and Large Language Models could transform transformation
- Data product containers are eyeing the table’s thrown as the core building block of data
Are we going to have to rebuild everything (again)? Hell, the body of the Hadoop era isn’t even all that cold.
The answer is, yes of course we will have to rebuild our data systems. Probably several times throughout our careers. The real questions are the why, when, and the how (in that order).
I don’t profess to have all the answers or a crystal ball. But this article will closely examine some of the most prominent near(ish) future ideas that may become part of the post-modern data stack as well as their potential impact on data engineering.
Practicalities and tradeoffs
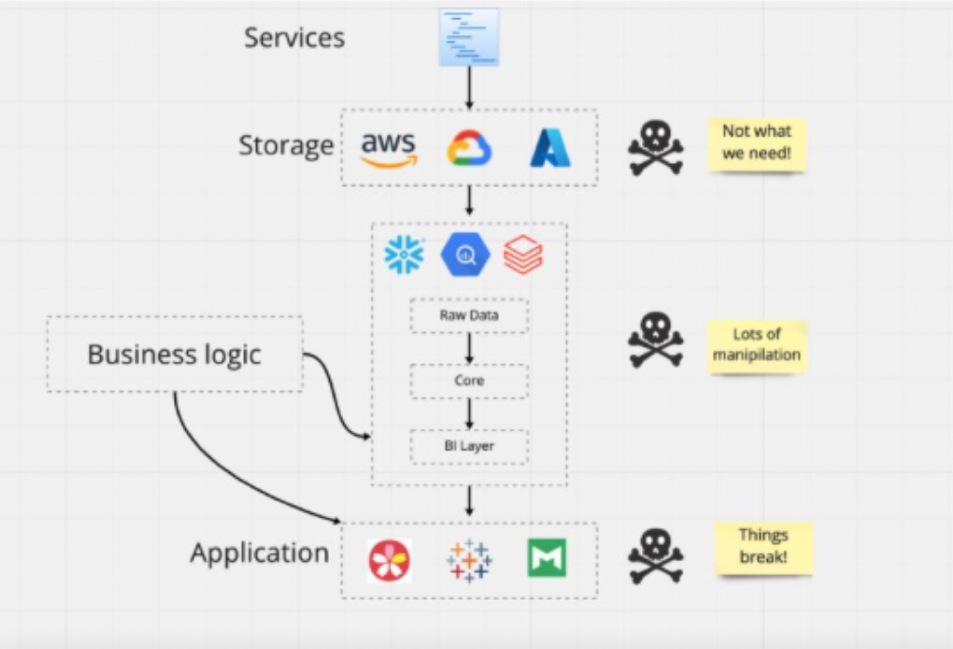
The modern data stack didn’t arise because it did everything better than its predecessor. There are real trade-offs. Data is bigger and faster, but it’s also messier and less governed. The jury is still out on cost efficiency.
The modern data stack reigns supreme because it supports use cases and unlocks value from data in ways that were previously, if not impossible, then certainly very difficult. Machine learning moved from buzz word to revenue generator. Analytics and experimentation can go deeper to support bigger decisions.
The same will be true for each of the trends below. There will be pros and cons, but what will drive adoption is how they, or the dark horse idea we haven’t yet discovered, unlock new ways to leverage data. Let’s look closer at each.
Zero-ETL

What it is: A misnomer for one thing; the data pipeline still exists.
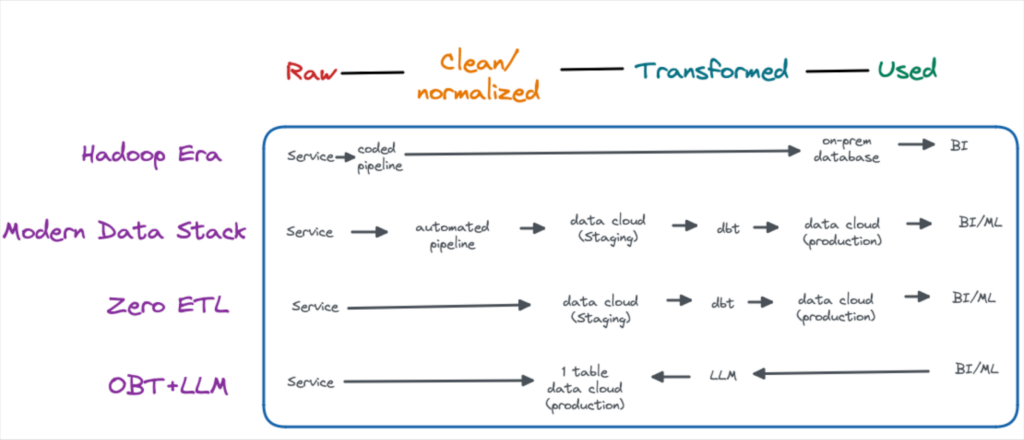
Today, data is often generated by a service and written into a transactional database. An automatic pipeline is deployed which not only moves the raw data to the analytical data warehouse, but modifies it slightly along the way.
For example, APIs will export data in JSON format and the ingestion pipeline will need to not only transport the data but apply light transformation to ensure it is in a table format that can be loaded into the data warehouse. Other common light transformations done within the ingestion phase are data formatting and deduplication.
While you can do heavier transformations by hard coding pipelines in Python, and some have advocated for doing just that to deliver data pre-modeled to the warehouse, most data teams choose not to do so for expediency and visibility/quality reasons.
Zero-ETL changes this ingestion process by having the transactional database do the data cleaning and normalization prior to automatically loading it into the data warehouse. It’s important to note the data is still in a relatively raw state.
At the moment, this tight integration is possible because most zero-ETL architectures require both the transactional database and data warehouse to be from the same cloud provider.
Pros: Reduced latency. No duplicate data storage. One less source for failure.
Cons: Less ability to customize how the data is treated during the ingestion phase. Some vendor lock-in.
Who’s driving it: AWS is the driver behind the buzzword (Aurora to Redshift), but GCP (BigTable to BigQuery) and Snowflake (Unistore) all offer similar capabilities. Snowflake (Secure Data Sharing) and Databricks (Delta Sharing) are also pursuing what they call “no copy data sharing.” This process actually doesn’t involve ETL and instead provides expanded access to the data where it’s stored.
Practicality and value unlock potential: On one hand, with the tech giants behind it and ready to go capabilities, zero-ETL seems like it’s only a matter of time. On the other, I’ve observed data teams decoupling rather than more tightly integrating their operational and analytical databases to prevent unexpected schema changes from crashing the entire operation.
This innovation could further lower the visibility and accountability of software engineers toward the data their services produce. Why should they care about the schema when the data is already on its way to the warehouse shortly after the code is committed?
With data steaming and micro-batch approaches seeming to serve most demands for “real-time” data at the moment, I see the primary business driver for this type of innovation as infrastructure simplification. And while that’s nothing to scoff at, the possibility for no copy data sharing to remove obstacles to lengthy security reviews may result in greater adoption in the long-run (although to be clear it’s not an either/or).
One Big Table and Large Language Models

What it is: Currently, business stakeholders need to express their requirements, metrics, and logic to data professionals who then translate it all into a SQL query and maybe even a dashboard. That process takes time, even when all the data already exists within the data warehouse. Not to mention on the data team’s list of favorite activities, ad-hoc data requests rank somewhere between root canal and documentation.
There is a bevy of startups aiming to take the power of large language models like GPT-4 to automate that process by letting consumers “query” the data in their natural language in a slick interface.
This would radically simplify the self-service analytics process and further democratize data, but it will be difficult to solve beyond basic “metric fetching,” given the complexity of data pipelines for more advanced analytics.
But what if that complexity was simplified by stuffing all the raw data into one big table?
That was the idea put forth by Benn Stancil, one of data’s best and forward thinking writer/founders. No one has imagined the death of the modern data stack more.
As a concept, it’s not that far-fetched. Some data teams already leverage a one big table (OBT) strategy, which has both proponents and detractors.
Leveraging large language models would seem to overcome one of the biggest challenges of using the one big table, which is the difficulty of discovery, pattern recognition, and its complete lack of organization. It’s helpful for humans to have a table of contents and well marked chapters for their story, but AI doesn’t care.
Pros: Perhaps, finally delivering on the promise of self service data analytics. Speed to insights. Enables the data team to spend more time unlocking data value and building, and less time responding to ad-hoc queries.
Cons: Is it too much freedom? Data professionals are familiar with the painful eccentricities of data (time zones! What is an “account?”) to an extent most business stakeholders are not. Do we benefit from having a representational rather than direct data democracy?
Who’s driving it: Super early startups such as Delphi and GetDot.AI. Startups such as Narrator. More established players doing some version of this such as AWS QuickSite, Tableau Ask Data, or ThoughtSpot.
Practicality and value unlock potential: Refreshingly, this is not a technology in search of a use case. The value and efficiencies are evident–but so are the technical challenges. This vision is still being built and will need more time to develop. Perhaps the biggest obstacle to adoption will be the infrastructure disruption required, which will likely be too risky for more established organizations.
Data product containers
What it is: A data table is the building block of data from which data products are built. In fact, many data leaders consider production tables to be their data products. However, for a data table to be treated like a product a lot of functionality needs to be layered on including access management, discovery, and data reliability.
Containerization has been integral to the microservices movement in software engineering. They enhance portability, infrastructure abstraction, and ultimately enable organizations to scale microservices. The data product container concept imagines a similar containerization of the data table.
Data product containers may prove to be an effective mechanism for making data much more reliable and governable, especially if they can better surface information such as the semantic definition, data lineage, and quality metrics associated with the underlying unit of data.
Pros: Data product containers look to be a way to better package and execute on the four data mesh principles (federated governance, data self service, treating data like a product, domain first infrastructure).
Cons: Will this concept make it easier or more difficult for organizations to scale their data products? Another fundamental question, which could be asked of many of these futuristic data trends, is do the byproducts of data pipelines (code, data, metadata) contain value for data teams that is worth preserving?
Who’s driving it: Nextdata, the startup founded by data mesh creator Zhamak Dehgahni. Nexla has been playing in this space as well.
Practicality and value unlock potential: While Nextdata has only recently emerged from stealth and data product containers are still evolving, many data teams have seen proven results from data mesh implementations. The future of the data table will be dependent on the exact shape and execution of these containers.
The endless reimagination of the data lifecycle

To peer into data future, we need to look over our shoulder at data past and present. Data infrastructures are in a constant state of disruption and rebirth (although perhaps we need some more chaos).
What has endured is the general lifecycle of data. It is emitted, it is shaped, it is used, and then it is archived (best to avoid dwelling on our own mortality here). While the underlying infrastructure may change and automations will shift time and attention to the right or left, human data engineers will continue to play a crucial role in extracting value from data for the foreseeable future.
And because humans will continue to be involved, so too will bad data. Even after data pipelines as we know them die and turn to ash, bad data will live on. Isn’t that a cheery thought?
We want to hear from you! Fill out the form below to talk to us about how you are building or re-building your data stack to improve data reliability.
Our promise: we will show you the product.
Read more posts.