Product demo.
Product demo.  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Mission Lane: Continuous Compliance Monitoring


Mike Carpenter
Data strategy and analytics at Mission Lane.
Note: This was originally published on the Mission Lane Tech Blog and has been republished below with permission.
Table of Contents
- Introduction
- Why we started: “Customer obsessed” coupled with cost savings
- A quick introduction to a traditional compliance testing approach
- How manual testing works in practice and its drawbacks
- The future is now! Full population testing
- How the sausage was made: Modern tooling coupled with strategy
- Interested in creating a similar strategy at your org? A few tips to help get you there based on our experience.
Introduction
When something breaks, it stinks. When you don’t know something is broken, that’s even worse.
Car breaks down? Can’t get to work.
Broken finger? Chat GPT prompting doesn’t type itself!
A preventative control in your highly regulated environment breaks and you begin to fall out of compliance for months without knowing? Customers suffer; the worst feeling of all.
In every business, no matter how buttoned up a process may be, things break and it stinks. In the Financial Services industry, numerous laws and regulations are created to ensure that a customer is treated fairly and not caused undue harm by company practices. Because of this, financial service firms like Mission Lane set up extensive compliance monitoring to ensure that operations are executed in alignment with regulatory requirements.
However, many organizations within and external to the Financial Services industry have consistently encountered challenges in leveraging comprehensive and current data when developing monitoring controls designed to validate compliance of their operations in near real-time. This puts the company into a precarious state where if something breaks, it may not be found out until much later, if ever. Both can lead to unforeseen outcomes which unfortunately could include negative customer impact as well as potential regulatory scrutiny.
This article aims to share a newly prototyped testing approach to compliance monitoring at Mission Lane that we’ve developed over the first half of the year. Our approach focuses on full-population, always on testing powered by data and technology. Throughout our implementation, we have observed an improvement in our ability to measure compliance across our operational footprint. This includes shortening the time to discovery of an exception and increasing the precision in which we can identify and quickly resolve potential compliance violations. In doing so, Mission Lane’s implementation of this approach has saved both time and money, all while bringing stronger assurances that our customers are being taken care of in the way we would expect.
Curious to learn more about how this journey started and how we did it? Let’s dive in!
Why we started: “Customer obsessed” coupled with cost savings
At Mission Lane, we have a heavy customer focus in everything we do and identify as being “customer obsessed”. For most organizations, being customer obsessed means focusing on problems that are core to your customers’ needs. Of course, this includes ensuring your operations are working as intended! If you solve for customers’ needs effectively, what was once a business of a few thousand cardholders may quickly blossom into a business of over 2 million in a little more than a few short years. This is exactly the fortunate scenario Mission Lane has found itself in.
However, like any growing business, the balancing act of “customer obsessed” and cost to serve those customers becomes an increasingly important component of operational innovation. Mission Lane needed an approach to compliance testing that was more efficient, effective and also more cost efficient than we had before.
I can hear you saying now: “Lower costs and a better end product? But how?”Well, our approach challenged the old tried and true ways of compliance monitoring by leveraging an innovative Data team and a leading technology stack, coupled with strong partnership from our Compliance leadership team all along the way.
Now, before we get to the new data-driven approach, I feel it is important to give some additional detail to a few specific drawbacks associated with a more traditional compliance testing approach.
A quick introduction to a traditional compliance testing approach
In most organizations, a traditional compliance testing approach would entail taking a sample from a broader population and using that sample to determine if there is a larger, systemic breach of compliance. Depending on the size of the population, this can be a very small percentage of all potential opportunities for non-compliance and may fail in providing a holistic level of coverage for a given compliance risk. With Mission Lane’s customer base in the millions, we saw an opportunity to attempt to test for compliance across all of our customers rather than periodically testing for compliance across a select few to draw a conclusion on the many.
It is important to note I am not saying all sample based testing is less effective than full population testing. However, where there is:
- Data available
- A large population you are looking to test for compliance
- Minimal human judgment required to determine if a compliance breach occurred
…we feel the preferred solution is an automated one. Fortunately for Mission Lane, we had many tests that were being executed manually which perfectly fit this criteria to be prototyped for an automated solution.
With that said, let’s dive into a quick overview of how traditional compliance testing works in practice and some of its drawbacks.
How manual testing works in practice and its drawbacks
For a typical compliance test, the team will select a sample from a population that is in scope for a given risk being tested for. There are many different sampling methods that may be used, including a simple random sample, stratified sample and so on. From this sample, a team member will execute a “test” for compliance.
The test may have one or many different components to it for each sample, each with its own requirement to validate compliance with a given regulation.
For each test completed, regardless of the outcome, additional documentation is required to support the determination of whether an exception occurred. This can be in the form of data, screenshots, or other artifacts that can be used as evidence that compliance was or was not present.
You’re probably thinking what we were thinking; this is a lot of effort for sampling. In our minds, we saw four main drawbacks in this approach which we looked to address in our new solution.
High Level of Effort

First and foremost, the level of effort to execute manual testing is very high. Unlike an automated solution where most of the effort is front-loaded, you have to repeat that high level of effort every time you want to test for compliance. It is a comparatively tedious and continuously demanding approach.
Lack of Scalability

As your customer base grows, sampling for areas of non-compliance quickly gets less and less of the pie. If you try to increase the sample size to cover more of the pie, you also (fairly linearly) need to increase the number of people who are executing the sampling.
A very simple compliance test with a sample of 30 customers that is executed manually could easily take more than a day. Trying to achieve complete coverage for a decent sized customer base just doesn’t work.
Testing is not “always on”
Outside of having a massive compliance testing workforce working 24 hours a day, 365 days a year, who never make mistakes, you are going to be delayed in getting notice that you are out of compliance. For the customer, this means they have a bad customer experience and if a complaint is not raised, it goes unnoticed for some time.
Less Auditable
Lastly, sample based approaches are more likely to be heavily challenged during an audit by a regulator. If you are sampling a small number of customers out of millions, the regulator may logically ask how you created the sample.
“Was it a simple random sample? A stratified sample? Did you shake a fortune crystal ball to determine which accounts to test?”
Sample based approaches generally need to be defended and can be heavily scrutinized depending on the methodology. This takes additional time and effort on top of the manual testing being executed, even if you aren’t attempting to defend the crystal ball approach.
With all of these drawbacks in mind, what did we do?
The future is now! Full population testing
In our approach, we directly solved the four concerns listed above. Our testing strategy:
- Requires less effort — Once the upfront investment in creating the automated solution is complete, there is significantly less ongoing effort required to continuously test for compliance.
- Scales with our customers — Data scales with the customer base but the number of people required to test compliance stays the same. We do this by leveraging a scalable data and technology architecture.
- Is always on — Ready to alert when an exception was detected across all available data in near real time.
- Is easily auditable — No sampling involved and the history of exceptions is maintained in the data warehouse.
How the sausage was made: Modern tooling coupled with strategy
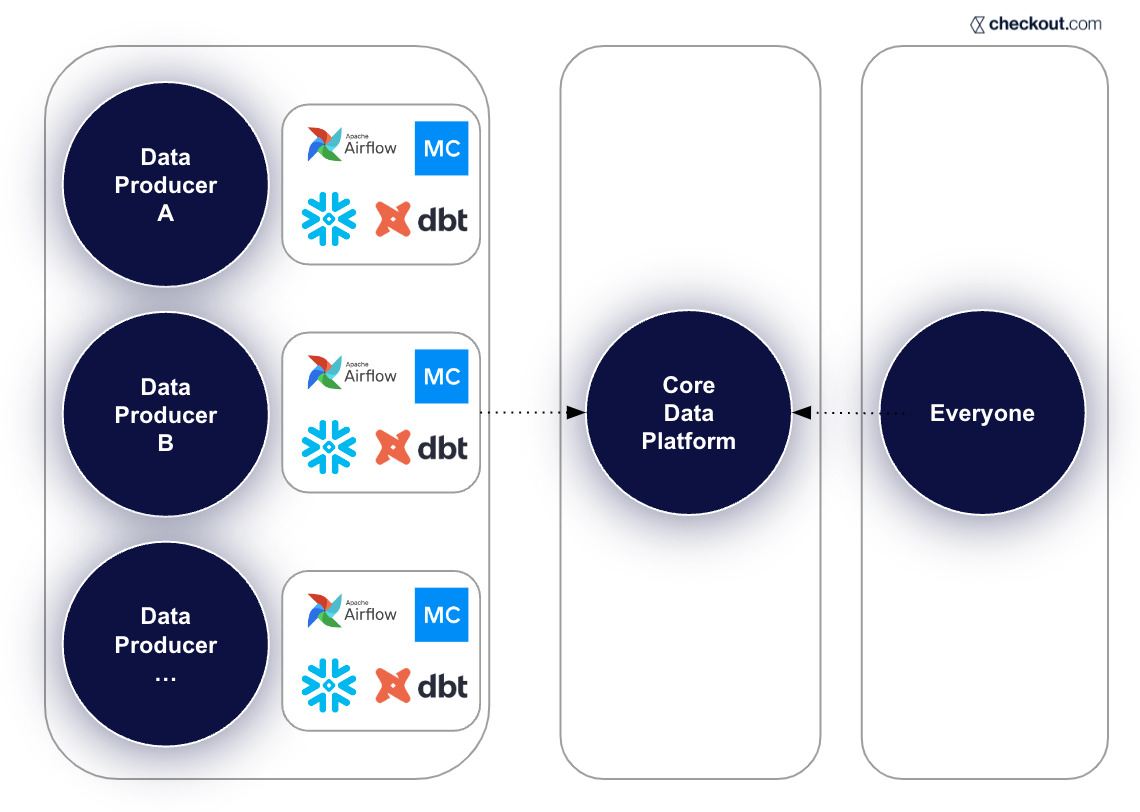
Our data stack at Mission Lane consists of many tools & platforms, but for this project, we leveraged Snowflake (data warehouse), data build tool (dbt) for data transformation, Monte Carlo (data quality and observability tool) and Github (code version control).
All of our analytical data lives within Snowflake. This data, however, was not designed specifically for checking regulatory compliance. Much like data being used for analytics at Mission Lane, we needed to make the data provided easy to use, easily understood, and fit for its purpose. We leveraged dbt to create data structures suitable for detecting exceptions. We also needed this data to be easily accessible to non-sql developers and auditable for both internal and external parties.
With this in mind, we determined that the pipeline must meet the following criteria to fulfill our requirements.
Pipeline Construction:
- All logic for what constitutes an exception should be maintained as code within the dbt pipeline. No additional logic should be needed for an end user to determine an exception once the table is created and available for use in production.
- Determining an exception should be simple for users who know very little SQL. To do this, we created a boolean field (e.g. is_compliance_breach_indicator) for each test. Records with a value of “True” correspond to an exception. This creates a universally accessible layer for all users to query compliance specific data regardless of SQL expertise.
3. Additional, relevant fields supporting the exception flag field should come with the table to help users understand what may have caused the exception and provide initial direction for seeking additional detail. For example, providing the data that feeds into calculating a customer’s APR may be useful in determining which component caused an exception.
4. A date or timestamp field should be added to help determine when an exception took place. This point in time view provides auditability for potential exceptions that we can then use to report on or reproduce.
5. We needed our models to be materialized in two ways:
Current view of data: Shows us what is actively occurring and used to alert on compliance within Monte Carlo.
Point in time view of data: Shows us what was true for the compliance of different tests at a particular point in time. We need to be able to show if a customer account that was not compliant yesterday is now compliant today. This can be used to determine if a customer account has been remediated effectively and also provides historical point in time data for reporting.
6. Compliance data should have the same assurances of quality and timeliness as any other data used by decision makers at Mission Lane. We leveraged Monte Carlo to alert us when data arrives late or the integrity of the data used for testing was compromised.
This sounds like a long list, but the upfront work pays off in creating ongoing trust, auditability and ease of use for continuous compliance monitoring. But, this hard work upfront would quickly be wasted without continuous code review and version control for changes made to our pipeline logic. Let’s briefly cover that prior to heading on to alerting strategies.
Pipeline version control & review:
Our compliance automation pipelines follow the same code review processes as our other production data processes, assuring that changes to the code base are properly reviewed and approved by subject matter experts and a history of changes are maintained. This includes a review of code changes from both a business and technical perspective, ensuring that the pipeline is performant and matches the intent of the compliance testing requestor prior to being used as an authoritative source.
We don’t want anyone accidentally changing the meaning of our code, impacting the accuracy of our measurement for compliance now, do we?
Okay, on to the fun part. Getting the alert.
Alerting for Non — Compliance:
Once the pipeline has been created, reviewed for quality and content, and pushed into production, we then create the Monte Carlo alerts that programmatically tell us when an exception has occurred.
Alerting is a bit of a hot topic. I mean, alerting is easy, right? Bad things happen, it stinks, you want to be alerted quickly, right? Well, that is true, but we think there is more to it.
Our alerts also have a few criteria that must be satisfied:
1. The alert must be immediately actionable and if possible, help determine the swiftness of action needed, along with who is responsible for those actions. This means that the alert should come with the appropriate context to take action and if possible should tell you how quickly to respond.
For us, this means providing documentation (written in plain ole’ English) describing:
- The context behind why the alert was created
- The exception that set off the alert
- The steps to be taken and who is responsible for taking them for root cause analysis, quantification, escalation and remediation of the impact
2. The alert should be delivered to a slack channel (or email address) wheremultiple people can take action. No alert should be sent solely to a single individual. If someone is away or on vacation, other team members should be able to respond given the context provided with the alert as stated above. This example alert is sent to many email addresses AND a slack channel used to alert key stakeholders about the exception.
3. Each alert should come with a pre-defined investigation query that a user can leverage in Monte Carlo simply by pressing “run”. This opens up the interaction with the alert data for non-technical members of your organization.
And there you have it, an automated compliance testing architecture that scales with your business, is always on, and requires minimal human effort to maintain.
Interested in creating a similar strategy at your org?
A few tips to help get you there based on our experience.
- Understand that not all compliance testing can be automated.
Focus on the use cases for which you have clear and measurable criteria, enough data available to test against, and for which manual compliance testing has been especially time consuming in the past. This will give you the biggest lift in the shortest amount of time.
2. Determine your strategy for automated compliance testing before starting.
Our tooling naturally fit into this use case, with components that were already integrated with one another, and allowed for a fairly intuitive first attempt at building out the program. Similar to above, this gives you the biggest lift in the shortest amount of time.
3. Create a strong connective tissue with your compliance team.
Through this program, the data and compliance teams have continued to create and grow a connective tissue, which allowed for both parties to serve as thought partners to each other. Throughout the build, we have put our heads together to identify new use cases and deliver additional incremental value for Mission Lane.
Conclusion
We hope this article gives you some insight (and excitement!) about the possibility of leveraging data to drive your Compliance program forward. Throughout our journey, we have seen significant gains in efficiencies and coverage of our testing through data and automation.
Thanks again for reading!
Interested in learning more about Monte Carlo? Set up time to talk with us below!
Our promise: we will show you the product.
Read more posts.