Product demo.
Product demo.  What is data observability?
What is data observability?  What is a data mesh--and how not to mesh it up
What is a data mesh--and how not to mesh it up  The ULTIMATE Guide To Data Lineage
The ULTIMATE Guide To Data Lineage Scale anomaly detection with machine learning
Don’t let data problems become business problems.























The Monte Carlo difference

Proven ML models with feedback from millions of tables.
End-to-end coverage across your pipelines.
Grouped alerts for related multi-table incidents.
“The business normally doesn’t realize we have issues, because with Monte Carlo we’re detecting them five or six hours before they would impact our platform.”

“Within days the platform was uncovering critical schema and pipeline changes that would have impacted the business if left undetected.”
“ML-based anomaly detection beats manual thresholds basically any day of the week.”
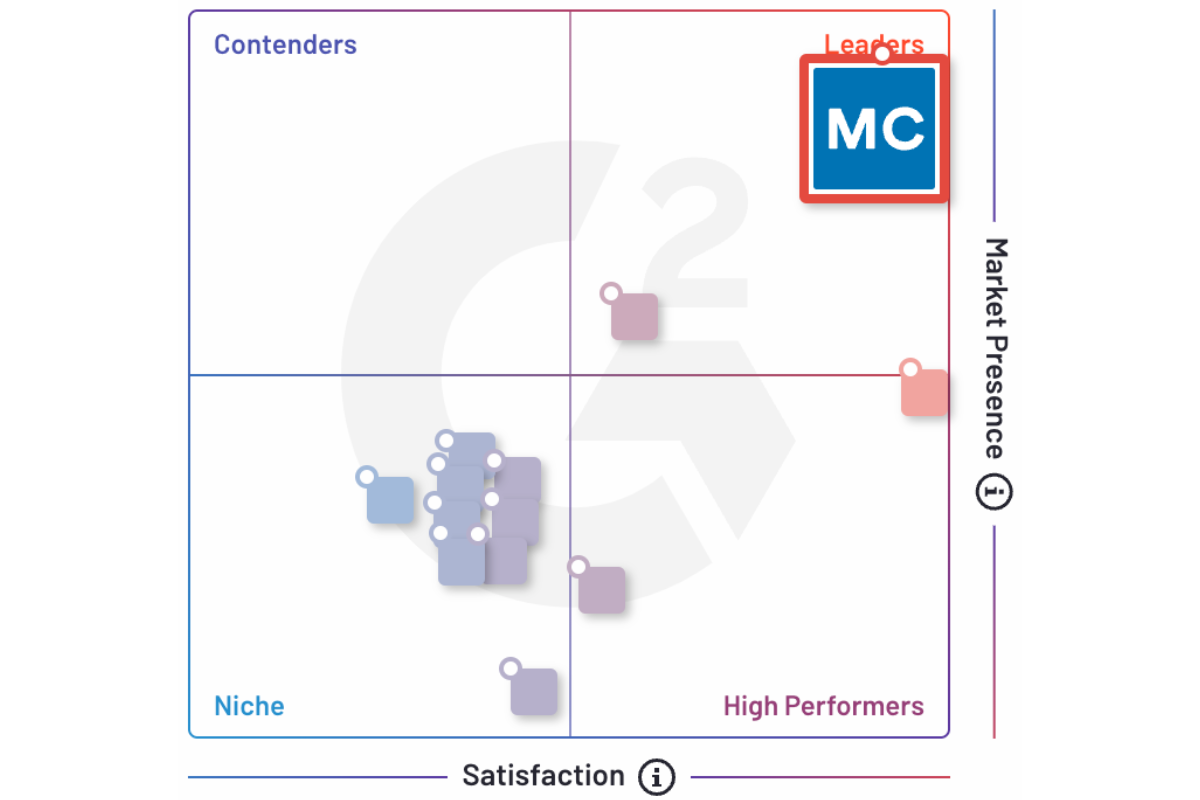
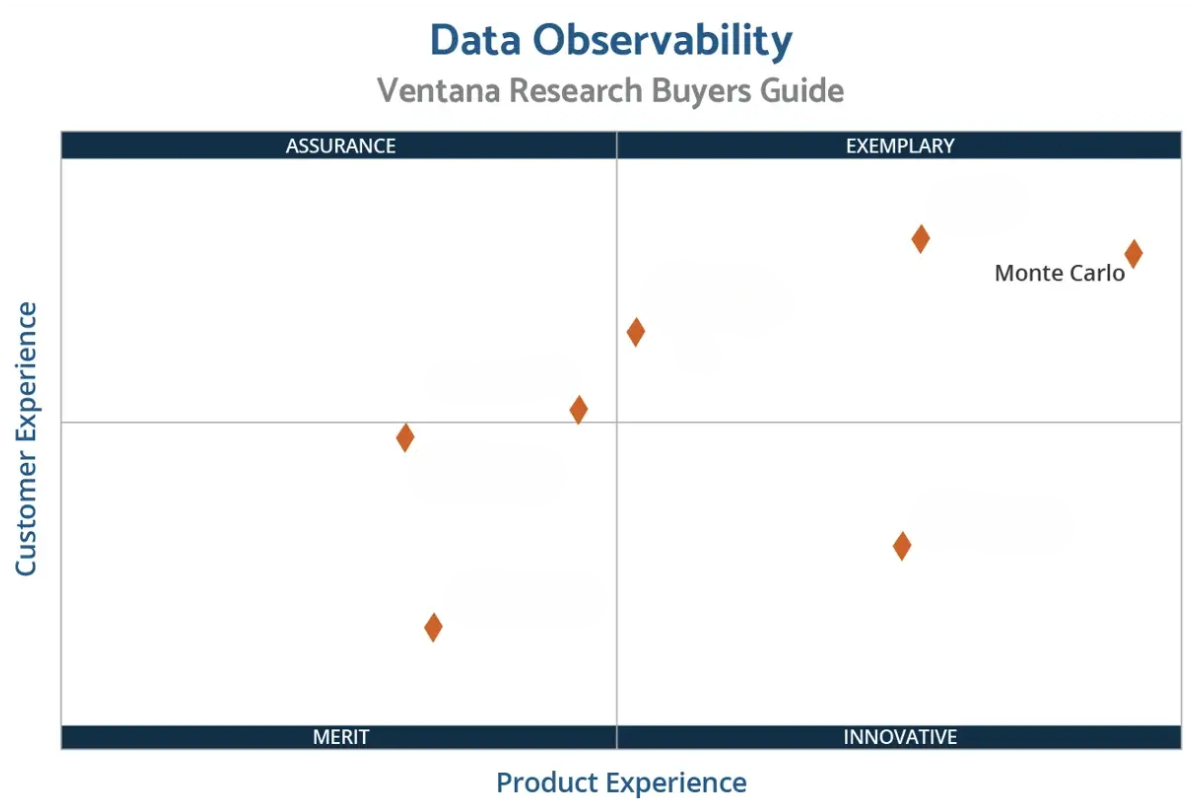
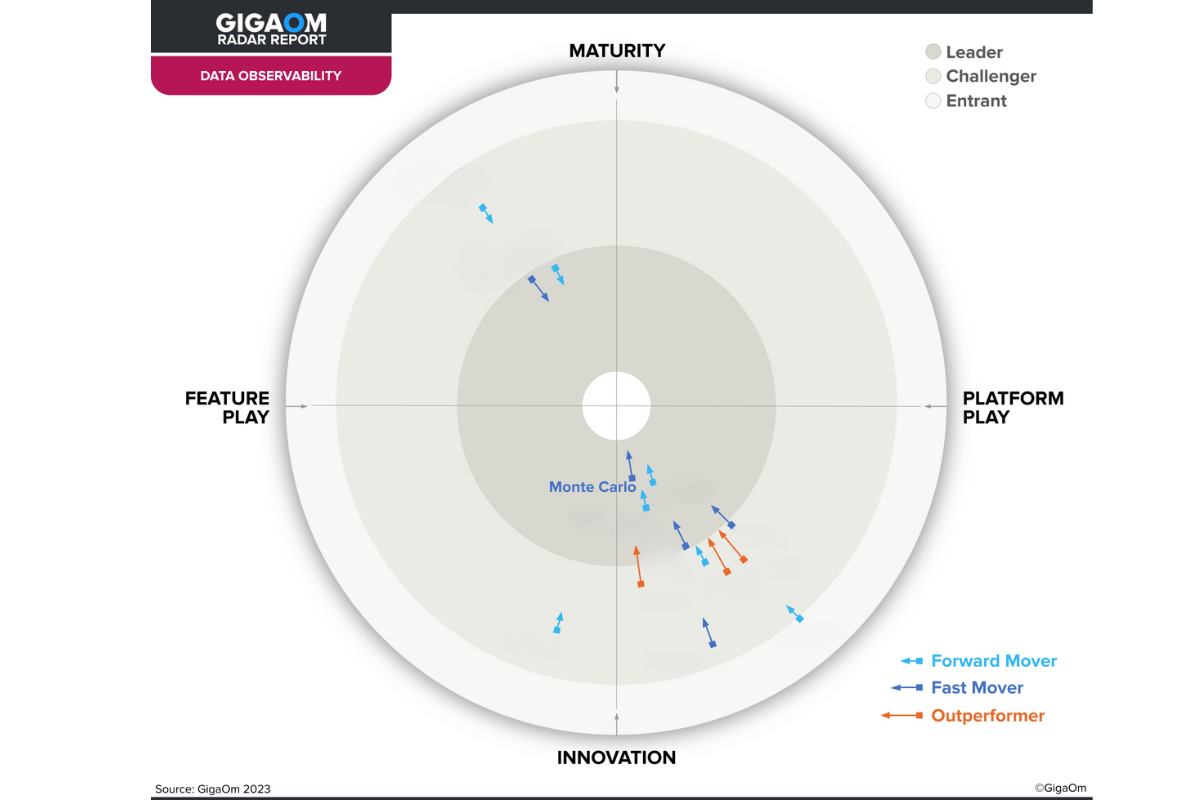
The Undisputed Leader
Automate coverage
Don’t leave reliability to chance. Establish an immediate baseline of coverage upon table creation.
- Freshness monitors for unusual delays in table and field updates
- Volume monitors for unexpected changes to table size based on row count.
- Schema change detection for changes in table or field structure.
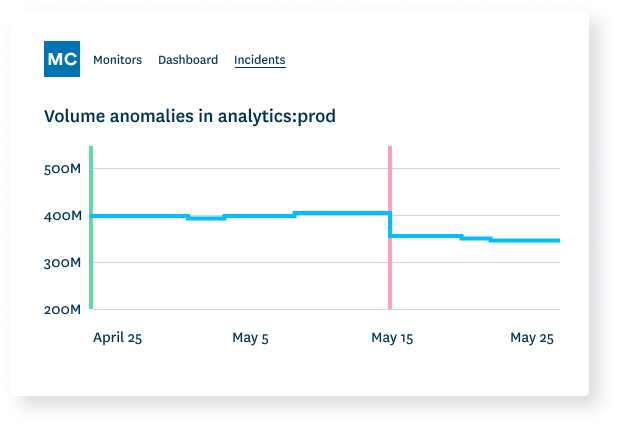
Dive deep
Know what tables, segments, and fields need deep data quality monitors. Deploy in seconds.
- Surface your most important assets automatically with key asset scores.
- Deploy field metric monitors to identify anomalies across +50 data quality metrics.
- Explore data profiles to inform custom rules.
- Leverage no-code templates, SQL, or Gen AI to create custom rules.
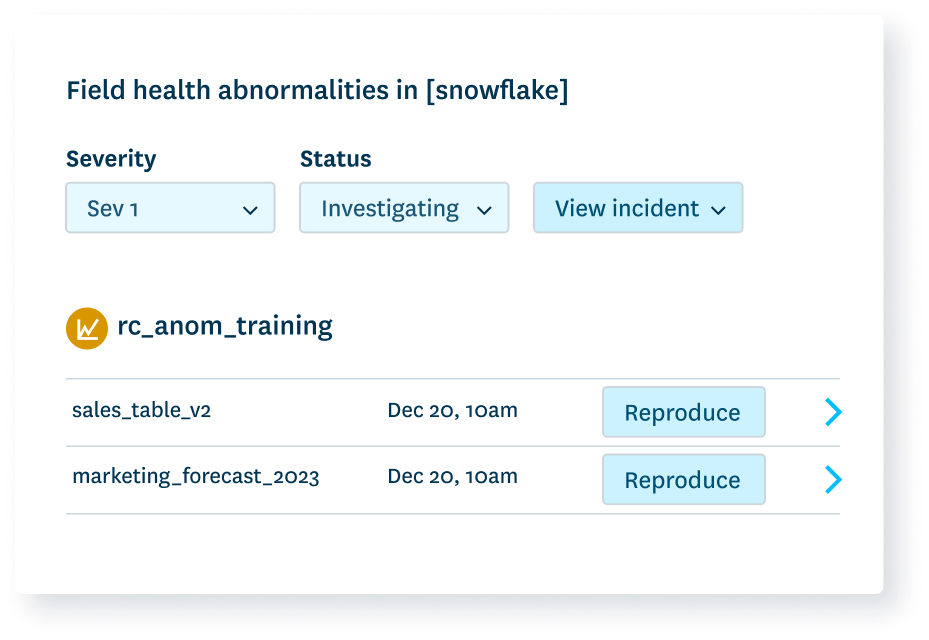
Create consistency
Nothing kills trust like having two values for the same metric.
- Access no-code templates for cross table and cross database monitoring.
- Ensure a field’s contents always have corresponding records in another table.
- Get alerted to unacceptable differences.
- Ensure no data incidents arise from syncing across data systems and repositories.

Avoid alert fatigue
Why get pinged all day when you can intelligently group and surface issues within one-pane of glass? (That was rhetorical).
- Send alerts to your collaboration tool of choice Microsoft Teams, Slack, PagerDuty, and more.
- Automate routing to specific channels based on audiences, domains, table importance, or incident type. Customize messages to “pre-tag” individuals or groups.
- Unify monitoring across your systems from ingestion to consumption.
- Get the full story with lineage-based incident alert grouping.
Deploy effortlessly
The most user and developer friendly data observability solution, bar none.
- Connect your detection, triage, resolution, and measurement workflows within an intuitive UI.
- Deploy monitors during your CI/CD process with the YAML-based configuration option “monitors-as-code.”
Prevent issues
Reduce data downtime by preventing issues from occurring in the first place.
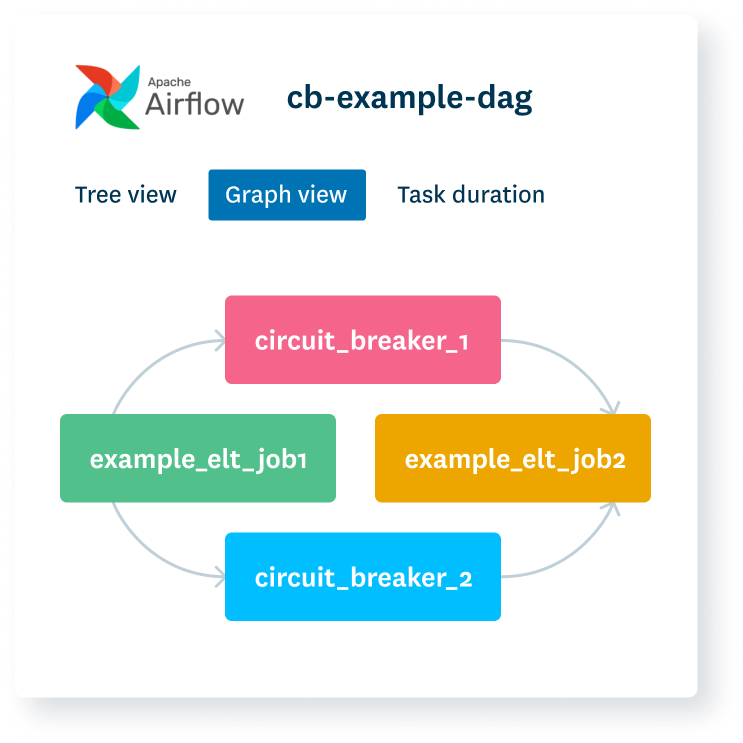
- Stop bad data from landing with circuit breakers.
- Prevent GitHub pull requests that negatively impact assets downstream.
- Detect and remediate long-running queries with the potential to create orchestration issues.